


While I usually talk about AI inference on edge devices, for ADAS or the IoT, in this blog I want to talk about inference in the cloud or an on-premises datacenter (I’ll use “cloud” below as a shorthand to cover both possibilities). Inference throughput in the cloud is much higher today than at the edge. Think about support in financial services for fraud detection, or recommender systems for e-commerce and streaming services. Or the hot topic of our time – natural language systems driving chatbots and intelligent virtual assistants, such as ChatGPT. We know that inference, like training, runs on specialized systems: deep learning accelerators (DLAs), built on GPUs, DSPs or other custom hardware based on ASICs or FPGAs. Now we need that capability to serve very high demand, from banks, streaming services, chatbots and many other applications. But current cloud infrastructure is not ready.

Why is Cloud Inference not Ready?
There are already multiple DLA technologies in production use, each offering different strengths. How does a cloud provider simplify user access to a selection of options? DLAs aren’t conventional computers, ready to just plug into a cloud network. They need special care and feeding to maximize throughput and value, and to minimize cost and complexity in user experience. Cloud clients also don’t want to staff expert teams in the arcane details of managing DLA technologies. Providers must hide that complexity behind dedicated front-end servers to manage the interface to those devices.
Scalability is a very important consideration. Big training tasks run on big AI hardware. Multiple training tasks can be serialized, or the provider can add more hardware if there is enough demand and clients are willing to factor the training costs into their R&D budgets. That reasoning doesn’t work for high volume, high throughput inferencing. Inference based on technologies like ChatGPT is aimed at high demand, low margin services, accounted for in client cost of sales. Training supercomputers can’t meet that need given their high capital and operating costs. Supercomputers are not an affordable starting point for inference clients.
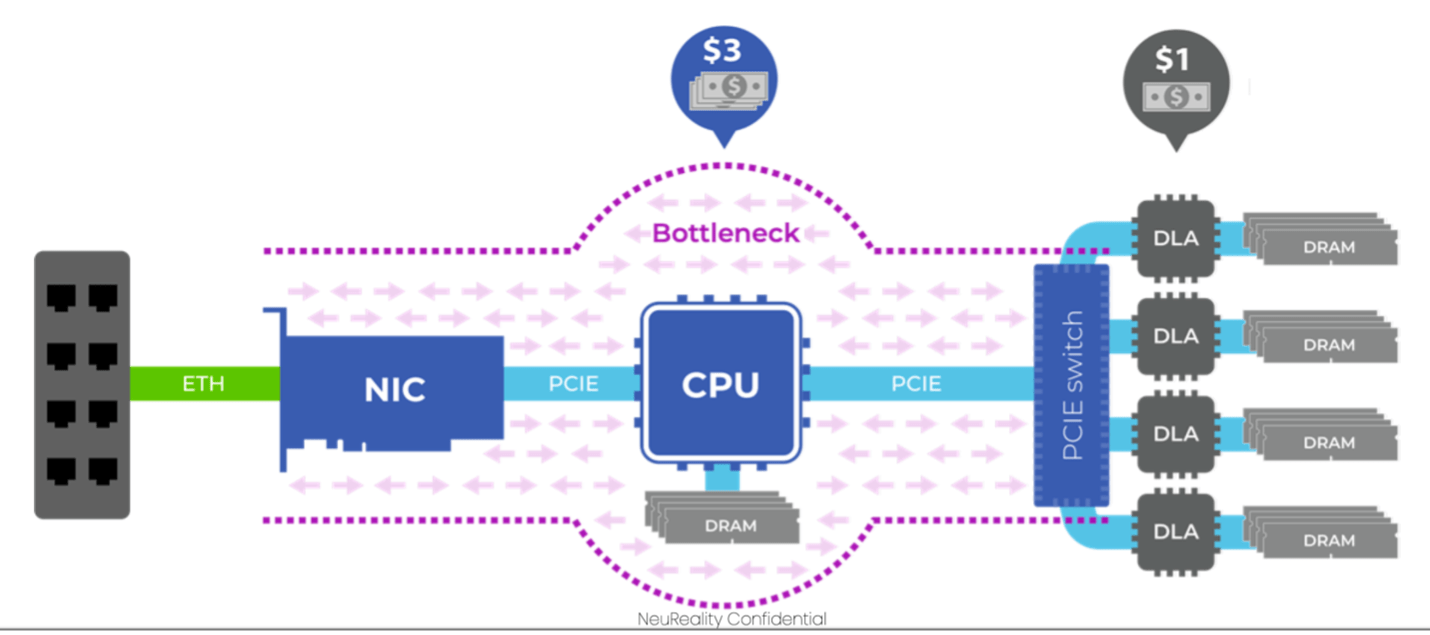
High volume demand for general software is handled by virtualization on multi-core CPUs. Jobs are queued and served in parallel to the capacity of the system. Cloud providers like AWS now offer a similar capability for access to resources such as GPUs. You can schedule a virtual GPU, managed through a conventional server offering virtualization to multiple GPUs. Here we’re talking about using these virtual GPUs as DLAs so the server must run a big stack of software to handle all complexities of interfacing between the cloud and the inference back-end. This CPU-based server solution works but also proves expensive to scale.
Why CPU-Based Servers Don’t Scale for Inference
Think about the steps a CPU-based server must run to provide inference as-a-service. A remote client will initiate a request. The server must add that job to the queue and schedule the corresponding task for the next available virtual machine, all managed through a hypervisor.
When a task starts the virtual machine will first download a trained model because each new task needs a different trained model. A target DLA will be selected; the model will then be mapped to the appropriate DLA command primitives. Some of these will be supported directly by the accelerator, some may need to be mapped to software library functions. That translated model is then downloaded onto the DLA.
Next, large data files or streaming data – images, audio data or text – must be pipelined through to drive inferencing. Image and audio data often must be pre-processed through appropriate codecs. Further, DLAs have finite capacity so pipelining is essential to feed data through in digestible chunks. Results produced by the DLA will commonly require post-processing to stitch together a finished inference per frame, audio segment or text block.
Production software stacks to serve inferencing are very capable but demand a lot of software activity per task to initiate and feed a DLA, and to feed results back. The overhead per virtual machine per task is high and will become higher still under heavy loads. Worse yet inferencing traffic is expected to be high throughput with low turn-around time times from request to result. High demand puts higher loads on shared services, such as the hypervisor, which becomes visible in progressively slower response times as more tasks are pushed through.
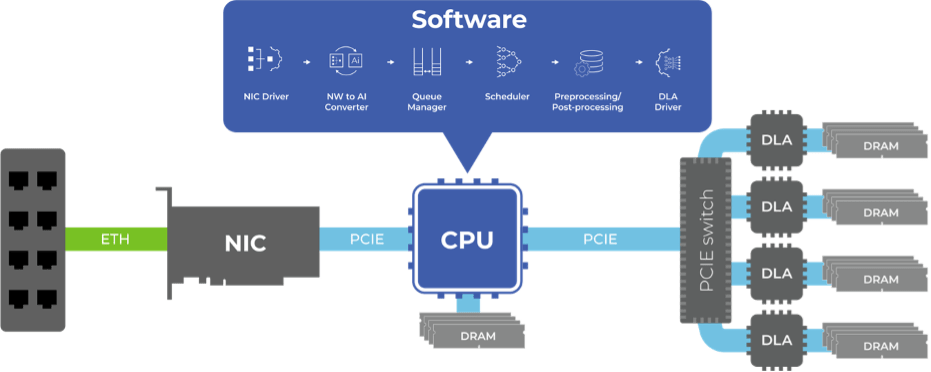
An Architecture for a Dedicated AI Inference Server
A truly competitive alternative to a general-purpose server solution must offer significantly higher throughput/lower latency, lower power, and lower cost, through the path from network interface to the sequencing function, codecs and offload to AI engines. We know how to do that – convert from a largely software centric implementation to a much more hardware centric implementation. Function for function, hardware runs faster and can parallelize much more than software. A dedicated hardware-based server should be higher throughput, more responsive, lower power and lower cost than a CPU-based server.
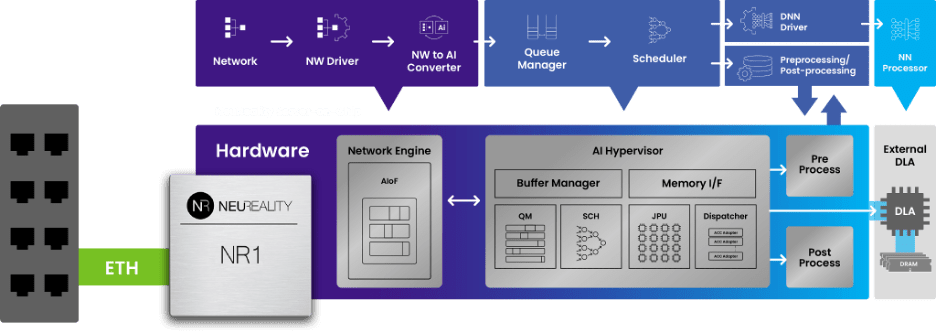
NeuReality, a startup based in Israel, has developed such an AI server-on-a-chip solution, realized in their NR1 network-attached processing unit (NAPU). This hosts a network interface, an AI-hypervisor handling the sequencing, hardware-based queue management, scheduling, dispatching, and pre- and post-processing, all through embedded heterogeneous compute engines. These couple to a PCIe root-complex (host) with 16-lane support to DLA endpoints. The NAPU comes with a full hardware-accelerated software stack: to execute the inference model on a DLA, for media processing and to interface to the larger datacenter environment. The NR1-M module is made available in multiple form-factors, including a full-height single width and full-height double-width PCIe card containing a NR1 NAPU system-on-chip connecting to a DLA. NR1-S provides a rack-mount system hosting 10 NR1-M cards and 10 DLA slots to provide disaggregated AI service at scale.
NeuReality has measured performance for NR1, with IBM Research guidance, for a variety of natural language processing applications: online chatbots with intent detection, offline sentiment analysis in documents, and online extractive Q&A. Tests were run under realistic heavy demand loads requiring fast model switching, comparing CPU-centric platforms with NR-based platforms. They have measured 10X better performance/$ and 10X better performance/Watt than comparable CPU-server-based solutions, directly lowering CAPEX and OPEX for the cloud provider and therefore increasing affordability for client inference services.
These are the kind of performance improvements we need to see to make inference as a service scalable. There’s a lot more to share, but this short review should give you a taste of what NeuReality has to offer. They already have partnerships with IBM, AMD, Lenovo, Arm, and Samsung. Even more impressive, they only recently closed their series A round! Definitely a company to watch.
Share this post via:



Consolidation and Competition: Who is Winning the $4.5 Billion Interface IP Race?