My IC design career started out with circuit design of DRAMS, so I got to quickly learn all about transistor-level design at the number one IDM in the world, Intel at the time. In the early days, circa 1978 we circuit designers actually had few EDA tools, mostly a SPICE circuit simulator followed by manual extraction, manual netlisting, manual layout, manual DRC, and of course, manual transistor sizing. In 2018 the scene has changed for the better because EDA companies have offered up lots of point tools to eliminate all of that manual, error-prone work that I had to grok through in the 1970’s.
I’ve been reading up on a new EDA company focused on automating some of the analog IC design challenges, and wanted to blog about it here to share what’s new and different at Intento Design, a company that I visited at #55DAC last month in SFO. The tagline at Intento Design is, “Responsive EDA for Analog IP”. For web sites I know what responsive design means, but for the phrase responsive EDA I needed to dig a bit deeper. A recent press releasefrom June 7th revealed that STMicroelectronics is using a tool called ID-Xplore on their FDSOI circuits in the Aerospace Defense & Legacy Division for:
- Design exploration
- IP reuse
- Use in a Cadence environment
- Technology independent constraints
OK, that sounds great, but how does ID-Xplore actually work?
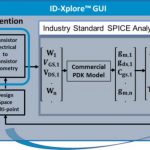
Here’s a tool flow diagram to explain what goes into and out of IC-Xplore:
The SPICE analysis portion in the middle immediately caught my eye, yet the company isn’t offering a SPICE circuit simulator, instead they are using SPICE-accurate analysis to help size transistors from a traditional schematic tool like Virtuoso from Cadence. A popular brute-force approach to transistor sizing is to run lots of transient SPICE circuit simulations during the process, which consumes lots of SPICE licenses, but that’s not the Intento approach at all.
With ID-Xplore you first create your transistor-level schematic and then add an intention view, something that every analog circuit designer already has in their head because they know the intention of each circuit block in their libraries along with the specifications and requirements. A Test Bench is another input to ID-Xplore along with PDK models from your foundry.
Analog designers are now ready to invoke ID-Xplore and the tool will help them:
- Verify that the selected parameters meet the DC bias specification
- Start sizing transistors to meet the intention view
- Explore new values of electrical parameters
ID-Xplore comes with a GUI so that circuit designers can visualize performance results, or even see back-annotation of transistor size parameters used in OpenAccess. During exploration you can see a whole range of design curves, or performance profiles as shown below which include sensitivity numbers:
Earlier I talked about the intention view, so let’s dive a bit deeper into that new step. If your analog circuit contains a differential pair, then you click in the schematic and add that intention Likewise, if you need a regulating clamp voltage then specify that intention. Analog designers carry these intentions in their head, and now they have a tool to add them to their schematic as part of an automated tool flow, thus capturing their intention and experience as part of the IP creation process. The ID-Xplore tool takes all of these intentions that are defined by the circuit designer as constraints in a problem that needs to be solved, then uses a SPICE-accurate analysis tool to solve and produce results for analysis.
Cadence Constraint Manager
Related blog – The Intention View: Disruptive Innovation for Analog Design
What else can ID-Xplore help me automate? How about technology porting of analog circuits to a new foundry process model. This works because your initial schematic in Virtuoso can re-load with a new PDK, then the designer can adjust constraints like new PDK choice and supply values. All of your old constraints can be re-used or even updated while porting to a new technology. You can actually port circuits in one afternoon, not days or weeks, wow. FinFET, FDSOI, BD, Bipolar and CMOS technologies are supported by ID-Xplore.
You can probably imagine that a tool like ID-Xplore can create hundreds of different sized schematics quickly, giving you quite a range to choose from in meeting your specifications. There’s plenty of visualization to help pick out your favorite results using the N-Viewer tool, shown below where each green dot represents a sized schematic that meets specs while a red dot is a failed sized schematic:
N-Dimensional Viewer. Red is failing, green is passing.
Related blog – CEO Interview: Ramy Iskander of Intento Design
Another manual task that is automated with ID-Xplore is the concept of centering a circuit design across PVT corners. The analysis in ID-Xplore can be quickly visualized with N-Viewer across PVT conditions, so that the circuit designer can choose what they prefer in terns of which sized schematic best meets the specs across corners.
Summary
I hope that you picked up on all of the cool new automation features now available from Intento Design:
- Explore circuit sizing on cells or blocks
- Explore around your DC bias plan
- Evaluating PDK version changes and how they impact each analog circuit
- Explore your analog cells exhaustively
- Confirm or tune hand-sizing results
- Quickly creating block-size estimates versus performance
- Train other analog designers about the intention of each of your analog circuits
- Explore biases and sizing sensitivity