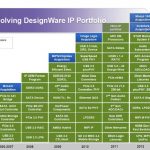
Synopsys has been extremely active, during the last 10 years, not only launching new IP products every year, but also running an ambitious acquisition strategy, with no less than 8 acquisitions. Cascade acquisition bring PCI Express (controller only), when Accelerant bring SerDes (the earth of any PHY IP). The MIPS/Chipidea acquisition, made opportunistically during the 2009 depression, has allowed Synopsys to add Analog IP (ADC, DAC, Codec…) to the port-folio, as well as a large analog-skilled team. The 18X more expensive acquisition of Virage Logic has been a way to manage the foundation IP (Libraries, Memory compilers), as well as some interface IP (MIPI PHY). The large amount of this last deal ($315 million) explains why the next two acquisitions, the 10G PHY technology from MoSys and Inventure (Japanese IP vendor) have been less “impressive”, but useful to complete a geographical coverage (Inventure) and PHY IP extension to 10 Gbps. Finally, with Target acquisition at the beginning of 2014, Synopsys has completed the IP port-folio with a dataplane, application specific, core IP vendor (think about Tensilica).
What a large port-folio, isn’t it? But Synopsys IP customers expect more…
Customer first care-about is definitely Time-To-Market (TTM), and we know that the weight of S/W development, both in team proportion (60 to 70% of the total) and delay length make it the first area of improvement. BTW, we assume that (H/W) IP quality is no more an issue in today’s IP market: if a vendor launch a piece of IP, it has to be top quality!
Synopsys brainstorming has resulted in “IP accelerated” initiative. If you think that IP Accelerated is another buzz word, you should take a look at the picture below:
Starting from the top, the broad IP portfolio box represent the several dozens of digital, PHY and mixed-signal IP that you can find on Synopsys web site for years. The left sided box, IP Prototyping Kits, illustrate Synopsys willingness to propose a complete H/W kit, immediately available for the designers. The Kit includes a reference design on HAPS-DX running Linux OS that you can easily modify, creating a fast iteration flow to explore various options. Every Prototyping Kit (USB, PCI Express, SATA…) will include a specific daughter board, populated with the relevant PHY IP (USB, PCIe, etc.), allowing exploring configuration with real-world I/O.
That looks easy on the paper, but I can tell you that it’s absolutely not straightforward to accomplish it in the real world! I am speaking based on my personal experience, trying to convince PHY IP partners (when you only sell the Controller IP), or even your management to make this type of investment when you sell the complete solution! As a customer, the benefit is immediate, as you can exercise the IP live, instead of only by simulation. As an IP vendor, the benefit is even greater, as you can literally “put on the table” and demonstrate the product you are selling.
IP Accelerated address another important care-about, at architecture level. At the early stage of SoC design, or even at integration stages, the SoC architect may need to explore various options. If we speak about a PCI Express core, it can be the payload size, the virtual channel number, the specification has been defined by very creative engineers, allowing many variations. Synopsys guarantee that the customer can change the PCIe core configuration in-house, using coreConsultant, then modify the reference design and fast compile the modified IP in ProtoCompiler DX.
Just a remark: IP vendors are usually reluctant to allow such flexibility. The reason is simply linked to Verification. Indeed, any possible configuration should have been previously checked by the vendor, using VIP. Synopsys claim to rely on 20,000 CPU just for running regression tests, and this certainly help accepting customer need for defining in-house their own configuration.
As you can see on the above picture, when Synopsys close an IP deal, the customer receives an “All In One” box. What about the S/W team? The S/W development team will benefit from SDK with proven physical targets, Linux software stack and reference drivers, allowing debug, test and analysis, as this SDK plug into existing tool chain, like GNU, ARM DS-5 or MetaWare. Moreover (Synopsys is also an EDA vendor!) the S/W developer could start working almost immediately on the SoC project, thanks to the availability of virtual prototypes. This is a perfect example of Concurrent Engineering context, where the S/W and H/W teams can start working exactly at the same time. Remember that TTM is the number one issue that this initiative is expected to address!
On the above picture, Synopsys explains that, in order to decrease the integration cost at the customer level, the company had to invest and take a share of this integration cost. In other words, Synopsys is not only selling an IP, generating license cost, but a complete package, integrating development board, reference design, virtual prototype, IP configuration tool, reference software stack and drivers. Thus, the customer is expected to pay more than simply the IP license cost, as the SoC development team will benefit from a faster integration cycle and the chip maker a better TTM…
If you remember the early days of Semiwiki, when DAN, Paul, Daniel and I were blogging for a lot less readers, Cadence had already identified this TTM issue, and launched “EDA 360” initiative. A couple of months later, DAN wrote a blog titled “EDA 360 is Paper”, and this blog was synthesizing the industry feeling. Cadence analysis of the SoC development challenge was good, but the proposed solution was not at the level of the industry expectation. It’s now three years later and Synopsys is still addressing the same issue. But the difference is that the company has packaged a set of existing tools, hardware and concepts and there is no reason why “IP Accelerated” should not be accepted… except a pricing issue (but I don’t know how IP Accelerated will be priced)!
From Eric Esteve from IPNEST
More Articles by Eric Esteve…..
lang: en_US