
In December 2021, just weeks before Verizon and AT&T were set to enable their new radio access networks in the 5G mid-band spectrum (also known as C-Band), the Federal Aviation Administration (FAA) released a Special Airworthiness Information Bulletin (SAIB) and a statement notifying operators of potential 5G interference to radar altimeters. This 11th hour directive initially caused chaos in the United States aviation industry as airline executives warned of mass flight cancellations for both passenger and cargo flights.
Verizon and AT&T initially agreed to a couple of short delays to the activation of their new 5G service towers while the FAA and FCC tried to better understand the issues. Ultimately, Verizon and AT&T, who combined spent over almost $95 billion for the C-band midband spectrum, agreed to restrict their 5G deployments until July 5, 2022. Then, on June 17, 2022, the FAA announced that both carriers had voluntarily agreed to continue some restrictions until July 2023 to allow more time for the aviation industry to retrofit the necessary airplanes.
Throughout this time, the FAA has been diligently working with both the telecommunication companies and the aviation industry. Over 90% of the U.S. commercial aircraft fleet has been cleared for most low-visibility approaches in 5G deployment areas. Additionally, 99% of the affected airports have received approval for at least 90% of aircraft models to land in low-visibility approaches. Palm Springs International Airport is the only outlier with only 68% of aircraft models approved for low visibility approaches.
The FAA is pushing the airline industry to replace and retrofit the remaining 10% of radio altimeters that are at risk of interference from the C-Band 5G wireless service. This could require adding improved RF filtering to the radio altimeters or updating older altimeters to newer models which already have improved filtering and performance. The parties will take a phased approach with the hope of upgrading most aircraft by the end of 2022 and all aircraft by July 2023.
For additional background information, see Ansys’ earlier blog entries:
- 5G and Aircraft Safety: How Simulation Can Help to Ensure Passenger Safety
- 5G and Aircraft Safety Part 2: Simulating Altimeter Antenna Interference
- 5G and Aircraft Safety Part 3: How Simulation Can Validate Interference Scenarios
Future Considerations
While the parties have come together to avoid disaster, this instance highlights an ever-growing problem with potentially billions of dollars at stake in both the U.S. and internationally. There is already incredible demand for the limited spectrum and as the world becomes ever more connected, this demand will only increase. New sectors as wide ranging as industrial Internet of Things (IoT), private 5G networks, unmanned aerial vehicles, remote sensing, personal health networks and intelligent transportation systems will all compete for this limited resource with existing stakeholders such as the commercial aviation industry, maritime communications, TV broadcasting and more.
Some studies have found that use of spectrum in countries with advanced information and communication technologies has enabled an increase in GDP of 3.4%. Thus, it is imperative for stakeholders to ensure that they are efficiently using the spectrum allocated to them while also minimizing interactions with neighboring frequency bands. While EUROCONTROL found that the risk of 5G interference to radio altimeters in Europe was lower than that in the U.S., due to lower maximum power restrictions in Europe and an operating band (3.4-3.8 GHz) that is further from the radio altimeter band (4.2-4.4 GHz), it did find that the aviation industry does not make efficient use of its spectrum and can improve its process for developing new communication, navigation and surveillance (CNS) technologies.
A key recommendation of EUROCONTROL is to improve the adjacent band filtering. As the Radio Technical Committee for Aeronautics (RTCA) found, this poor adjacent band filtering had an outsized role in determining the performance of radio altimeters in the presence of 5G C-Band radios. Many of the altimeters in use today were developed decades ago, when the mid C-band frequencies were used for low power satellite applications which were a minimal risk to the altimeters.
Long product cycles, 20-30 years for many aircraft, also makes it hard to perform CNS upgrades and the aviation industry should not skip incremental improvements while waiting for a dramatic leap in technology. Spectrum inefficiencies can be very costly in the long run and frequency congested systems can limit air traffic growth as we’ve seen with VHF COM in the past.
How Simulation Tools Could Help
These issues can be avoided with the help of simulation tools such as Ansys EMIT and the AGI System Toolkit (STK) which can predict and quantify these interference effects in dynamic scenes including flight paths and platform motion, and provide guidance for mitigation. Ansys AGI STK provides dynamic scene orchestration and platform motion physics for vehicles on land, air, sea and space, and is useful for considering flight paths and aircraft motion behavior impacts on sensor and antenna positioning during landing and takeoff sequences. The Ansys Electromagnetic Interference Toolkit (EMIT) is an integral component of the Ansys Electronics Desktop and part of the Ansys HFSS portfolio. EMIT is designed to consider wideband transmitter emissions and assess their impact on wideband receiver characteristics. Its detailed results analysis capabilities enable users to quickly determine design requirements for any adjacent band filters.
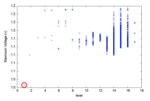
Let’s examine the results for the second phase of the C-Band service rollout in the 100 MHz band from 3.7-3.8 GHz. Figure 3 shows the result of our investigation. The black curve gives us a view of what is going on in the receiver and measures the difference between the transmitted power at each frequency and the receiver’s ability to reject that energy (receiver susceptibility). If this value goes above zero (shown by the red line), we have an interference event because the receiver can’t reject that level of energy at that frequency. We can also set threshold values to warn us if we are getting close to an interference event, such as the yellow line at -6 dB. This is important due to the dynamic environment that communications equipment is typically operated in. Aircraft takeoff and landing can be especially dynamic due to the low altitude and the higher probability of multipath from nearby buildings and ground reflections.
The plot in Figure 3 suggests that the 5G transmitter fundamental is strong enough to potentially saturate the front end of some radio altimeters. While this exact result is specific to the details of this simulation, to mitigate the risk, a bandpass or high pass filter could be added inline with the radio altimeter to better attenuate these near-band frequencies.
The filter can then be designed and synthesized using the Ansys Nuhertz FilterSolutions software and the results then added to your simulation to verify the performance and ensure that the interference was sufficiently mitigated.
Simulation tools can also help regulating agencies with spectrum planning. This will be critical in the coming years as airlines look to increase capacity at existing airports, necessitating the need for more channels between the aircraft and air traffic control. Before additional frequencies can be assigned for use at an airport, it needs to be verified that they won’t interfere with and overlap with the bands used at other, nearby airports. As seen in Figure 6, EMIT’s Spectrum Utilization Toolkit enables users to quickly determine if a new allocation will overlap existing frequency bands.
Frequency planning tools that are accurate, efficient and easy to use can assist regulators and the wireless telecommunications industry in allocating frequency spectrum. Systems operating in adjacent bands are easily identified, informing stakeholders of potential new sources of interference and enabling them to perform a more thorough analysis to determine if additional mitigation measures are required or quickly deciding that a particular allocation will not work as expected.
Also Read:
Ansys’ Emergence as a Tier 1 EDA Player— and What That Means for 3D-IC
What Quantum Means for Electronic Design Automation
The Lines Are Blurring Between System and Silicon. You’re Not Ready





{kind=link}
{kind=link}