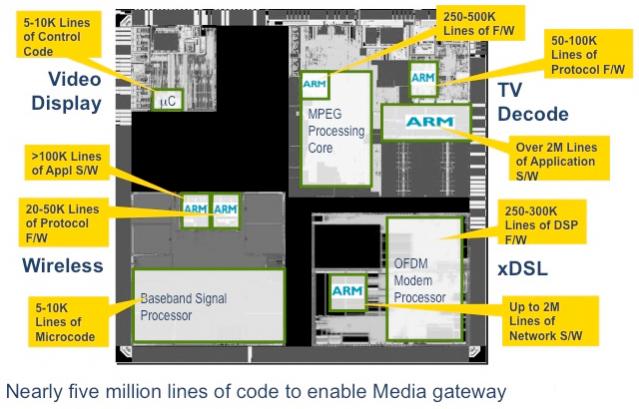


 Mike Hutton of Altera spends most of his time thinking about a couple of process generations out. So a lot of what he worries about is not so much the fine-grained architecture of what they put on silicon, but rather how the user is going to get their system implemented. 2014 is predicted to be the year in which over half of all FPGAs will feature an embedded processor, and at the higher end of Altera and Xilinx’s product lines it is already well over that. Of course SoCs are everywhere, in both regular silicon (Apple, Nvidia, Qualcomm…) and FPGA SoCs from Xilinx, Altera and others.
Mike Hutton of Altera spends most of his time thinking about a couple of process generations out. So a lot of what he worries about is not so much the fine-grained architecture of what they put on silicon, but rather how the user is going to get their system implemented. 2014 is predicted to be the year in which over half of all FPGAs will feature an embedded processor, and at the higher end of Altera and Xilinx’s product lines it is already well over that. Of course SoCs are everywhere, in both regular silicon (Apple, Nvidia, Qualcomm…) and FPGA SoCs from Xilinx, Altera and others.
The challenge is that more and more of systems is software, but the traditional FPGA programming model is hardware: RTL, state-machines, datapaths, arbitration, buffering, highly-parallel. But software guys are not going to learn Verilog and so there is a need for a programming model that represents an FPGA as a processor with hardware accelerators or as a configurable multi-core device. Taking a software-centric view of the world but also being able to build the FPGA so that the entire system meets its performance targets.
There have been many attempts to make C/C++/SystemC compile into gates (Forte,catapult,c2s,synphony,autoesl…) but these really only work well for for-loop type algorithms that can be unrolled, such as FIR filters. They don’t work so well for complex algorithms. What is really needed is to analyze the software to find the bottlenecks and then “automatically” build hardware for doing whatever faster.
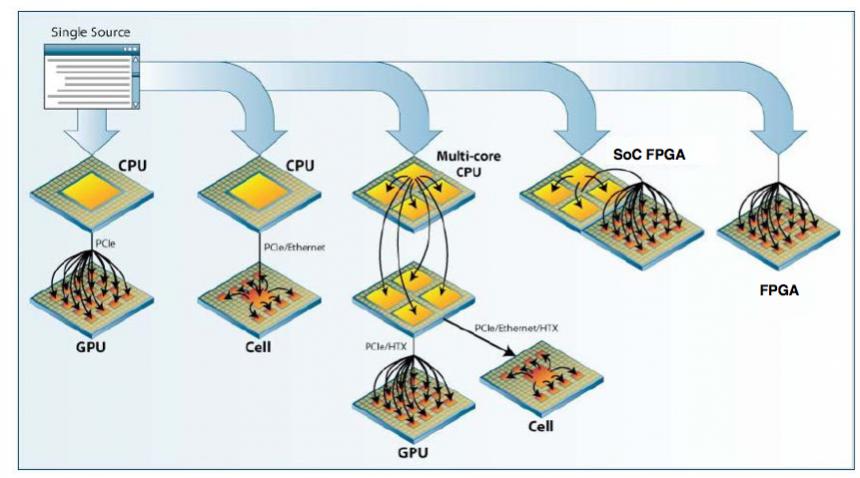 The most promising approach at present seems to be OpenCL, a programming model developed by the Khronos group to support multicore programming and silicon acceleration. From a single source it can map an algorithm onto a CPU and GPU, onto an SoC and an FPGA or just directlly onto an FPGA. There is a natural separation between code that runs on accelerators and the code that manages the accelerators (which can run on any conventional processor).
The most promising approach at present seems to be OpenCL, a programming model developed by the Khronos group to support multicore programming and silicon acceleration. From a single source it can map an algorithm onto a CPU and GPU, onto an SoC and an FPGA or just directlly onto an FPGA. There is a natural separation between code that runs on accelerators and the code that manages the accelerators (which can run on any conventional processor).
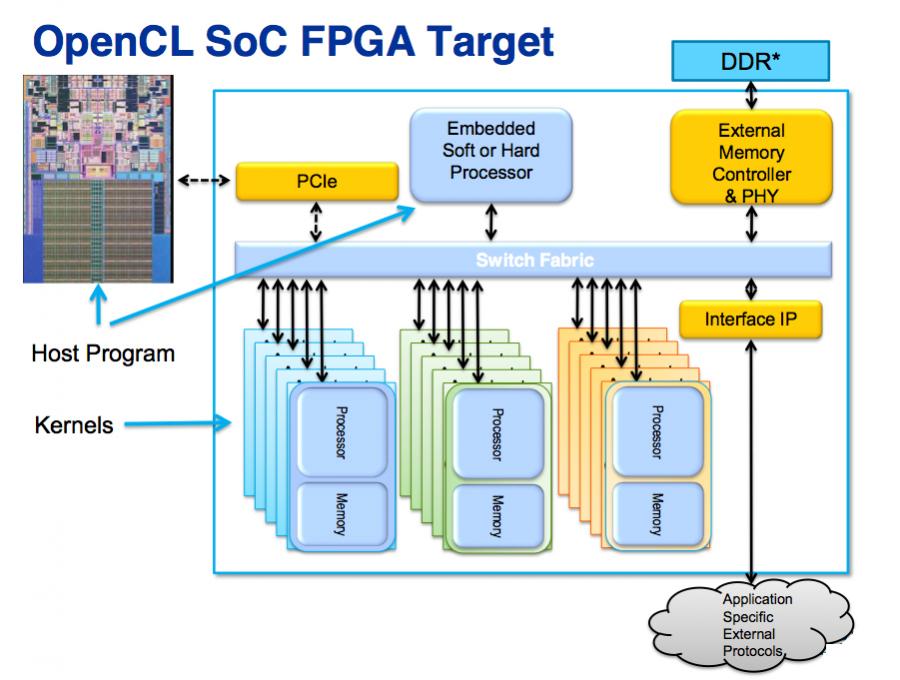 Of course software is going to be the critical path in the schedule if these approaches are not also marged with virtual platform technology so that software development can proceed before hardware is available. Sometimes the software load already exists since software is longer-lived than hardware and may last for 4 or 5 hardware generations. But if it is being created from scratch then it may have a two year schedule, meaning that it is being targeted at a process generation that doesn’t yet have any silicon at all.
Of course software is going to be the critical path in the schedule if these approaches are not also marged with virtual platform technology so that software development can proceed before hardware is available. Sometimes the software load already exists since software is longer-lived than hardware and may last for 4 or 5 hardware generations. But if it is being created from scratch then it may have a two year schedule, meaning that it is being targeted at a process generation that doesn’t yet have any silicon at all.





Why Huawei Says It Will Match TSMC’s Most Advanced Chips by 2031