
Just like good ideas percolate longer, we have seen AI adoption pace picking-up speed, propelled by faster GPUs. Some recent data points provide good indication that FPGA making a comeback to bridge chip-design needs to keep-up with AI’s ML applications.
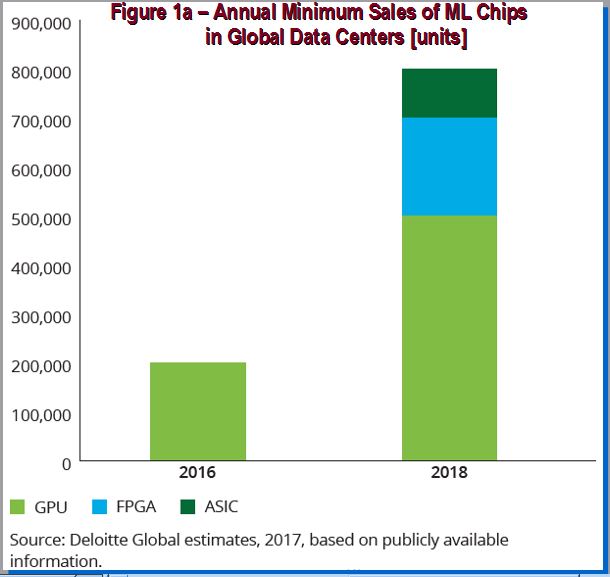
According to the Deloitte research firm there is a projected increase of ML chips using FPGA, GPU and ASIC implementations in 2018 (refer to Figure 1a). There are more collaborative efforts between FPGA makers Intel, Xilinx and cloud providers in addressing neural networks implementation or ML algorithms.
Let’s take a closer look how FPGA plays a role in the AI space. This year CASPArolled-out a sequel to its last year symposium related to AI and Semiconductor Fusion. Several Silicon Valley technology experts and leaders representing large companies (Intel, IBM, Rambus, Starkey) and startups (SiFive, ADS) shared their perspectives on AI current impacts and its projected trajectories within their respective domains.
Few takeaways from this symposium:
– FPGA seems to be gaining tractions in supplementing GPUs horsepower for running AI based algorithms.
-Just like Moore’s Law on design density was challenged few years ago, it is likely that the Von-Neumann Architecture (VNA) may face similar challenge as design teams explore new techniques to resolve computing performance and bandwidth bottlenecks.
-A preview of humanizing AI application into the medical wearable device, closer to the left-end of the intelligence spectrum, the human brain.
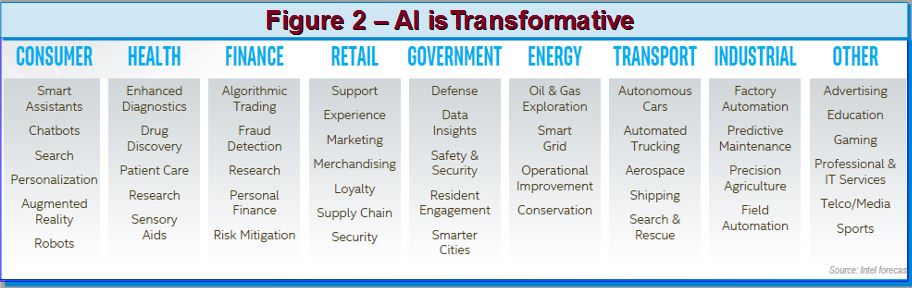
Vincent Hu, Intel’s VP of Strategy Innovation and Planning, whose charter includes assisting Intel’s CTO office and driving the FPGA roadmap for Intel’s Programmable Solutions Group (formerly Altera), outlined how AI is transforming industries and generating data-increase driving dynamics (refer to Figure 2).
His take on Intel’s recent second pivot is data centric in nature, replacing the first one which was evolving around processor and memory.
Furthermore, our need of FPGA is stemmed from the increased programmability of software coupled with performance demand of hardware. One major projected application is related to the 5G migration requiring high bandwidth plus many programmable components (DSP/MIMO/Security). China deployment is expected to be in early 2020. To this end, FPGA provides deterministic system latency. It can leverage parallelism across the entire chip, reducing the compute time to a fraction and bringing system latency (i.e., I/O latency + compute latency) to reasonable level allowing high-throughput.
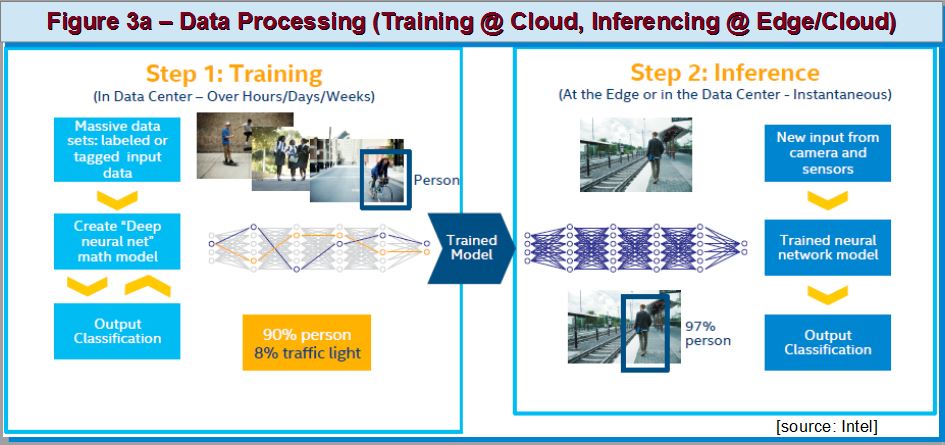
In what context does FPGA fit into the AI ecosystem? Let’s consider two major aspects in AI’s deep learning (DL) process, commonly narrated when one is covering ML/DL: training and inferencing steps. The former still requires heavy cloud infrastructure comprised of Xeon based power-servers while the FPGA boxes focuses on inferencing (Figure 3a).

His counterpart, Dr. Wei Li, Intel’s VP of Software and Services Group and GM of Machine Learning and Translation, highlighted the complete Intel’s AI ecosystem that provides scalability and the advanced analytics necessary to power AI (Figure 3b). The growth for AI compute cycles is anticipated to be 12x by 2020. AI accelerators such as Intel’s Nervana neural network processors are utilized in the cloud and data center. Libraries and frameworks were hardware optimized as AI performance is based on the sum of software and hardware throughputs. As a point of comparison, a Xeon platinum based server alone offers 2.2X performance improvement versus its predecessor, but a 113X better if software speed-up is included. Both inference and training throughputs improved by over two order of magnitude with the most recent Xeon Platinum based processors.
In order to scale deep learning to multi-node, a three-prong approach is applied:
[LIST=1]
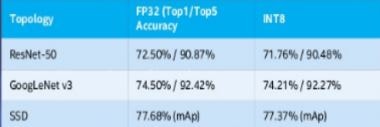 In tabulated comparison on the left, Intel XEON’s INT8 designated for deep learning inferencing has lower response time, higher throughput and less memory, producing little accuracy loss compared with single precision floating point (FP32).
In tabulated comparison on the left, Intel XEON’s INT8 designated for deep learning inferencing has lower response time, higher throughput and less memory, producing little accuracy loss compared with single precision floating point (FP32).
The scaling trend keeps increasing: from the initial 32/64 (Google-Net) nodes to 256 CPU nodes (Barcelona Supercomputing Center Marenostrum4) with a 90% scaling efficiency, and recently UC Berkeley used 1600 Skylake CPU nodes and Layer-wise Adaptive Rate Scaling (LARS) algorithm to outdo Facebook’s prior results by finishing a time-to-train (TTT) of ResNet-50 in 32 minutes (AlexNet in 11 minutes) and with much higher accuracy. To show how elastic Intel’s Xeon based application, he pointed out researchers utilized Amazon 1.1 Million nodes for topic modeling (Clemson University). Company such as Facebook also leverage deep learning training during off-hours to gain compute capacity.
[Part 1 of 2]To continue reading, please refer to [Part 2 of 2]
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.