In the Open Source IP panel at 53DAC, we explored the idea of workload-optimized servers. One panelist observation stuck with me: if one chooses to deviate from the Intel-based norm in a data center, you essentially have to spray paint a line around any boxes that don’t comply. Continue reading “Webinar alert – ARM and Enea explore NFV”

Semiconductor IP QA Standards Get a Boost at #53DAC

At the #53DAC earlier this month held in Austin, Texas I met up with Renee Donkers, the founder of Fractal Technologies. His company has been focused on improving the quality of semiconductor IP cells through the use of automated checking software. The highest area of growth in EDA as measured by the ESD Alliance is in the reusable IP cells being provided by IP vendors, so it makes sense that we really need an independent method for validating the quality of IP blocks and all of their files for correctness and consistency.
Continue reading “Semiconductor IP QA Standards Get a Boost at #53DAC”
IBM Fires a Shot at Intel with its Latest POWER Roadmap
In case you worry that IBM will abandon hardware in the pursuit of its strategic initiatives focusing on cloud, mobile, analytics and more; well, stop worrying. With the announcement of its POWER Roadmap at the OpenPOWER Summitearlier this spring, it appears POWER will be around for years to come. But IBM is not abandoning the strategic initiatives either; the new Roadmap promises to support new types of workloads, such as real time analytics, Linux, hyperscale data centers, and more along with support for the current POWER workloads.
Pictured above: POWER9 Architecture, courtesy of IBM
Specifically, IBM is offering a denser roadmap, not tied to technology and not even tied solely to IBM. It draws on innovations from a handful of the members of the Open POWER Foundation as well as support from Google. The new roadmap also signals IBM’s intention to make a serious run at Intel’s near monopoly on enterprise server processors by offering comparable or better price, performance, and features.
Google, for example, reports porting many of its popular web services to run on Power systems; its toolchain has been updated to output code for x86, ARM, or Power architectures with the flip of a configuration flag. Google, which strives to be everything to everybody, now has a highly viable alternative to Intel in terms of performance and price with POWER. At the OpenPOWER Summit early in the spring, Google made it clear it plans to build scale-out server solutions based on OpenPower.
Don’t even think, however, that Google is abandoning Intel. The majority of its systems are Intel-oriented. Still, POWER and the OpenPOWER community will provide a directly competitive processing alternative. To underscore the situation Google and Rackspace announced they were working together on Power9 server blueprints for the Open Compute Project, designs that reportedly are compatible with the 48V Open Compute racks Google and Facebook, another hyperscale data center, already are working on.
Google represents another proof point that OpenPOWER is ready for hyperscale data centers. DancingDinosaur, however, really is interested most in what is coming from OpenPOWER that is new and sexy for enterprise data centers, since most DancingDinosaur readers are focused on the enterprise data center. Of course, they still need ever better performance and scalability too. In that regard OpenPOWER has much for them in the works.
For starters, POWER8 is currently delivered as a 12-core, 22nm processor. POWER9, expected in 2017, will be delivered as 14nm processor with 24 cores and CAPI and NVlink accelerators. That is sure to deliver more performance with greater energy efficiency. By 2018, the IBM roadmap shows POWER8/9 as a 10nm, maybe even 7nm, processor, based on the existing micro-architecture.
The real POWER future, arriving around 2020, will feature a new micro-architecture, sport new features and functions, and bring new technology. Expect much, if not almost all, of the new functions to come from various OpenPOWER Foundation partners, POWER9, only a year or so out, promises a wealth of improvements in speeds and feeds. Although intended to serve the traditional Power Server market, it also is expanding its analytics capabilities and bringing new deployment models for hyperscale, cloud, and technical computing through scale out deployment. This will include deployment in both clustered or multiple formats. It will feature a shorter pipeline, improved branch execution, and low latency on the die cache as well as PCI gen 4.
Expect a 3x bandwidth improvement with POWER9 over POWER8 and a 33% speed increase. POWER9 also will continue to speed hardware acceleration and support next gen NVlink, improved coherency, enhance CAPI, and introduce a 25 GPS high speed link. Although the 2-socket chip will remain, IBM suggests larger socket counts are coming. It will need that to compete with Intel.
As a data center manager, will a POWER9 machine change your data center dynamics? Maybe, you decide: a dual-socket Power9 server with 32 DDR4 memory slots, two NVlink slots, three PCIe gen-4 x16 slots, and a total 44 core count. That’s a lot of computing power in one rack.
Now IBM just has to crank out similar advances for the next z System (a z14 maybe?) through the Open Mainframe Project.
DancingDinosaur is Alan Radding, a veteran information technology analyst and writer. Please follow DancingDinosaur on Twitter, @mainframeblog. See more of his IT writing at technologywriter.com and here.
ASML pays $3.1B for Hermes to get E-beam inspection
Cheap versus year ago but expensive on fundementals – Net negative for KLAC/LRCX & AMAT. ASML bought Hermes Microvision for much the same reason as the Cymer acquisition – to support EUV. ASML could have made a counter offer for KLAC (as we had suggested previously) but this obviously would have been much more expensive and risky from a regulatory perspective (as Lam has found out).
So ASML did the next best thing and bought the competitor that had beat KLAC in the market..Hermes. Though the acquisition is expensive it is a strong strategic move to shore up support for EUV infrastructure which desperately needs help for what has become embarrassingly late and so fraught with issues such that is survival has been questioned.
Cheap and expensive at the same time…
Relative to the crazy stock price that Hermes had reached a year ago, the acquisition price at half the peak price seems cheap by comparison but you have to remember that the price is 15 times revenues not earnings. The PE multiple paid is closer to 50.
Investors need to recall that the Taiwanese exchange is over priced as compared to the US exchanges with lots of Taiwanese dollars chasing a limited pot of equities.
The same logic holds true for over priced European equities (of which ASML is one) where European investors have a lot of cash chasing after relatively few tech companies.
In short, it is one overvalued company , ASML, buying an even more overvalued company , Hermes Microvision at eye popping valuations versus US based companies.
KLAC forced the issue…
When KLAC dropped its EUV mask inspection program, ASML lost a huge, critical piece of much needed infrastructure to make its EUV tool viable. Lam’s acquisition of KLAC sealed this fate as LAM gets benefit from multi patterning at EUV’s expense, and will scatter the ashes of the EUV reticle inspection tool.
ASML had essentially no choice but to buy the only significant , viable, alternative EUV mask inspection/metrology tool company to keep the infrastructure alive and accelerate it.
As we had pointed out in many articles it has become clear that now, finally after source and power issues are getting resolved, the industry is finally waking up to the fact that there is not enough EUV infrastructure and this acquisition is meant to insure and accelerate that deficiency.
Negative for AMAT and KLAC/LRCX…
As a standalone company Hermes has a harder time competing with both AMAT and KLAC. AMAT has a significant E beam tool and KLAC recently released its 5th generation optical tools. But as part of the much larger and essentially monopolistic ASML, with limitless pockets and market leverage Hermes will do much better.
We are also sure that now that ASML has become a competitor , whatever semblance of working with AMAT and KLAC ever existing will quickly vanish as ASML will obviously only work with and push their own product and try to choke off the AMAT and KLAC competitive products.
ASML has a lot of muscle and leverage to do this and hurt both competitors in the process. Bundling litho tools with the purchase of inspection tools would give an unfair advantage in the market.
Speaking of unfair advantage…
Though at first blush most people would assume an easy regulatory approval for the combination given the lack of overlap (as with Lam and KLAC) but we would point to the near monopolistic position of ASML in the litho market and along with it would come an ability to restrict competition of currently competitive metrology/inspection tools.
As with the KLAM combination its not the overlap that counts but the anti-competitive potential that the deal brings. Given that the deal has to be approved in the US, we would not be surprised if it gets a second request much as KLAM has. Because the deal will also come at the 11th hour in the current administration which is already not corporate friendly even in the US and its involving two foreign companies, it may make it even tougher.
From KLAM’s perspective “whats good for the goose is good for the gander” or perhaps misery loves company.
The semiconductor M&A lint roller, rolls along…
As we had said earlier this year, and at our recent industry SEMI keynote speech in Albany, we see no reason for the M&A pace to slow down. Though this deal seems to be driven more by desperation and need rather than economics (especially at this high a price), we think there are still many reason for M&A to continue….there are a lot of companies still left to roll up.
The stocks…
Even though ASML is paying a high price relative to the industry and its own valuation, the strategic value likely overwhelms the financial value and thus is a near term positive. However we think that this acquisition alone will not significantly alter the odds of EUV’s success and ASML still has much work to do. This Hermes acquisition is not as core to EUV as Cymer was. Long and short, we think investors would and should like the combination as it no doubt will help ASML. We would caution that the “arb spread” could be wide as approval may not be as easy as most initially think.
Although this is a negative for AMAT and its E beam aspirations it is more of a negative for the KLAM merger. The merger is already likely less attractive as they will likely be some remedies to get the deal done which will have a cost associated. Now KLA’s core business will be under direct attack from a much larger company, ASML, supporting a smaller company, Hermes, that had already done significant damage to KLAC’s market share and leadership in metrology/inspection. KLAC’s “flub” of the Ebeam market continues to be one of the few missteps the company made but a costly one that keeps coming back to haunt it. This problem will now become Lam’s problem…
TMR approaches should vary by FPGA type
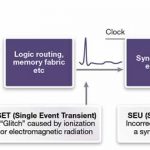
We’ve introduced the concepts behind triple modular redundancy (TMR) before, using built-in capability in Synopsys Synplify Premier to synthesize TMR circuitry into FPGAs automatically. A recent white paper authored by Angela Sutton revisits the subject Continue reading “TMR approaches should vary by FPGA type”
IC Designers talk about 28nm to 7nm challenges at #53DAC

IC design challenges are different at advanced nodes like 7nm, so to learn more about the topic I attended a panel luncheon at DAC sponsored by Cadence. The moderator was both funny and technically astute, quite the rare combination, so kudos to Professor Rob Rutenbar, a former Neolinear guy now at the University of Illinois. Panelists included the following people:
Continue reading “IC Designers talk about 28nm to 7nm challenges at #53DAC”
Which CEVA DSP to use to Support Multimode Connectivity Requirements of IoT and M2M?
The definition of IoT systems is moving fast: the simple definition of a connected (to Internet) device in the early days is becoming more complex and also more precise. IoT or M2M devices are expected to support the full range of emerging cellular protocols such as LTE MTC Cat-1, Cat-0 or Cat-M, as well as the suite of Low Power Wide Area Network (LPWAN) standards such as Lora, SigFox and Ingenu. IoT and M2M will also interface with other IoT-related communication standards, including Wi-Fi 802.11n, PLC, 802.15.4g, ZigBee/Thread, GNSS or any emerging protocols such as NB-IoT and Wi-Fi 802.11ah.
The IoT or M2M designer has the choice between integrating CEVA-XC8, the fifth generation of the widely licensed CEVA-XC architecture, optimized for IoT communication applications as well as UE terminals, or CEVA-XC5. This sixth generation, the CEVA-XC5 is optimized for IoT communication applications, 802.11n, PLC, 802.15.4g, GNSS as well as other connectivity applications. The CEVA-XC5 delivers highly powerful vector capabilities alongside a general computation engine to supply the performance and flexibility demanded by various IoT communication applications, while meeting the strict demands for power efficiency and low cost.
Developing an IoT or M2M device implies selecting cost optimized architecture, exhibiting the highest possible performance to power ratio, leading to select CEVA-XC5 DSP core.
Designing IoT or M2M platform will lead to select the CEVA-XC8 delivering highly powerful vector capabilities alongside a general computation engine to supply the performance and flexibility demanded by various IoT communication applications.
According with Linley Gwennap, principal analyst at The Linley Group, ”designers of multi-standard, low data rate LTE-capable devices have two priorities: minimizing cost and power, and with the CEVA-XC5 and CEVA-XC8, CEVA has leveraged its industry-leading position in communications DSPs to deliver the small die size and high power efficiency that these designers need for IoT and other applications.”
Once the IoT SoC architecture has been defined, using CEVA-XC5 for a device or CEVA-XC8 for a platform (or base station), the project manager has to care about software development and make sure to use concurrent engineering to develop software and hardware in parallel to optimize the project development schedule. We know that the software development is expected to consume 2/3[SUP]rd[/SUP] of the project resources in average. The project manager has to make sure that the DSP IP core supplier will also propose a software development platform.
This is the CEVA Dragonfly reference platform, pictured below, including DSP drivers, RTOS, DSP library, C run-time library and also LTE MTC Modem and Voice & VoLTE libraries. On top of these libraries, the designer could take benefit of existing software IP, available to support a project development the same way than hardware IP.
Taking the example of satellite localization for M2M or IoT, let’s get the feedback of Eli Ariel, CEO at Galileo Satellite Navigation. “The CEVA Dragonfly reference platform delivers exceptional performance for implementing our software-based GNSS receivers in devices within a stringent power budget,” said Eli Ariel, CEO at Galileo Satellite Navigation. Our Software Receiver solution perfectly complements CEVA’s software-based approach to design flexibility and long service life MTC systems design, allowing customers to carry out performance improvements and new features in the field, including upgrading to future satellite systems.”
This comment from Nestwave CEO helps understanding how powerful can be the Dragonfly reference platform to speed up project development schedule: “Accurate positioning, both indoor and outdoor, will be a fundamental component of many M2M applications and our CellNav™ technology delivers this accuracy utilizing the existing LTE network infrastructure,” said Rabih Chrabieh, CEO of Nestwave. “Using the CEVA Dragonfly platform, customers can integrate CellNav into their MTC product designs, enabling reliable location tracking in devices that can last years in the field on a single battery.”
I suggest you to attend remotely to this webinar, describing a real design case using CEVA-XC5 and Dragonfly reference platform:
Webinar: Design a LTE-based M2M Asset Tracker SoC with CEVA, using GNSS and OTDOA
Eric Esteve from IPNEST
Synaptics’ New Security Adapter Takes PC Fingerprint Security Literally Anywhere
Synaptics is an understated innovator in the human interface and end user experience technology space, and many of the hottest smartphones, tablets and PCs have their technology inside. The Samsung Galaxy S7, Apple iPhone 6S, Dell XPS 15, Microsoft Surface and Surface Book, and HP ENVY are just a few of these products I’ve personally used. One of the interface technologies that Synaptics excels at are fingerprint sensors.
While most of the PC “swipers” are Synaptics today, the company has been working with both PC OEMs and smartphone vendors over the last two years to integrate their latest fingerprint technologies into a multitude of devices. Synaptics has also taken their finger print sensor and integrated them into their own touchpads and has the unique position of being able to get their customers to integrate both into their devices. However, the fingerprint sensor ecosystem requires a robust back-end to enable use cases outside of secure PC login and password replacement. While PCs were the first to have biometric finger “swipers”, the PC has lagged behind smartphones and tablets. I’m hopeful Synaptics latest technology can change all that.
USB Fingerprint Security Key mockup (Photo credit: Synaptics)
Synaptics has been working with partners like Microsoft and Lenovo to make computers more secure with multi-factor authentication. Biometric methods of authentication help to reduce the probably of unauthorized access and at the same time improve the user experience. We have written on that here. Synaptics’ Natural ID technology is designed to work with technologies like Windows Hello and Microsoft Passport, which already give them legitimacy in the Windows 10 world. Microsoft Windows 10 is designed to be the most secure version of Windows ever while also being the most user friendly, so native support for things like biometric authentication are logical.
Synaptics is introducing a new ultra-small form factor USB module that enables the use of their Natural ID fingerprint authentication on any PC with a USB port. This module will primarily be focused on notebooks and notebook users, but could theoretically be used for any PC. The USB dongle is a turnkey solution for OEMs, ODMs and other manufacturers to offer an inexpensive finger print sensor into PCs without one. The dongle is small enough to remain installed in any notebook USB port and with enrollment can be used to enable features like Windows Hello and Microsoft Passport.
This solution is merely a short term solution until more PC manufacturers like Dell, Lenovo, HP and Apple figure out that fingerprint sensor technology has reached a point where it both improves experience and security. With nearly all flagship and mid-range phones featuring fingerprint sensors, it is almost inevitable that fingerprints will drive a lot user experiences on all platforms, not just mobile. The company’s new fingerprint reader adds yet another form factor to the other offerings that Synaptics offers their customers in order to best satisfy their form factor needs. In some notebook designs it may simply not make sense for them to integrate a fingerprint sensor into the wrist pad or touchpad quite yet but the manufacturer may still want to offer fingerprint sensing as a feature.
While I am disappointed that PC manufacturers like Apple, Dell, Lenovo and HP Inc. haven’t included enhanced fingerprint readers yet into their personal computers, I am hopeful that 2016 will be the year this happens. There are pragmatic reasons they haven’t done this, but the lack of integration is yet another example we can all point to showing PCs are behind the curve.
Synaptics is constantly pushing the industry towards new user interface experiences and improved security. With their new USB dongle, they are making it easier for anyone to implement a fingerprint sensor on their PC and integrate it with next-to-no engineering effort. There are also opportunities for people to add this dongle to their keyboards and other USB peripherals that might have a USB port. The fingerprint sensor dongle will sample in Q3 this year and mass production is expected in Q4 this year, meaning that we could see these very low profile fingerprint dongles in PCs by the end of this year.
The Evolution of IoT Platforms
Hype-cycles are well known phenomena to those who pay attention to high-tech markets. Since we are probably at a peak of the early IoT hype-cycle in 2016, it’s natural to expect this latest wave of technologies to evolve just like other tech categories have in the past, with the eventual market power and market value going to a few consolidated, independent, and market leading platform companies. I think making this assumption could be a big mistake, particularly when it comes to platforms for IoT enablement (connected device platforms).
In the tech industry, industry platforms get created when markets consolidate around a small number of players who deliver standardized services (the platform) that enable application development and deployment. From the perspective of a technology business, history suggests that companies with new disruptive innovations repeat a similar process to eventually achieve market-leading platform status:
[LIST=1]
You might also expect this process to result in high business valuations and industry domination by a few independent tech company winners. After all, when it comes to application enablement platforms, when markets mature, a small group of companies will usually end up dominating as their customers flock to the safe choices. Right?
Maybe not. In fact, there are good reasons why IoT technology categories may evolve very differently. Companies within previous B2B application enablement categories like app servers, BPM, databases, ERP, marketing automation, messaging, sales automation, switching, and others, grew their power (and market valuation) by consolidating services to support multiple use cases. As they consolidated, they achieved rapid revenue growth and built entrenched partner ecosystems, leveraging high switching costs, dominating market share, and controlling architectures that became widely adopted.
In essence, they helped to create and then control the complete industry value chain built around their platform.
This was the playbook that category leaders from Autodesk and Adobe to SAP and MS/Windows executed to become market dominators. Unlike with these past categories, however, the value chains for connected device applications are going to be much more difficult for technology companies to directly control. In my opinion, IoT infrastructure providers will face significantly bigger challenges in achieving the kind of mega-Gorilla status and sustained high valuations than did their predecessors.
In the rest of this post I will refer to “the customer” as the customer of a technology companywho sells IoT infrastructure. I won’t get into the details of either the IoT platform value chain or the IoT business models here, but as reference, two recent posts by Microsoft’s Mohit Agrawal nicely illustrate both: the first post, “Business Models in the Internet of Things” illustrates the IoT value chain. The second post, “Impact of Internet of Things on Business Models,” summarizes different business models that are coming into play.
IoT is about accessing, analyzing, and operating upon information retrieved from edge devices, and then using that information to create efficiencies and improvements to the performance of those edge devices (or the end customer’s experience). The value chain doesn’t just end at the customer (the organization which a tech company sells to). It extends to the customer’s customer (or the customer’s machine) at the network edge. The insights generated from the data are a major part of the value created — what edge devices are doing, when they need maintenance, how or why consumers are using them, and what might be expected to happen next.
Companies who want to expose this value require a way to optimize machine or consumer experience through the use of increasingly sophisticated analytics. This is key, because unlike the other categories I referenced previously, the companies who embark upon a connected device strategy (the customers of technology companies)are likely to see IoT infrastructure as a strategic investment into their core businesses and into their actual products and processes.
This viewpoint will make it more likely for these companies to interact with technology providers strategically, and even in a competitive way. They may need the tech companies to initially assemble solutions and build market entry. But, just like independent software companies have done in the past, as markets mature and growth eventually slows, they will will start looking for ways to design the partner tech companies out of the game, either through independent in-house development, consolidation, or acquisition. Since the application value to be unlocked requires access to the edge-point data, and because the manufacturer owns the access to that data, the real power in the IoT market is much more likely to migrate towards manufacturers rather than only to the tech companies who support them.
Consider this:
when application infrastructure such as ERP, messaging, CRM, marketing automation, and others were originally adopted by major manufacturers such as GE or Bosch, it was undoubtedly clear to them that building and controlling the software platforms internally made little sense. It was a different business than the ones which they were in; the competencies required were different, and, had they invested in trying to do it themselves they’d have gotten zero credit in the public markets for the effort. Today, however, it’s not so clear. Large corporations that plan to implement connected device strategies may see platforms that control, manage, analyze, maintain, and update devices as natural investments into their core businesses. They may also see the IoT as a way of transforming aging commodity product businesses into modern “products-as-a-service” businesses with more predictable revenue streams.
In fact, both GE and Bosch appear to have reached this conclusion. GE, for example, has made heavy investments into creating its GE Digitalgroup, and establishing its Predix IoT platform not just for use within its own divisions, but for use by other organizations and industries. It’s invested at least $ 105M into the big data and cloud PaaS company Pivotal. Bosch, recently acquired Cologne-based ProSyst Software GmbH to fuel its own IoT offerings, and says it will also make the software available to other companies. Unlike the early days of front and back office application enablement categories, manufacturers such as GE and Bosch no longer see commercial software as something far afield from their core businesses. In fact, they are investing millions into software enabled offerings of their own.
Unlike earlier technology categories, where independent, market-dominating technology providers grew as independent companies, it’s more likely for key IoT platform solutions to end-up under the eventual ownership and control of the companies who manufacture the “things” of the IoT. Their primary competitors may not be Gorilla-like independent software companies that deliver a complete solution, but consortia-driven, open source platforms.
Another key difference with IoT applications has to do with how value is created. Because connected device applications get much of their value from analytics sourced from edge device or end-user data, independent IoT platform providers can be blocked by their customers from creating and owning analytics-based applications due to the sensitive nature of the customer data required.
IoT platform providers can certainly provide tools that enable customers to create analytics — for example, descriptive analytics that report things about where edge devices are at, how they are performing, what they are doing, etc., but this level of analytics is always the first to commoditize. The larger value from a connected device strategy comes from predictive analytics — machine learning and prescriptive alerts that operationalize and optimize device performance. Creating these high-value predictive use cases requires open access to statistically significant edge device data to understand whether an application is even possible. Tech companies can get access to this sensitive customer data doing work for hire, but they are often prohibited from owning the resulting intellectual property that could enable them to build reusable and marketable business applications.
Nick Beimrecently wrote a TechCrunch article The Barbell Effect of Machine Learning, pointing out how these higher forms of analytics will likely concentrate value among those who own the data. I agree. Within the IoT market, I believe that other major manufacturers, just like GE and Bosch, will come to realize that the data harvested from their edge device installed bases, and the corresponding analytics, are the golden jewels for creating business value. And, if they are making the investment into developing this infrastructure for their own divisions, why not leverage the efforts to create the same tools for other businesses to use?
So, what about the independent software vendors such as PTC, who acquired Thingworks and Axeda, or Autodesk, who acquired SeeControl? Both companies made these acquisitions very early in the IoT life-cycle, and each of these acquired businesses now has deeper resources and an existing customer base to up-sell into. Even so, I don’t believe that industry consolidation of the type we saw with ERP, sales automation and the other B2B mega categories is likely to happen. Companies such as Autodesk and PTC will still face the value chain barriers that did not exist with PLM/PDM and CAD tools. Over time, their competition will include companies such as GE, Bosch, and probably many other industrials who can differentiate through deep domain knowledge at the high end, and at the low-end, the possibility of open-source and consortia led offerings.
If I’m even a little right about this, the eventual shake-out will produce a more fragmented industry as compared with what we’ve come to expect based upon history. Connected device players who execute a platform strategy and remain independent will find it harder to achieve real market dominance. These can still be tremendous businesses, of course, but they might not achieve the huge platform valuations that previous tech Gorillas did in their heyday. At the same time, established Fortune 100 companies who choose to invest into building connected device platforms themselves may increase their bottom lines through efficiencies and their top lines through recurring services, but the financial markets will probably just value them as better versions of themselves unless or until they eventually spin out those businesses as independently valued pure-play companies. Either way, it will be interesting to see how this market evolves.
Democracy is a great thing, except in the workplace
“The Soviet Union I left behind was a dictatorship but the workplace was a democracy; America may be free but the workplace is a dictatorship” said Len Erlikh after I hired him at First Boston (now Credit Suisse First Boston) in 1986. Being of the Jewish faith, he had fled the U.S.S.R.’s religious persecution.
Erlikh’s words have always stuck with me. It is true that in capitalism, the workplace is mostly autocratic. You do what you are told and don’t have any say in the company’s strategy and operations. The Soviet collectives allowed much greater worker participation — and that is probably why they failed.
Business leadership is not a popularity contest; the best companies are run by enlightened dictators.
CEOs must listen very carefully to their employees but they have to do what is best for the company, employees, and shareholders. They have to make tough decisions and take responsibility when things go wrong. They expect that once the decision is made, everyone will comply — whether the decision was good or bad. The best leaders share the credit when they achieve success and take all the blame when things go wrong.
I know that dictatorship doesn’t sound nice but it is what business leadership entails. People love to follow strong leaders. They want to be led by people with vision, conviction and good values. They may not agree with everything the leader decides, but as long as ethical lines are not being crossed, employees will follow directions, work hard, and be loyal.
Look at some of the most successful business leaders:
- Walt Disney would ask employees for their ideas through surveys but would then dictate his requirements. When employees didn’t perform, he would fire them immediately. He had a clear vision, was coherent and moral, and demanding. Disney did end up becoming excessively autocratic and losing touch with what made him successful. Yet he touched the hearts and minds of billions all over the world and created one of the greatest companies of its time.
- Henry Ford was known as a tough leader who had a hand in every major decision. He was so demanding of his employees that he monitored their activities outside of work. He was, however, resolute in vision. Ford defied his investors when they demand he build a car for the wealthy and increased average wages to $5 a day while reducing the work day to eight hours. He ended up revolutionizing transportation and setting new standards for the workplace.
- Steve Jobs ruled with an iron fist and demanded absolute secrecy and loyalty from his employees. He was egotistical and moody. Yet Jobs had a brilliant vision, unwavering determination, and uncanny understanding of what consumers wanted. He built the world’s most valuable company and set new standards for technology design.
- The greatest technology innovator of today, Elon Musk, is a highly imperfect human being who makes extreme demands and sets unrealistic public deadlines for his employees. Yet he is single-handedly changing several industries — including space, energy, and transportation.
Autocratic leadership only works until it doesn’t work, however. And then everything goes wrong; entire companies collapse. Autocratic CEOs often become the bottlenecks in decision making because everything has to be approved by them. And they cause employees to stop taking risks because they become fearful of making the wrong decision. These CEOs start believing their own press and lose touch with what made them successful. If you look at any list of defunct companies that were household names, you will find misguided autocrats at their helm.
There needs to be a balance between strong leadership, autonomy, and empowerment of employees. And leaders need to step aside when they have peaked as Cisco CEO John Chambers did last year. He too was an autocrat who said to the New York Times “I’m a command-and-control person. I like being able to say turn right, and we truly have 67,000 people turn right.”
Chambers realized technology was making it possible for leaders like him to rule in a better way, with more collaboration and teamwork. He said in 2009, “If you had told me I’d be video blogging and blogging, I would have said, no way. And yet our 20-somethings in the company really pushed me to use that more.”
The job of manager today is to lead, articulate goals, inspire, motivate, and enable. CEOs must facilitate rather than control as well as listen and communicate. With technology, they can get input from every part of the company and explain the unpopular decisions. Through email, internal social media, and idea exchanges, companies can have everyone participate in problem solving.
Employee engagement can be done on small decisions as well as big ones. In February, IBM made a big decision, to revamp its global performance evaluation system, by crowdsourcing the solution. It explained the deficiencies of its old system to its 380,000 employees in 170 countries through its internal social media platform and asked them to suggest solutions. Based on the 2000 comments it received, IBM ended yearly reviews and replaced these with a system for shorter-term goals and quarterly feedback. These are the types of structural changes that are needed in today’s era of exponential technologies — in which a year is a lifetime and shifts in strategy are needed every few months.
Leaders can be dictatorial yet inspire and motivate if they listen and communicate effectively — and honestly. To survive the disruptions that technologies will cause in practically industry, companies will need enlightened dictators who have a heart.
For more, follow me on Twitter: @wadhwa and visit my website: www.wadhwa.com.