
At SemiWiki we’ve been blogging for several years now on the semiconductor design challenges of FinFET technology and how it requires new software approaches to help chip designers answer fundamental questions about timing, power, area and design closure. When you mention the phrase Static Timing Analysis (STA) probably the first commercial EDA tool that pops into mind is PrimeTime from Synopsys. I learned more about what’s been recently updated in PrimeTime by talking with Robert Beanland of Synopsys by phone, and we’ve kept in touch over the years since both working at Viewlogic in the 90’s.
Synopsys engineers have focused on three major areas of improvement with the latest release of PrimeTime 2015.12: Performance, Accuracy and Productivity.

Performance
Like most EDA tools there is a never-ending demand from engineers that they see results quickly, like within the same work day instead of waiting multiple days. One way to get faster results from STA is to exploit multiple CPUs, so the Holy Grail is to get linear scalability when going from 1 to 2, 4, 8 and 16 cores. Clever engineers at Synopsys have figured out how to eek out a further 2X overall speedup in PrimeTime by using up to 16 cores with the 2015.12 release. With the latest version, just comparing 1 core to 16 cores you can expect a speed improvement of 10-15X, pretty close to the ideal speedup.
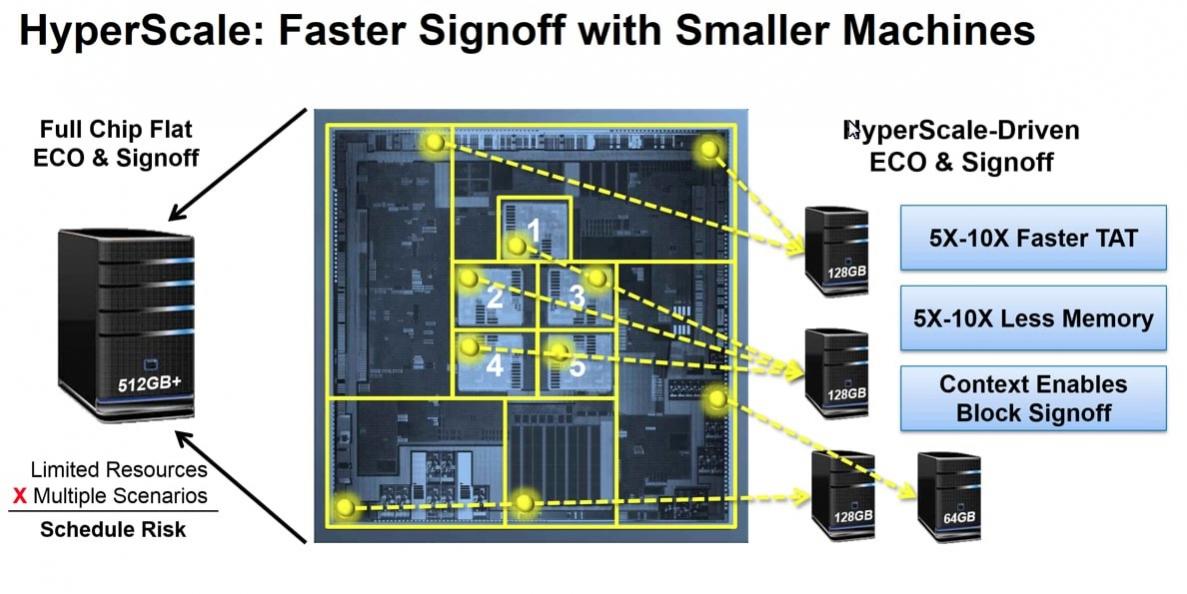
Another important performance metric is RAM usage with EDA tools, because running a flat STA design on a big SOC (designs in the range of 1 billion transistors) can consume 1T of RAM. A technique called HyperScale allows for less RAM usage, something quite helpful for large designs because HyperScale supports partitioning of your design into smaller pieces and distributing them across multiple smaller machines.
Accuracy
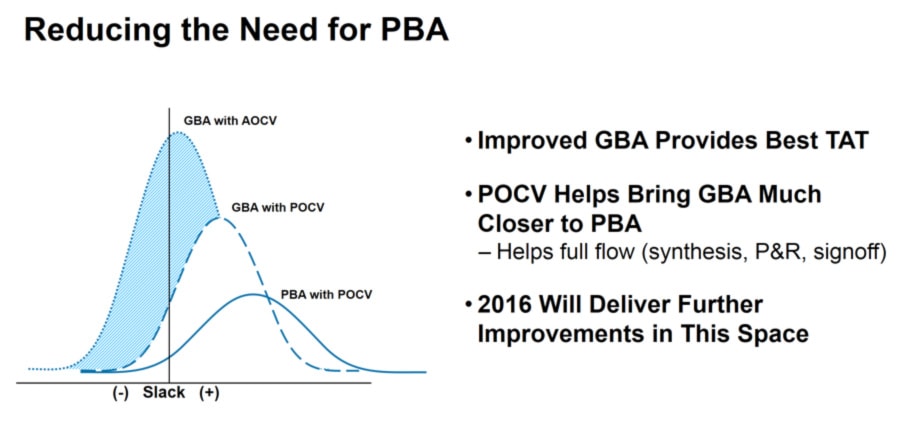
Faster timing results are great, but only if it means that the accuracy is acceptable. With STA tools there have been a couple of approaches used: Graph-based Analysis (GBA) and Path-based Analysis (PBA). GBA produces full coverage results across the entire timing graph with some pessimism. PBA is more accurate, but it runs on a path by path basis requiring longer run times. From a methodology viewpoint you typically start out running STA with a GBA approach to get results quickest, then near the end of your project use PBA to get highest accuracy on critical timing paths. With the 2015.12 release the accuracy of GBA has been updated by improving its accuracy using Parametric On-Chip-Variation, getting timing results even closer to PBA and ultimately, HSPICE results.

Productivity
Engineers are constantly being given changes to the spec in terms of features and requirements, which lead to the practice of Engineering Change Orders (ECOs). As designs get close to tapeout, one key to managing the tapeout schedule is to tightly control any changes that are introduced to the design and only permit changes which move the design closer to meeting PPA (Power, Performance, Area) targets. Achieving the lowest possible power use can drive ECO changes right up until tapeout. In the area of power ECO capabilities for 14nm FinFET I was impressed to see that Samsung was able to get a 20% total power reduction using signoff timing to reduce power. This release also supports downsizing where cells with smaller transistors replace initial cells, plus techniques like Vth swapping. HiSilicon reported that on a recent 16nm FinFET tapeout, PrimeTime provided fast, accurate and predictable design closure helping them reach performance and power targets.
Summary
There’s plenty of challenges in designing SoCs with FinFET technology, and for users of STA tools like PrimeTime you can benefit from using the latest release to help meet those challenges with improved performance, accuracy and productivity. Even early designs for 10nm FinFET will benefit from support for the new and complex placement rules that work together between PrimeTimeand IC Compiler.
Related Blogs
- Custom Layout Productivity Gets a Boost
- IoT or Smart Everything
- Analog Mixed-Signal Layout in a FinFET World




Comments
0 Replies to “Static Timing Analysis Keeps Pace with FinFET”
You must register or log in to view/post comments.