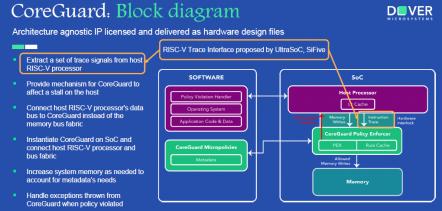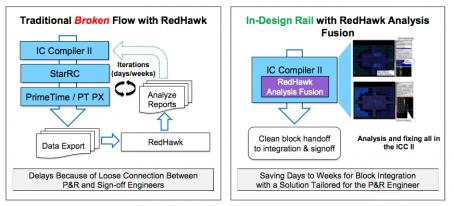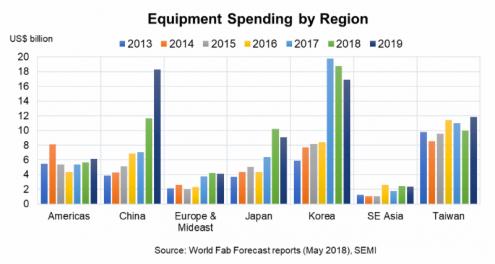
If integrating an embedded FPGA (eFPGA) into your ASIC or SoC design strikes you as odd, it shouldn’t. ICs have been absorbing almost every component on a circuit board for decades, starting with transistors, resistors, and capacitors — then progressing to gates, ALUs, microprocessors, and memories. FPGAs are simply one more useful component in the tool box, available for decades as standalone products, and now available for integration into your IC design using Achronix’s Speedcore eFPGA, supported by Achronix’s ACE design tools. These products allow you to easily incorporate the performance and flexibility of programmable logic into your next ASIC or FPGA design.
The questions then become: Why would you want to do that? Why use an FPGA at all? Why put a programmable fabric in your ASIC or SoC?
Why FPGAs?
System-level designers employ FPGAs for many reasons, but the two main ones are performance and flexibility. Many tasks executed in software running on a processor benefit from significant performance improvements when implemented in hardware. When designing ASICs and SoCs, however, there’s a fork in the hardware path. If you’re absolutely certain that there will never be any changes in the associated algorithms, then freezing the functionality into ASIC gates makes sense.
These days, not much seems that stable. Standards change. Market needs change. If you’ve frozen the wrong algorithm in ASIC gates, you’ll need to respin your chip.
To mitigate the risks associated with ASIC gates, system designers have relied on FPGAs for decades to execute algorithms at hardware-level processing speeds with the flexibility to change the algorithm in milliseconds (or less). Pairing an application processor or microcontroller with an FPGA on a circuit board is now common design practice. The FPGA accelerates tasks that need it.
Moving the Programmable Fabric into the ASIC
However when the application processor and the FPGA are in separate chips, communications between the two represent a major bottleneck. No matter how fast the communications between the two devices, the FPGA is always logically “far away” from the processor, as Achronix’ Kent Orthner describes in the video:
For example, PCIe has become a common protocol for connecting processors with FPGAs on a circuit board. While PCIe is a high-speed serial protocol, featuring fast data transfer, there’s additional latency to serialize the data, transmit it, and then deserialize it. In practice, the hardware latency is on the order of 1 microsecond, but with Linux overhead, that latency can be an order of magnitude larger or more. Consequently, the accelerated algorithm must be meaty enough in terms of processing time and processed data size to overcome this latency.
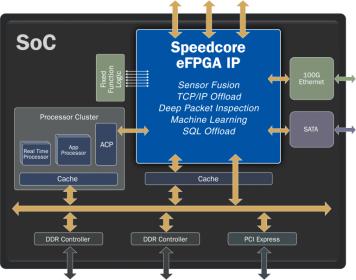
Embedding an FPGA into your ASIC or SoC solves this bottleneck. You can instantiate as much connectivity between the on-chip processor(s) and the FPGA(s) as required by your application. For example, many SoC designs couple ARM processor cores to other on-chip hardware using AXI buses. You can easily use a 128-bit AXI bus to connect a complex of processors to an eFPGA. But why stop there? If your application requires more bandwidth, you can use two, four, or more 128-bit AXI buses to drive multiple accelerators instantiated in the eFPGA(s).
There’s another, more subtle reason why eFPGAs outperform discrete processor/FPGA implementations. Because the FPGA is “far away” from the processor, it must usually have its own DDR SDRAM to buffer large data blocks. This need to buffer means that the processor or a DMA controller must move the data to be processed from the application processor’s DDR memory to the FPGA’s DDR memory. Then, the processed data must be transferred from the FPGA’s DDR memory to the processor’s DDR memory. Depending on the amount of data to be transferred, the delay incurred by these data transfers falls somewhere between a long, long time and forever (from a hardware-level speed perspective).
Giving the on-chip eFPGA direct access to the processor’s DDR memory means that data does not need to be buffered. The transfer becomes nothing more than passing a memory pointer to the eFPGA so that it can immediately start processing. When the eFPGA completes its work, it passes a memory pointer back to the processor for any additional handling.
Where might these eFPGA qualities be useful? Here are three application examples to whet your imagination:
- Wireless/5G – No industry is in more flux at the moment that the telecom industry. The 5G specifications are constantly being updated while telecom providers are doing what they can to extract the most out of installed 4G infrastructure equipment. In addition, telecom equipment must meet stringent size, weight, and power requirements. All of these factors argue in favor of SoCs with eFPGAs to provide instant flexibility while reducing equipment size, power, and weight.
- Fintech/High-Frequency Trading – As discussed above, eFPGAs reduce latency. In the high-frequency trading world, cutting latency by a microsecond can be worth millions of dollars. That alone is more than enough justification for developing SoCs with on-chip eFPGAs to handle the frequently changed trading algorithms.
- Artificial Intelligence/Machine Learning (AI/ML) Inference and CNNs – Convolutional Neural Network (CNN) inference algorithms rely heavily on multiply/accumulate operations and programmable logic. Speedcore eFPGAs can significantly accelerate such algorithms using the massive parallelism made possible by including a large number of programmable DSP blocks in your eFPGA specification.
These are just three examples demonstrating how eFPGAs can enhance an ASIC’s or SoC’s performance and capabilities. If you would like to explore other ways your ASIC or SoC design might benefit from a performance-enhancing, on-chip FPGA, visit www.achronix.com/product/speedcore/.