We tend to think of cache primarily as an adjunct to processors to improve performance. Reading and writing main memory (DRAM) is very slow thanks to all the package and board impedance between chips. If you can fetch blocks of contiguous memory from the DRAM to a local on-chip memory, locality of reference in most code ensures much faster access for many subsequent operations which will frequently find the data/addresses they need in these cached copies. This greatly improves overall performance, despite need at times to update cache contents from a different location (and maybe store back in DRAM what must be evicted from the cache).
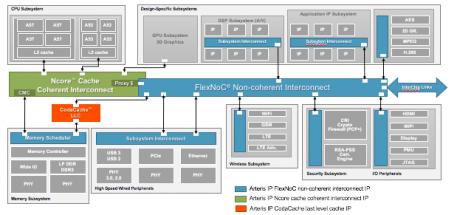
Good ideas generally get pushed harder and so it is with cache; a hierarchy of on-chip caches further reduces the frequency of needed off-chip memory accesses and further increases overall performance. This extends from level-1 (L1), small, fast and really close to the CPU, then L2 all the way up to (potentially) L3, caches at each stage being larger and slower. The last level unsurprisingly is called the last-level cache (LLC) and is generally shared in multi-processor systems. Which is why cache coherency has become a big topic. Caches are a trick to improve performance but must still maintain a common logic view of the off-chip memory space. If you work with Arteris IP, you’ll use their Ncore cache coherent interconnect for communication between IP in the coherent domain to manage that coherency. Ncore also provides proxy caches to synchronize IP in the non-coherent domain with the coherent domain; I wrote about this earlier.
However a lot of logic in an SoC does not sit in the coherent domain; after all, there’s more to an SoC than the CPUs. There’s a human interface (perhaps graphics, audio, voice control), communications, external interfaces, security management, accelerators and sensor interfaces. At least some of these components also need to access memory extensively so can also benefit from cache support. This is the need Arteris IP’s CodaCache aims to support – as a cache function for an individual IPs in the non-coherent world, or as an LLC for the non-coherent system as a whole, or both of these.
Let’s address an obvious question first; these caches are operating in a non-coherent domain, so how do you avoid coherency problems without syncing back into the coherent domain? No magic here – in the same ways you avoid such problems in any context. Address map separation is one choice; each IP writes to and reads from its own address space and there are no overlaps between those spaces.
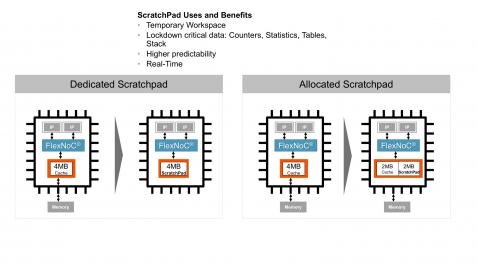
JP Loison, Senior Corporate Application Architect at Arteris IP, told me that the cache is very configurable. It can be used purely as a cache of course, or part of it can be configured (even at runtime) to be used as a scratchpad, or the whole thing can be used as a scratch pad. This is a handy feature for those targeting multiple markets with one device, e.g. low-cost IoT not needing external memory but where you do need fast on-board memory, all the way up to high-performance image processing where you need all the performance advantage of caching. Interestingly, while the cache can sit on the Arteris IP FlexNoC (non-coherent) bus fabric, it doesn’t have to. You can connect it directly to any AXI bus and use it independently of other Arteris IP products.
Another clever thing JP mentioned you could do with CodaCache is partition the cache to alleviate congestion. Rather than having, say, one big 4MB cache block tying up routing resources around that block, you can split the cache into multiple sub-blocks, say 1MB each, which can settle around the floorplan, spreading routing demand more evenly.
JP also mention support for what he called “way partitioning”, a method to reserve cache lines for specific IDs, giving them higher priority and therefore higher performance than for other accesses. For example, one ID could reserve ways 6 and 7 in the cache for high-priority real-time tasks, another could reserve way 5 for medium priority tasks and all other IDs would have to fight it out of the remaining ways. That’s a pretty detailed level of configurability.
You can learn more about CodaCache HERE. The product was released only last month and is now in production. It has been proven already with multiple customer, per JP.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.