Round #1 was here.
In the EUV corner were Stefan Wurm of Sematech (working on mask issues mostly) and Skip Miller of ASML who are the only company making EUV steppers (and light sources, they acquired Cymer).
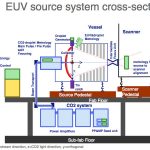
You may know that the biggest issue in EUV is getting the source brightness to have high enough energy that an EUV stepper has a throughput of at least 120 wafers per hour so that it is competitive with multiple patterning. And the source is like something out of science-fiction. First, you make little tiny droplets of molten tin. Then you hit them with a laser to shape the drop. Then you hit it with a really big laser, so big that it needs a whole power infrastructure in the sub-fab, and this vaporizes the tin droplet to plasma. With a 20KW laser with a power efficiency of 10% you need 0.2GW of input power. The plasma lets out a little bit of EUV. Oh, and do that about 100M times per hour.
But EUV is absorbed by everything so you can’t use normal (transmissive) masks and the stepper has to have a high vacuum (because even air absorbs EUV). But you can’t use conventional mirrors like you have in your bathroom. They absorb EUV too. You need to build masks out of multiple layers of silicon and molybdenum to form a mask that reflects due to interlayer interference. But they still don’t reflect very well, about 30%, so after a couple of mirrors to focus the EUV light, and 6 more to direct it, and a reflective mask, 96% of the light is absorbed and only 4% hits the wafer.
So with that background, are we there yet?
Stefan started of pointing out that he is working on the assumption that the light source issue is solved. He can’t do anything about it at Sematech but waiting for it to be solved before looking at the other problems is clearly silly.
First the good news. EUV resists seem to be in good shape, first production-type EUV tools are being delivered, masks blanks are being made, there is some experience with pilot runs. Line width roughness (lwr) and CD uniformity (cdu) are getting better but so far only by accepting slower resists.
Mask blanks are still a big issue. We would like defect free masks but that is not really going to happen and here is why. As I said above, the masks are mirrors built up by depositing layers of silicon and molybdenum onto a glass blank using ion beam deposition (IBD). A big problem is that defects on the glass that are too small to see get amplified by this process and become real defects that affect the mask and then you can see (but then it is too late). Best masks are about 12 defects at 45nm. Those 12 break down into 10 pits from substrate (that were too small to see before you started deposition), one handling defect and one from deposition. Marathon runs of IBD of 100 blanks get 20-30% yield of acceptable masks. There are some long-term issues, IBD may not be viable long-term as process feature sizes continue to shrink.
Another issue is the EUV masks don’t have a cover on them (known as a pellicle) because that cover would absorb the EUV. So any defect on the mask is in the focal plane. There is an assumption in developing EUV that there is no contamination in the chamber, but of course that is not completely realistic. To me this is a huge issue, and one we don’t have with optical masks that have a pellicle to keep contamination out of the focal plane. So masks need to be cleaned regularly. But there are starting to be degradation of the patterns after 50-100 cleanings.
There is some work on pellicles with materials that are transparent(ish) to EUV. The most promising material seems to be single crystal silicon.
Takeaway:
- IBD can produce usable mask blanks but may not be viable long-term
- Substrate quality is an issue, hampered by lack of defect metrology
- Need to ensure adders (particles that get on the mask after it was made) do not print
- Mask lifetime learning has just begun (backside coating damage, clean handling)
- EUV mask supply chain is a weak link. Will not be ready at quality and volume needed for HVM ramp and so industry needs to strengthen mask supply ecosystem.
Next was Skip from ASML. Cost is a big concern in the whole industry. In 2000 1GB would set you back $1182 in lithography costs, but by 2015 it should be about $0.17. But post-28nm cost is flat per transistor. Only EUV can give a full scaling for 10nm node due to litho/layout restriction with multiple patterning. EUV also has 30-75% reduced cycle time. They have 11 systems in various stages of construction in their clean room.
Currently source is generating 55W of power which is 43wph. They expect 80W and 60wph by the end of the year. EUV production is expected for 10nm logic and 1xnm DRAM volume production in 2015-2016.
My opinion. I understand the need for EUV to keep Moore’s law on track especially without having insanely high costs and insanely long tunround time. But I still don’t see how everything can be made to work in time. Intel is already planning 10nm without it. The pellicle issue I have always considered a killer but perhaps a silicon pellicle can be made to work. This meeting was the first time I’d heard the hint of possibility of an EUV-transparent pellicle. The fact that masks will not be defect free seems like a big issue. So much is being invested in the light source that I can believe that will be solved. But the almost laser-like focus (see what I did there) on that one issue has obscured many other issues that stand between EUV and use in high volume production lithography.