Everyone up and down the electronics supply chain is jumping on the ISO 26262 bandwagon and naturally they all want to show that whatever they sell is compliant or ready for compliance. We probably all know the basics here – a product certification from one of the assessment organizations, a designated safety manager and a few other safety folks and some form of safety process. Sound like easy boxes to check? Unfortunately for you the integrator, the basics may no longer be enough to complete your deliverables for your customers with respect to that IP.
Kurt Shuler, VP of Marketing at Arteris IP, sits on the ISO 26262 working group (since 2013), along with partner ResilTech (functional safety consultants, on the WG since 2008), so they’re pretty well tuned to industry expectations. What Kurt observes is that default assumptions about what level of investment is required to fully meet the standard can often fall short.
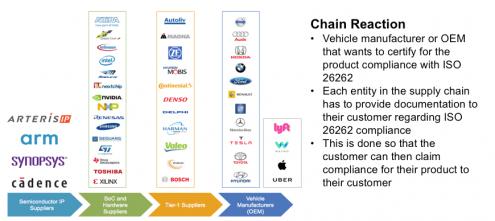
The ISO standard ultimately wants to validate the safety of systems, not bits of systems, because there’s no guarantee in safety that the whole will be the sum of the parts. But waiting until the car is designed before checking safety would be unmanageable, so a lot of requirements are projected back onto earlier steps in the chain. Each supplier in the chain must demonstrate compliance not only in their product, including all aspects of configuring and implementing safety-critical components, but also in their process and their people. And proof of these safety-related activities must be communicated up the supply chain.
Further ramping expectations, as ADAS capabilities extend and as autonomy continues to advance, the automotive industry is apparently increasingly pushing for ASIL D (the highest level) compliance at the SoC level, which is less expensive in total system cost than using ASIL-B SoCs (the common expectation today) to reach ASIL-D at the system level through duplication. ASIL-D requirements are naturally much more rigorous, tightening the screws not only on the SoC integrators but also on their suppliers.
Kurt calls out three areas where default expectations fall short in what is good enough for compliance. The first is in people alignment with safety. A common view is that you can train or hire a functional safety manager (FSM) and a small number of safety engineers whose role is to ensure that everyone else stays on track. While this may meet the letter of the standard, apparently it doesn’t meet the spirit (a strong safety culture) and the spirit is likely to be a better guide as expectations rise. A more robust approach drives safety training more extensively through the organization, in addition to having an experienced FSM.
The second area is in process where quality management, change management, verification and traceability are all important. This is partly about tools (we all love tools) but more importantly about consistent and continual use of the processes defined around these areas. It is certainly helpful to use certified tools or to get certification for internal tools, but that doesn’t mean you’re done. Your customers will perform independent audits of your processes because they’re on the hook to prove that their suppliers follow the standard in all relevant aspects. Of course you could all learn in real-time and correct as needed but obviously it will be less painful and less expensive to work with partners who are already experienced and proven in prior audits.
The third area is around product compliance. From my understanding, general alignment on expectations may be better here, simply because we have tended to focus primarily on product objectives. The expectations of who is responsible for what between supplier and customer, in terms of assumptions of use, configuring a function, implementation and so on are documented in the Development Interface Agreement (DIA); this needs to be demonstrated as a part of compliance. Assuming these steps are followed, there is one area Kurt feels product teams need to ramp up their investment – in development of the initial failure mode effects analysis (FMEA). I hope to write more on this topic in a subsequent blog; for now, here’s a quick teaser. We engineers are biased to jumping straight to design and verification – concrete and quantitative steps. But FMEA is a qualitative analysis, assessing possible ways in which a design (or sub-design) could fail and the possible effects of those failures. This is the grounding for where you then decide to insert safety/ diagnostic mechanisms and how you measure the effectiveness of those mechanisms through fault analysis.
Kurt also stresses what I think is an important consideration for any SoC supplier when considering an IP solution. Ultimately the SoC company owns responsibility for demonstrating compliance to the standard to their customers. That’s a lot of work and expense so they can reasonably question the IP supplier on how they are going to make that job easier. One aspect is in people training – is the supplier meeting the letter of compliance or comfortably aligned with the spirit? One is in process – using approved tools and flows certainly but also being experienced in audits and already being proven on multiple other engagements. And finally in product, again that the supplier has not only done what the standard requires but goes beyond to simplify the SoC team’s configuration and safety analysis through templates for failure modes and effects and fault distribution guidance.
Food for thought. It seems like some ISO 26262 investments need future-proofing, If you want to read more, check out this link.