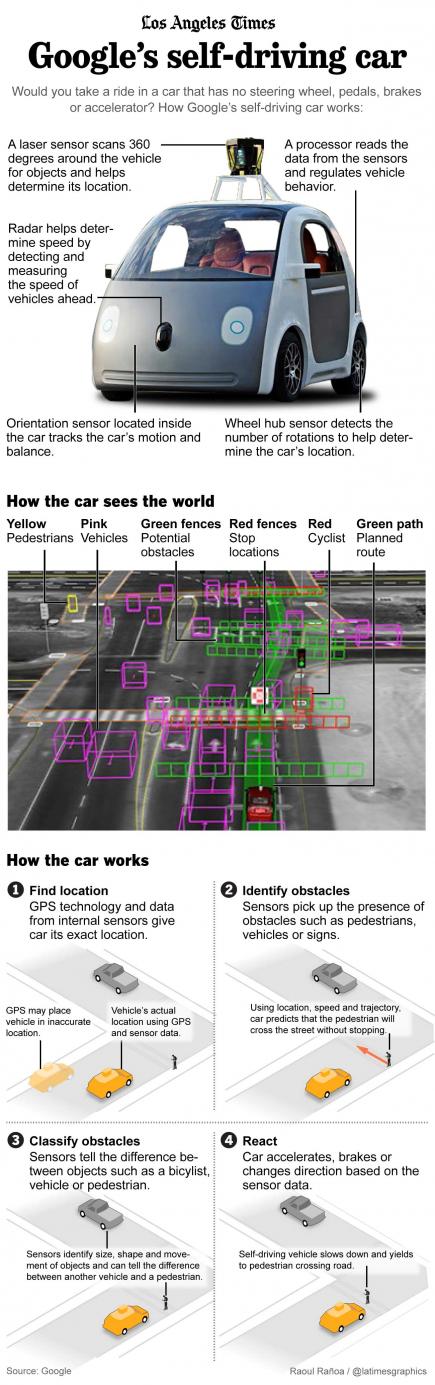
Design starts are the lifeblood of the semiconductor industry. It’s not just the design start itself, it’s the innovation that goes with it. As the semiconductor industry consolidates and the cost of modern semiconductor design increases you have to ask yourself: Where are the next generation of design starts going to come from?
Look at the postings on the SemiWiki Jobs Forum, the fabless semiconductor ecosystem is struggling to fill jobs. Since breaking ground on Fab 8 in 2009 GlobalFoundries has created approximately 2,000 jobs and that number is expected to grow by approximately another 1,000 employees for a total of about 3,000 new jobs by the end of 2014. Qualcomm has over 600 openings and even though Intel’s business is in decline they have more than 1,000 openings. So you have to ask yourself: Where are the next generation of semiconductor professionals going to come from?
The answer of course is the Universities and it is my belief that Silicon Cloud Internationaland the Internet of Things will lead the way:
SCI establishes secure cloud computing centers for universities and research institutions across the world. SCI’s initial focus is on providing turn-key design-to-manufacturing workflows for semiconductor design.
At the SCI booth, you will see several demo stations – unlike any other demo stations you have seen before! A diminutive Chrome box client is all that is needed to connect to powerful remote servers to perform real life design tasks on large circuits. Other than a demo on the main features of the system, you will also see:
SCI’s private cloud and thin client architecture and their unique security model for semiconductor eco-system providers and users
SCI’s chip design environment set up and workflow management capabilities
An online and interactive IC design training package developed by North Carolina State University
A couple of SCI’s partners, Plunify and Optic2Connect will be demonstrating their capabilities using the SCI cloud
Students from UCLA and Nanyang Technological University (Singapore) will be demonstrating and discussing their design work, running in the SCI cloud. The students’ demos are at the University Booth.
SCI founders will be on hand to demonstrate and discuss the attributes of the system. This includes:
- Mojy Chian, CEO, previously SVP of Design Enablement at GlobalFoundries
- Marc Edwards, CTO, previously with Nimbis, Synopsys and Cisco
- Joe Lee, VP of Engineering, a 30 year IBM IC design veteran
We invite you to visit us at Booth #209C to see how you can be a part of this semiconductor design enablement transformation!
Silicon Cloud Internationalwas started in 2012 and incorporated in July 2013 in Singapore by veterans of the semiconductor industry. The founders of SCI recognized the benefits of modern cloud computing technology for semiconductor design. The cloud is inevitable and the benefits of cloud-based IC design infrastructure are ubiquitously recognized including, unburdening the user from the cost and complexity of setting up IC design infrastructure, efficient and scalable use of EDA tools and computing hardware (pay-as-you-go), global knowledge sharing and IC design training, and global and collaborative IC design.
However, data and IP security and managing a very wide IC design eco-system have prohibited the launch of an IC design infrastructure in the cloud. Silicon Cloud International provides a unique and unprecedented technology for security, data tempering, and IP downloading.
SCI’s market deployment has initially focused on Asia Pacific and the Middle East regions (Malaysia, Singapore, Abu Dhabi, and Pakistan). Future plans for additional SCI Cloud data centers include Vietnam, Brazil, Germany, China, and the US.
More Articles by Daniel Nenni…..
lang: en_US