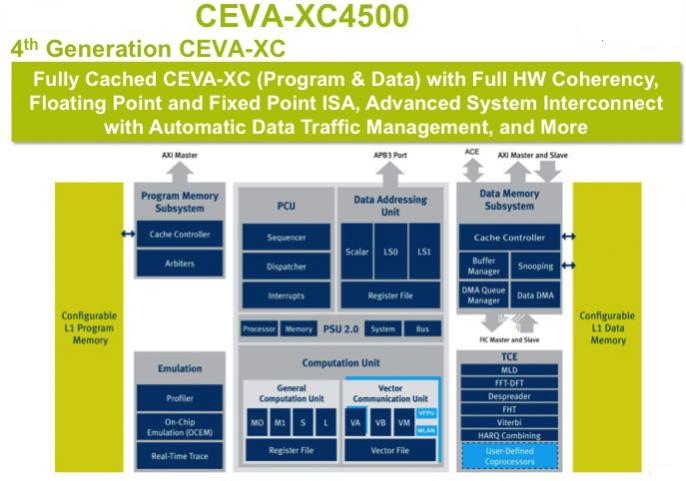

Eyal Bergman of CEVA announced their latest core yesterday at the Linley Microprocessor Conference. It’s their 4th generation CEVA-XC solution, which is the core of their offering for wireless baseband. It builds on 3 previous generations of CEVA-XC’s that were mainly targeted toward handset applications. This one is optimized for the needs of wireless infrastructure, particularly as the shift toward LTE and LTE-A happens. It has already been licensed to one tier-1 vendor.

The new core, the XC-4500 has ultra-high processing capabilities. It runs at 1.3GHz in 28nm. It has a floating point ISA offering over 40 GFLOP. It has dynamic scheduling based on DSP clusters. There is a fully featured data cache which is non-blocking with write-back and write-through.
Since pretty much every chip using a processor core from CEVA also contains an ARM processor, and because a multi-core DSP has to live in the cache coherent world, they have full hardware support for cache-coherency based on ARM’s AMBA-4 ACE technology. This is much better than software coherency (that tends to be very pessimistic flushing whole caches and is hard to program too) and makes partitioning and programming much simpler. Another trick is that the memory can be partitioned into shared and dedicated areas with cache coherency snooping only applied to shared areas, which results in an increase in performance and a decrease in power.
There is also system interconnect with automated traffic management which combines the AMBA AXI4 with proprietary FIC (Fast IC). The automated traffic management allows a single core to work with multiple queues, or resource sharing among multiple cores via a shared queue.
Of course nobody cares about performance without knowing how much power they need to pay for it. Firstly, it can optimize the hardware-software partitioning through having vector DSP and hardware extensions. This can get the power as low as 100mW for 2×2 LTE picocell baseband processing.
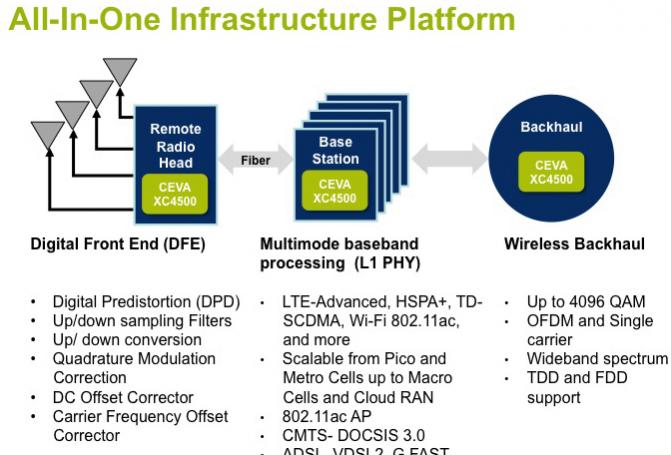
It really is an all-in-one infrastructure platform usable for digital front end in the remote radio head, in the basestation itself for multi-mode baseband processing, and then for wireless backhaul.
There is support for external co-processors for specialized functions:
- Maximum Likelihood MIMO detectors
- 3G De-spreader units
- DFT / FFT
- Viterbi decode
- LLR processing and HARQ combine
- and more, including user supplied co-processors
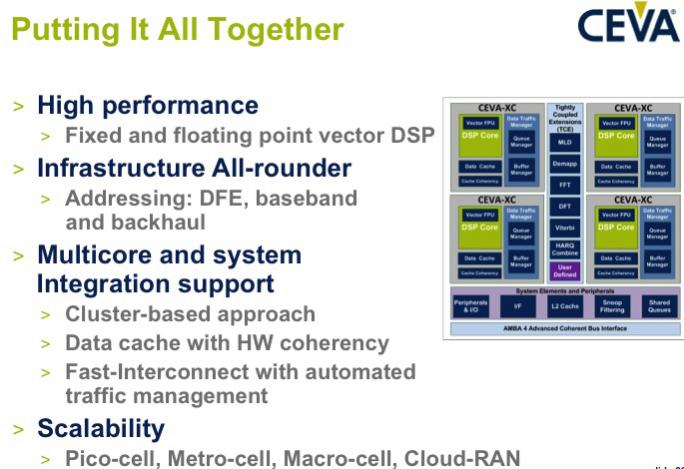
So the architecture is fully scalable all the way from small cells up to macro cells and Cloud-RAN.
More details are on CEVA’s website here.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.