
Your latest SoC has just begun the tape-out process and then marketing comes back with a small update to the specification to make your design more competitive, or maybe your regression tests just found a minor bug in a single IP block that needs to be fixed. Should you go back in your design flow, change the RTL source code and then completely re-run all of the logic synthesis and physical implementation tools? Probably not, instead you likely will opt for an ECO (Engineering Change Order) flow instead to save time. Since an ECO flow is often equated with manually editing a gate-level netlist and hacking together script files, there is plenty of room for introducing new errors into a design, so be careful.
Engineers at Synopsys have come up with a method to speed up this ECO process and at the same time add some automation to ensure that you’re not introducing any new bugs. I spoke by phone with Graham Etchells and Mark Patton to get an update on their Formality Ultra flow to manage and automate the ECO flow. Here’s the concept:
Functional ECO Implementation
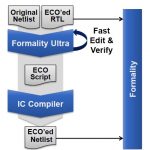
A design change comes in, the design engineer updates the RTL code, Formality Ultra shows you exactly where in your gate level netlist the effected net is, and the ECO scrips are generated for both Design Compiler (logic synthesis) and IC Compiler (place and route) tools. There’s a final verification that the new netlist matches the changed RTL code.
Related – Formality Ultra, Streamline your ECOs
A manual ECO approach would have you looking at your gate-level netlist with a text editor after logic synthesis, trying to find a net of interest, after all of the optimizations and you may not even find your net name. With this automated ECO approach you can visually find your net of interest at the RTL or gate level, click on it, then see where this same net is in the post-synthesis netlist:
Highlight equivalent nets
You can now implement and view each ECO interactively by:
- Graphically using the Verdi nECO tool
or
- With macro commands
ECO Schematic Editing
There’s even a way to see where your changed nets are in both the RTL and layout views, helping you to understand the physical impact before committing to a change.
Cross-highlightint
Verification of each ECO now only takes minutes, because only the limited areas of the logic change are automatically identified and run. Even if your entire design is millions of gates, the ECO verification runs in minutes so you can do more what-if analysis on how to best implement each ECO.
Related – LSI’s Experience with Formality Ultra
Once you are satisfied with each ECO fix, then the scripts to control IC Compiler and Design Compiler are created automatically:
Integrated Tool Flow
Most ECO changes effect a few dozen gates, so if your RTL changes impact hundreds of gates or more then you’ll probably just re-synthesize and re-implement that part of your design instead of trying an ECO flow.
Related – How STMicroelectronics uses Formal Tools (Webinar)
Summary
SoC designers can be more productive by moving from a manual ECO flow to a more automated approach using the Formality Ultra, Design Compiler and IC Compiler flow. Instead of taking weeks on a manual ECO approach, you can now do the same work in days. The learning curve for Formality Ultra is a day or two, and customers like Cavium and Centaur Technology are shaving valuable time off their schedules.
