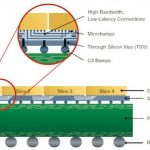
One of TSMC’s two big Silicon Valley events each year is the Open Innovation Platform (OIP) Forum. This year it is on Tuesday October 1st. It is in the San Jose Convention Center and starts at 9am (registration opens at 8am). Pre-registration to attend is now open here or click on the image to the right.
From 9.10 to 9.40 is the TSMC keynote and then from 9.40 to 10.10 is a presentation on TSMC and its Ecosystem for Innovation.
After a coffee break, the rest of the day is in three parallel tracks: EDA, IP and a services track that also contains little leavening of EDA and IP too. The big guns are all there: Cadence, Synopsys, Mentor and ARM are all presenting. Smaller companies such as iRocTech and Sidense are also there. The complete program is below.
[TABLE] cellpadding=”4″ style=”width: 97%”
|-
| align=”center” style=”width: 15%” | [TABLE] cellpadding=”10″ style=”width: 100%”
|-
| align=”center” |
|-
| width=”27%” align=”center” | EDA Track
| width=”29%” align=”center” | IP Track
| width=”29%” align=”center” | EDA/IP/Services Track
|-
| 10:30 – 11:00
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Managing wire resistance, cell pin access and FinFET parasitics at TSMC 16nm using Cadence place & route and RC extraction technologies
|-
| valign=”top” align=”center” | Cadence
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Key Design Practices in IP Development of 28G SerDes Design in TSMC 28nm
|-
| valign=”top” align=”center” | Semtech/Snowbush
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Power islets: design methodology and innovative silicon IPs to solve the construction quandary
|-
| valign=”top” align=”center” | Dolphin Integration
|-
|-
| 11:00 – 11:30
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Design Reliability with Calibre Smart-Fill and PERC
|-
| valign=”top” align=”center” | Broadcom & Mentor Graphics
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | 16G multi-standard SERDES IP in TSMC 16nm FinFET process
|-
| valign=”top” align=”center” | Cadence
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Design and implementation of high resolution 60GHz PLLS and DCOs using the EMX 3D EM simulator
|-
| valign=”top” align=”center” | Integrand Software
|-
|-
| 11:30 – 12:00
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | TSMC 16nm FinFET SRAM Design Verification
|-
| valign=”top” align=”center” | Synopsys
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Hybrid Embedded NVM Solution for Flexbile Product Design and Application
|-
| valign=”top” align=”center” | eMemory
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Soft-Error Testing at Advanced Technology Nodes
|-
| valign=”top” align=”center” | GUC
|-
|-
| 12:00 – 13:00
| colspan=”3″ valign=”top” align=”center” | Lunch
|-
| 13:00 – 13:30
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Addressing Custom Design Challenges for IP Design at 16nm FinFET technology
|-
| valign=”top” align=”center” | Cadence
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Optimizing Cortex-A57 for TSMC 16nm FinFET
|-
| valign=”top” align=”center” | ARM
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | An Efficient and Accurate Sign-Off Simulation Methodology for High-Performance CMOS Image Sensors
|-
| valign=”top” align=”center” | Berkeley Design Automation & Forza Silicon
|-
|-
| 13:30 – 14:00
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | A Synergetic, Multi-Partner, Soft Error Rate Analysis Framework For Latest Process Nodes
|-
| valign=”top” align=”center” | iROC
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Kilopass NVM OTP IP Roadmap for TSMC ‘s Most Advanced Processes
|-
| valign=”top” align=”center” | Kilopass
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Design and modeling platform for the TSMC’s FOWLP Reference Design Kit
|-
| valign=”top” align=”center” | Agilent
|-
|-
| 14:00 – 14:30
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | EDA-Based DFT for 3D-IC Applications
|-
| valign=”top” align=”center” | Mentor Graphics
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | The Impact Of FinFET Technology On Physical IP Development, Design Styles and Performance
|-
| valign=”top” align=”center” | Synopsys
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Case study of 28nm option selection for wireless baseband co-processor
|-
| valign=”top” align=”center” | IMEC
|-
|-
| 14:30 – 15:00
| colspan=”3″ align=”center” | Coffee Break
|-
| 15:00 – 15:30
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Advanced Power, Signal and Reliability Verification for 20nm, 16nm FinFET, and 3D-IC Designs
|-
| valign=”top” align=”center” | ANSYS Apache
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | ARM POP IP Accelerating Time-to-PPA in Mainstream Mobile
|-
| valign=”top” align=”center” | ARM
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Synopsys Laker Custom Layout and Calibre Interfaces: Putting Calibre Confidence in Your Custom Design Flow
|-
| valign=”top” align=”center” | Mentor Graphics
|-
|-
| 15:30 – 16:00
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Low Power and Faster Timing ECO for sub-20nm Designs
|-
| valign=”top” align=”center” | Dorado Design Automation
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | A highly configurable and robust memory subsystem for multi-core SOCs in advanced TSMC process nodes
|-
| valign=”top” align=”center” | Cadence
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Implementing Secure SOC Devices
|-
| valign=”top” align=”center” | Analog Bits
|-
|-
| 16:00 – 16:30
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | FinFET modeling and extraction solution for TSMC’s advanced 16-nm process
|-
| valign=”top” align=”center” | Synopsys
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Design Optimization Kits: Complete Physical IP Solution for Optimizing CPU and GPU Core Implementations in TSMC 28HPM Process
|-
| valign=”top” align=”center” | Imagination Technologies & Synopsys
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Electrostatic Discharge (ESD) protection guidelines for 40nm, 28nm and 20nm CMOS designs
|-
| valign=”top” align=”center” | Sofics
|-
|-
| 16:30 – 17:00
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Advanced Chip Assembly & Design Closure Flow Using Olympus-SoC
|-
| valign=”top” align=”center” | Mentor Graphics & nVIDIA
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | An Antifuse-based Non-Volatile Memory for Advanced Process Nodes and FinFET Technologies
|-
| valign=”top” align=”center” | Sidense
|-
| valign=”top” align=”center” | [TABLE] cellspacing=”3″ style=”width: 100%”
|-
| valign=”top” align=”center” | Circuit Reliability Simulation with TSMC TMI Age Model
|-
| valign=”top” align=”center” | Cadence
|-
|-
| 17:00 – 18:00
| colspan=”3″ align=”center” | Networking and Social Hour
|-
TSMC created the semiconductor Dedicated IC Foundry business model when it was founded in 1987. TSMC served more than 600 customers, manufacturing more than 11,000 products for various applications covering a variety of computer, communications and consumer electronics market segments. Total capacity of the manufacturing facilities managed by TSMC, including subsidiaries and joint ventures, reached 15.1 million eight-inch equivalent wafers in 2012. TSMC operates three advanced 12-inch wafer GIGAFAB™ facilities (fab 12, 14 and 15), four eight-inch wafer fabs (fab 3, 5, 6, and 8), and one six-inch wafer fab (fab 2). TSMC also manages two eight-inch fabs at wholly owned subsidiaries: WaferTech in the United States and TSMC China Company Limited, In addition, TSMC obtains 8-inch wafer capacity from other companies in which the Company has an equity interest.
TSMC’s 2012 total sales revenue reached a new high at US$17.1 billion. TSMC is headquartered in the Hsinchu Science Park, Taiwan, and has account management and engineering service offices in China, Europe, India, Japan, North America, and, South Korea.