As I have mentioned before, I’m part of the Coleman Research Group so you can rent me by the hour to better understand the semiconductor industry. Most of the conversations are by phone but sometimes I do travel to the East Coast, Taiwan, Hong Kong, and China for face-to-face meetings. Generally the calls are the result of an event that needs further explanation or just a quarterly update. Again, as an active semiconductor professional I share my experiences, observations, and opinions so rarely will I agree with the analysts or journalists who rely on Google for information.
In 2003, Kevin Coleman founded Coleman Research to give investors a better way to access industry knowledge. Coleman helps thousands of clients get answers to their most critical questions, without leaving their desks. Rather than spending hours reading research reports, or traveling to meet people at conferences, we connect clients directly with industry experts, to hear immediate, relevant insights.
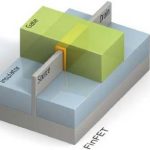
The Intel analyst meeting last November was full of surprises and resulted in a series of phone consultations. The Intel 14nm superior density claim slides were the most talked about and were absolutely crushed by TSMC, which I wrote about in “TSMC Responds to Intel 14nm Density Claims”. The other slide that caused a flurry of calls is the one above comparing Altera and Xilinx planar to FinFET. After talking to dozens of people (including current and former Altera, Intel, and Xilinx employees) I have concluded that this slide is an absolute fabrication. Get it? Fabrication? Hahahahaaaa….
I did a comparison of the Altera and Xilinx analyst meetings and found the slide above which supports my point. Clearly silicon does not lie so when the competing FPGA FinFET versions are released we will know for sure, but my bet is that Altera/Intel will lose this one. It also goes to my point that the transistor is not everything in modern semiconductor design and Intel’s claims of process superiority are a paper tiger when it comes to finished products.
There are thousands of FPGA and semiconductor process professionals reading SemiWiki so I’m hoping for a meaningful discussion in the comments section. If any of you would like to post a rebuttal blog I’m open to that as well. SemiWiki is an open forum for the greater good of the fabless semiconductor ecosystem, absolutely.
The most recent event that caused a flurry of calls was the JP Morgan Report: Meetings at MWC – Intel Mobile Effort Largely a Side Show, but Some Problems in Foundry a Concern. The press really had a field day with this one:
Some issues popping up with foundry business – we are concerned.Ourchecks indicate there have been some problems with Intel’s foundry effortscentered on design rules and service levels. It appears Intel is being inflexibleon design rules and having trouble adapting to a service (foundry) model. Our J.P. MorganFoundry analyst, Gokul Hariharan wrote today that Altera has re-engaged TSMC.
This resulted in a handful of tabloid worthy articles taking the JP Morgan report completely out of context:
Altera to switch 14nm chip orders back to TSMC, says paper Commercial Times, March 4; Steve Shen, DIGITIMES [Wednesday 5 March 2014]
While I appreciate the consulting business this generated I really do question the motives of Steve Shen. The first “Altera leaving Intel” rumor started HERE and I’m sure this won’t be the last but I’m still not buying it and neither should you.