Today, Smartphones and mobile devices have become center of innovation with multiple functions getting into them. Considering the audio or voice application, there can be multi-way conferencing, video chat, complete audio/video streaming, gaming, voice triggering and recognition,… you name an application, and it will be there on your Smartphone in most probability. While it has created so easy and flexible use of all these features in the hands of user, it has very significantly increased complexity in the hands of mobile SoC designers who need to deliver these features with high-performance, high-resolution, multi-channel audio stream processing, high quality speech recognition, always-on voice trigger, and all that at extremely low-power.
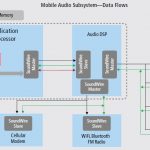
In audio/voice subsystems, DSP cores are used to handle data processing, compression, sample rate conversion, encoding/decoding, noise suppression etc. The audio DSP can be on an SoC along with the application processor or connected to the processor through a dedicated bus interface. The DSP core also connects to audio peripherals such as microphones and speakers, and cellular modem or WiFi/Bluetooth/FM radio combination through audio interfaces.
While this system is reasonably fine, the demand for high-performance audio data processing and voice over IP (VoIP) with improved noise suppression and noise-dependent volume control raises the DSP complexity and needs further improved architecture of the DSP and audio subsystem. Considering battery life criticality for mobile devices and always-on voice trigger, the system also needs to have very low-power profile. To satisfy these requirements, the DSP architecture must be very efficient with configurable memory and I/O partitions, advanced power management and scalable instruction set extensions. Along with DSP architecture, it is critical that audio data transport takes place in most efficient and optimized manner for low-power and high-performance. Interestingly, MIPI Alliance has also come up with new audio interface standards to optimize audio subsystem connectivity for the benefit of mobile industry. Let’s see in a greater detail the audio subsystem with improved architecture and new audio interface standards.
Here, the audio data transport is based on DSP-tunneled model instead of a common system memory to avoid multiple traversals of data on the bus hierarchy and the need to keep system memory and the bus hierarchy always powered. In the DSP-tunneled model, the audio data processing and transmit/receive through the audio interface are localized to the DSP processor with dedicated local memory and highly efficient FIFO-style interfaces; thus significantly reducing the power consumption.
The brand new audio interface standard used is Soundwire that is designed to support multiple devices including audio peripherals and DSP codec. It easily can be scaled up to support multiple data lanes to transport wide PCM audio samples between the application processor and the DSP codec. It can also be optimized to support the transport of narrow PDM samples to microphones and speakers on a single data lane. To minimize power, the standard defines a modified NRZI data encoding and double data rate for data transmission that minimizes active driving and switching of the bus wire load. The clock rate changing and clock stop protocols are well defined to minimize power consumption in always-on applications.
Cadenceis the leading provider of silicon-proven wide range of customizable IP for audio subsystem development. Cadence also leads the definition and development of the MIPI Soundwire standard.
Among Audio DSP IP, Tensilica Xtensa processor family offers highly customizable processor cores with high-efficiency instruction set architecture (ISA) extensions. A class of optimized HiFi processors targets various segments – HiFi Mini for voice trigger and recognition; HiFi EP for consumer electronics; HiFi 2 for mobile audio and voice; HiFi 3 for high-performance audio.
Among Audio Interface IP are I2S master/slave controller, S/PDIF controller, and MIPI Slimbus manager/device controller.
Cadence’s leading-edge audio DSP processor IP cores and audio interface IP cores are most suitable to build audio subsystems for high quality audio effects for multiple audio channels. Don’t forget to look at Cadence IP portfolio, if you are planning to build a low-power, high-performance, high quality, optimized audio/voice subsystem. Refer to the whitepaper for more details.