


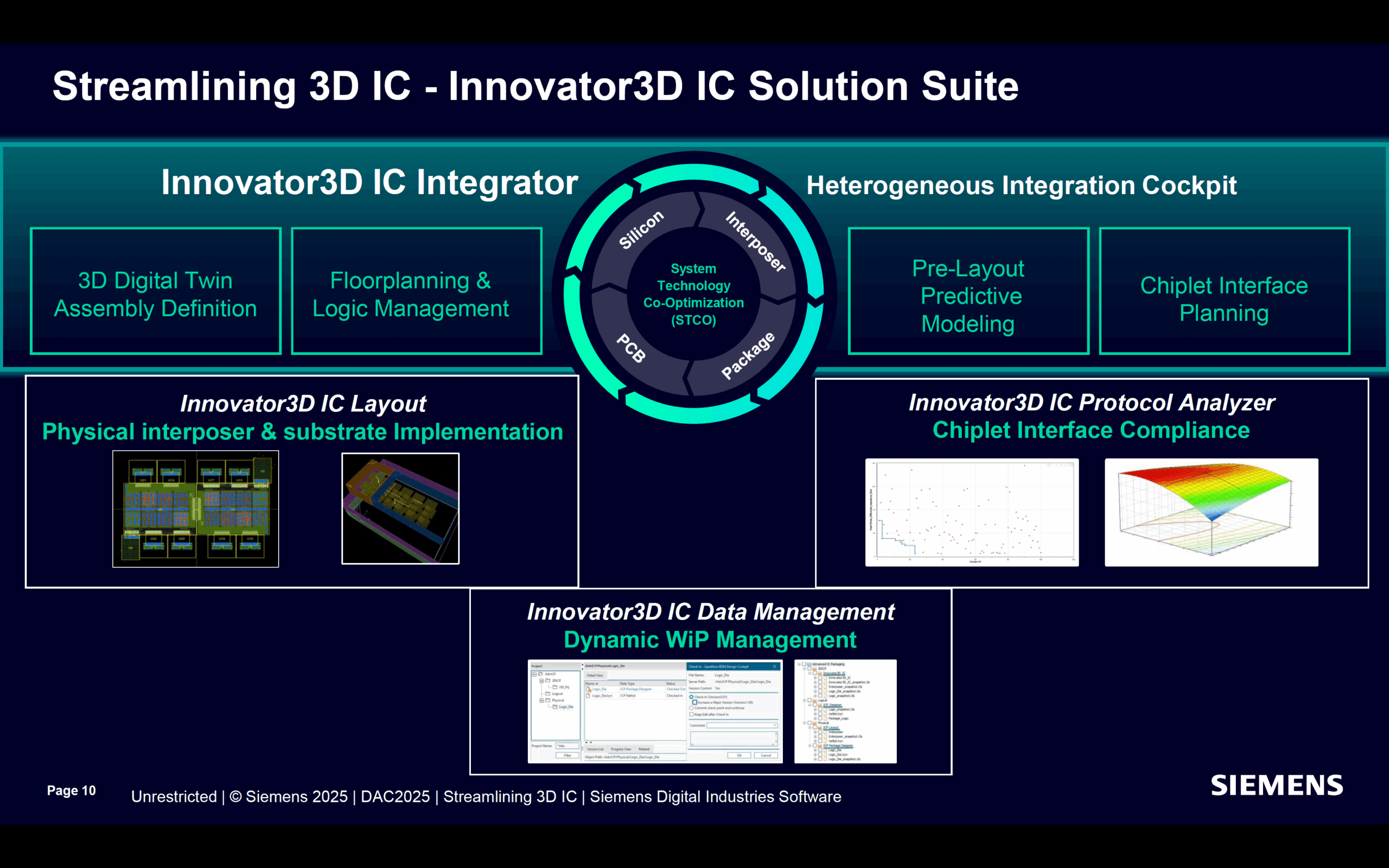


Since power has become a critical factor in semiconductor chip design, the stress is towards decreasing supply voltage to reduce power consumption. However, the threshold voltage to switch devices cannot go down beyond a certain limit and these results in an extremely narrow margin for noise between the two. And that gets further… Read More
A Comprehensive Power Analysis Solution for SoC+Package

Facing the Quantum Nature of EUV Lithography