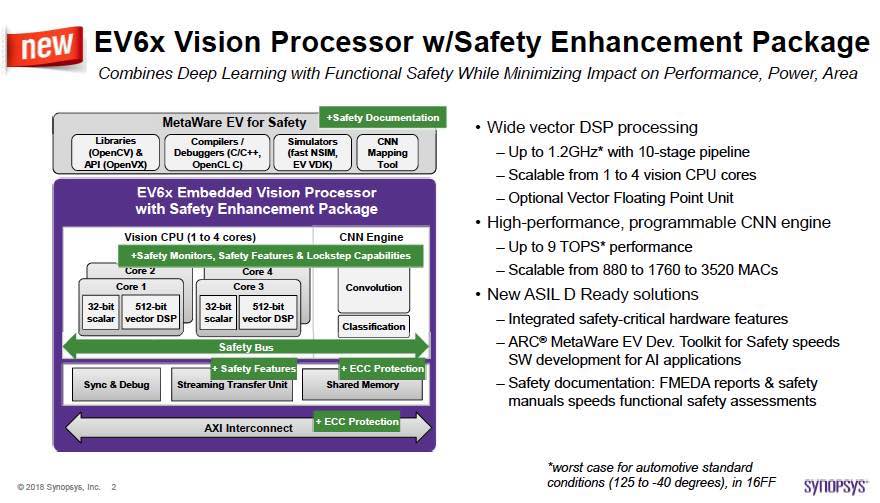
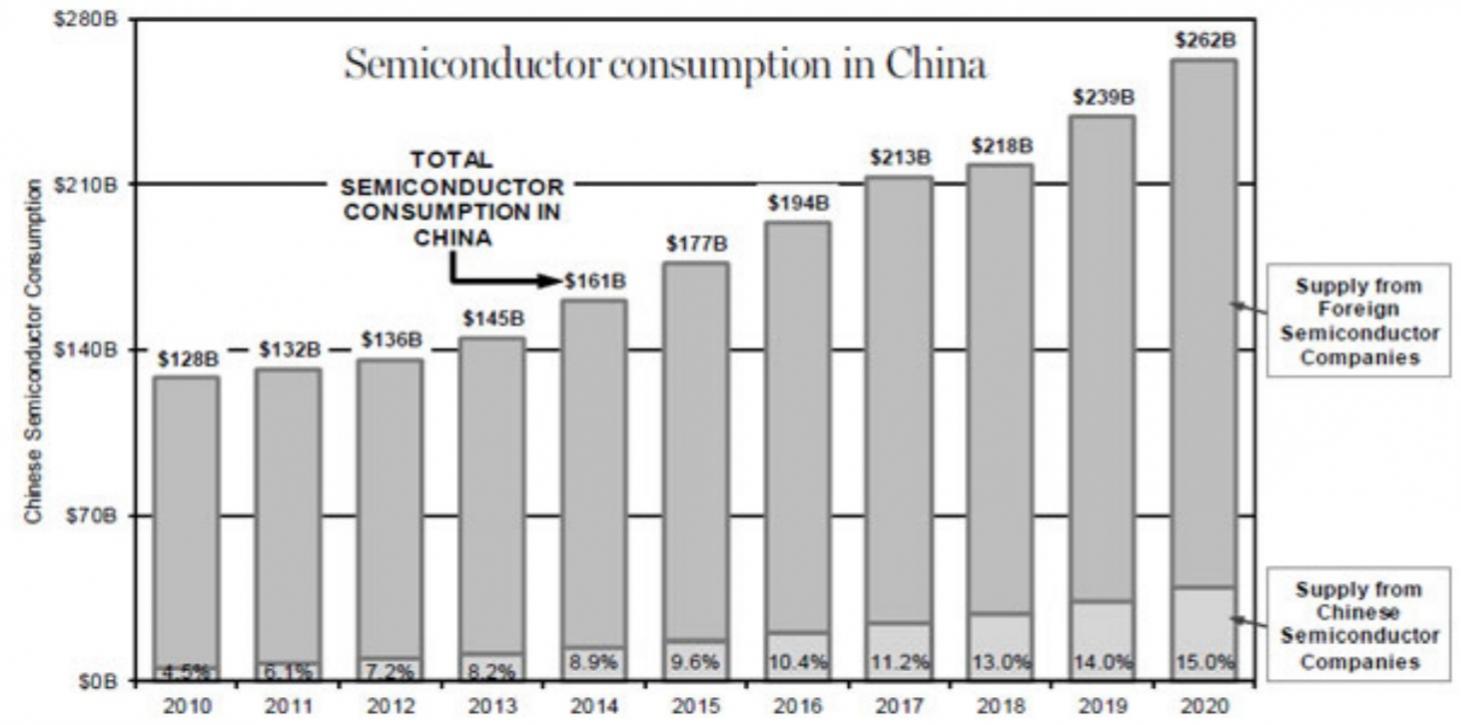
This joint CEVA and Open-Silicon webinar, moderated by myself, will elaborate on Narrowband IoT (NB-IoT) custom SoC solutions that are based on the CEVA-Dragonfly IP subsystem, and serve a wide range of cost- and power-sensitive IoT applications. Those joining the webinar will learn about the CEVA-Dragonfly NB1 IP subsystem, which pre-integrates the CEVA-X1 processor, optimized RF, baseband, and protocol software to offer a complete NB-IoT modem IP solution that can be extended seamlessly with GNSS and sensor fusion functionality.
Registration
Date: Tuesday, June 19, 2018
Time: 8 a.m. PST / 11 a.m. EST
Duration: 60 mins
The webinar will also address Open-Silicon’s NB-IoT custom SoC platform and software SDK, and how they enable customers to differentiate within the silicon with robust security and proprietary accelerator features with reduced risk, development schedule and cost.
The panelists will discuss the role of turnkey custom SoCs in lowering entry barriers, reducing time-to-market, increasing performance, adding security, and facilitating customization and scalability. The panelists will present sample use case platforms and explain how custom SoCs can enable product differentiation and total cost of ownership (TCO) savings for the next generation of NB-IoT applications.
This webinar is ideal for hardware designers and system architects of NB-IoT equipment/modules.
Speakers:
Emmanuel Gresset
Business Development Director, CEVA
Emmanuel is a Business Development Director in CEVA Wireless BU. For the last 30 years, Mr. Gresset has been with systems and semiconductor companies working in the fields of signal processing, wireless modems as well as processor and system-on-a-chip architecture in various companies: Octasic, STMicroelectronics, Philips, VLSI Technology, Spectral Innovations and Thomson. He received his M.Eng from the Ecole Supérieure d’Electricité in Paris.
Pradeep Sukumaran
Director, Systems & Software, Ignitarium
Pradeep Sukumaran is Director, Systems & Software at Ignitarium, a front-end design and software consulting company of Open-Silicon. Ignitarium offers high end VLSI and SW solutions to customers, with a strong focus on IoT and Vision Intelligence technology. Pradeep has over 17 years of experience in the embedded software and systems domain. Prior to Ignitarium, he was Senior Solutions Architect at Open-Silicon.
Naveen HN
Engineering Manager, Open-Silicon
Naveen HN is an engineering manager for Open-Silicon. He oversees board design, post-silicon validation and system architecture. He also facilitates Open-Silicon’s SerDes Technology Center of Excellence and is instrumental in the company’s strategic initiatives. He has over 16 years of experience in various domains of embedded systems design. Naveen is an active participant in the IoT for Smart City Task Force, which is an industry body that defines IoT requirements for smart cities in India. He received his M. Tech from SJCE, Mysore.
About CEVA, Inc.
CEVA is the leading licensor of signal processing platforms and artificial intelligence processors for a smarter, connected world. We partner with semiconductor companies and OEMs worldwide to create power-efficient, intelligent and connected devices for a range of end markets, including mobile, consumer, automotive, industrial and IoT. Our ultra-low-power IPs for vision, audio, communications and connectivity include comprehensive DSP-based platforms for LTE/LTE-A/5G baseband processing in handsets, infrastructure and machine-to-machine devices, advanced imaging and computer vision for any camera-enabled device, audio/voice/speech and ultra-low power always-on/sensing applications for multiple IoT markets. For artificial intelligence, we offer a family of AI processors capable of handling the complete gamut of neural network workloads, on-device. For connectivity, we offer the industry’s most widely adopted IPs for Bluetooth (low energy and dual mode) and Wi-Fi (802.11 a/b/g/n/ac/ax up to 4×4). To learn more, visit us at www.ceva-dsp.com
About Open-Silicon, Inc.
Open-Silicon transforms ideas into system-optimized ASIC solutions within the time-to-market parameters desired by customers. The company enhances the value of customers’ products by innovating at every stage of design — architecture, logic, physical, system, software and IP — and then continues to partner to deliver fully tested silicon and platforms. The company has partnered with over 150 companies ranging from large semiconductor and systems manufacturers to high-profile start-ups, and has successfully completed 300+ designs and shipped over 135 million ASICs to date. To learn more, visit www.open-silicon.com