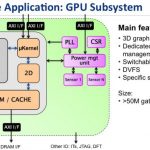
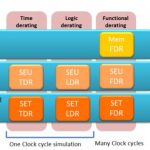
Carbon Design drives a lot of traffic to SemiWiki. Actually, it’s ARM driving traffic to the Carbon landing page since Carbon and ARM work closely together. When we blog about designing with ARM IP droves of people click over. Seriously, DROVES of people. Rick Lucier has deep EDA experience and has led Carbon as CEO for the past seven years so you are going to want to read this one:
Q: What are the specific design challenges your customers are facing?
Carbon’s 50+ customers are primarily concerned with accelerating the development of advanced SoCs containing ARM processors. As part of this we see them facing the following challenges:
[LIST=1]
As with all EDA vendors the goal is to identify current and future bottlenecks and provide a solution to remove them thus shortening the design cycle.
Q: What does your company do?
Carbon provides customers the ability to quickly assemble virtual prototypes that remove the traditional tradeoff between accuracy and performance. This saves months off the SoC design cycle and ensures that software will run on silicon the first day it shows up in the lab.
Q: Why did you join your company?
I have spent over 25 years in EDA before joining Carbon and have witnessed the challenges EDA companies have had in addressing the software bottleneck facing design teams. Carbon had an interesting approach in solving that problem which was very attractive – not a pure EDA company, but not a pure IP company. This approach continues to mature and with the combination of our tools, partners and business model will make virtual prototyping the norm and augment traditional hardware assisted simulation solutions in addressing the software bottleneck. I believe this approach will have a significant impact on EDA.
Q: How does your company help with your customers’ design challenges?
Our customers use our products to meet the following design challenges:
[LIST=1]
Q: What are the tool flows your customers are using?
For architectural analysis the old traditional spreadsheet approach is thing of the past given today’s complexity. To address this need there is a mix of internal tools and commercially available tools such as Carbon. For customer’s that require precision (100% accuracy) Carbon is the solution of choice. For firmware development often times FPGA prototypes and emulation are used but we see a strong movement towards virtual prototypes since the platform can be delivered earlier and to a larger audience in a cost effective manner. The requirement is to have accuracy and performance which is unique to Carbon’s solution.
Q: What will are you focusing on at the Design Automation Conference this year?
At this year’s DAC we will be focusing on our solutions around the new ARM A57 processor.
Q: Where can SemiWiki readers get more information?
More information on Carbon’s solutions can be found at www.carbondesignsystems.com, www.carbonipexhange.com and by subscribing to our blog at http://www.carbondesignsystems.com/virtual-prototype-blog/
Carbon Design Systems offers the industry’s only unified virtual prototype solution along with the leading solution for accurate IP model creation. Carbon virtual prototypes can execute at hundreds of MIPS and with 100% accuracy to enable application software development, detailed architectural analysis and secure IP model distribution. Carbon’s customers are systems, semiconductor, and IP companies that focus on wireless, networking, and consumer electronics. Carbon investors include Samsung Venture Investment Corporation and ARM Holdings. Carbon is headquartered at 125 Nagog Park, Acton, Mass., 01720. Telephone: (978) 264-7300. Facsimile: (978) 264-9990. Email: info@carbondesignsystems.com. Website: www.carbondesignsystems.com.
lang: en_US