
Keeping up with competitors in many computing applications today means incorporating AI capability. At the edge, where devices are smaller and consume less power, the option of using software-powered GPU architectures becomes unviable due to size, power consumption, and cooling constraints. Purpose-built AI inference chips, tuned to meet specific embedded requirements, have become a not-so-secret weapon for edge device designers. Still, some teams are just awakening to the reality of designing AI-capable chips and have questions on suitable AI architectures. Ceva recently hosted a webinar featuring two of its semiconductor IP experts, who discussed ideas for creating a future-proof AI architecture that can meet today’s requirements while remaining flexible to accommodate rapid evolution.
A broader look at a wide-ranging AI landscape
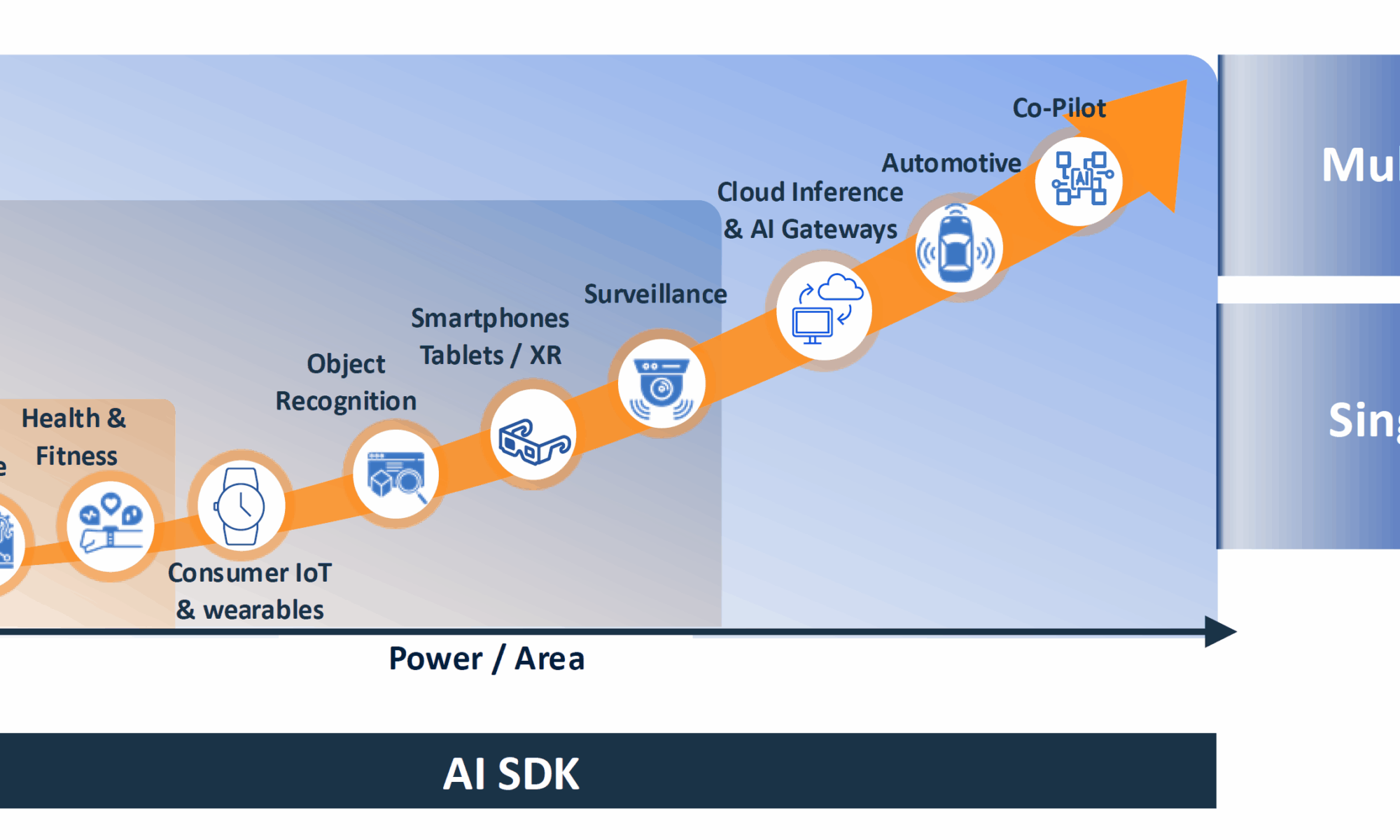
AI is an enabling technology that powers many different applications. The amount of chip energy consumption and area designers have to work with to achieve the necessary performance for an application can vary widely, and, as with previous eras of compute technology, the roadmap continues to trend toward the upper right as time progresses. Ronny Vatelmacher, Ceva’s Director of Product Marketing, Vision and AI, suggests the landscape may ultimately include tens of billions of AI-enabled devices for various applications at different performance levels. “The cloud still plays a role for training and large-scale inference, but real-time AI happens at the edge, where NPUs (neural processing units) deliver the required performance and energy efficiency,” he says.

At the highest performance levels in the cloud, a practical AI software framework speeds development. “Developers today don’t have to manage the complexity of [cloud] hardware,” Vatelmacher continues. “All of this compute power is abstracted into AI services, fully managed, scalable, and easy to deploy.” Edge devices with a moderate but growing performance focus prioritize the efficient inferencing of models, utilizing techniques such as NPUs with distributed memory blocks, high-bandwidth interconnects, sparsity, and coefficient quantization to achieve this goal. “[Generative AI] models are accelerating edge deployment, with smaller size and lower memory use,” he observes. Intelligent AI-enabled edge devices offer reduced inference latency while maintaining low power consumption and size, and can also enhance data privacy since less raw data moves across the network. Vatelmacher also sees agentic AI entering the scene, systems that go beyond recognizing patterns to planning and executing tasks without human intervention.
How do chip designers plan an AI architecture to handle current performance but not become obsolete in a matter of 12 to 18 months? “When we talk about future-proofing AI architectures, we’re really talking about preparing for change,” Vatelmacher says.
A deep dive into an NPU architecture
The trick lies in creating embedded-friendly NPU designs with a smaller area and lower power consumption that aren’t overly optimized for a specific model, which may fall out of favor as technology evolves, but rather in a resilient architecture. Assaf Ganor, Ceva’s AI Architecture Director, cites three pillars: scalability, extendability, and efficiency. “Resource imbalance occurs when an architecture optimized for high compute workloads is forced to run lightweight tasks,” says Ganor. “A scalable architecture allows tuning the resolution of processing elements, enabling efficient workload-specific optimization across a product portfolio.” He presents a conceptual architecture created for the Ceva-NeuPro-M High Performance AI Processor, delving deeper into each of the three pillars and highlighting blocks in the NPU and their contributions.

Ganor raises interesting points about misleading metrics. For instance, low power does not necessarily equate to efficiency; it might instead mean low utilization. Inferences per second (IPS) by itself can also be deceptive, without normalization for silicon area or energy used. He also emphasizes the critical role of the software toolchain in achieving extensibility and discusses how NeuPro-M handles quantization and sparsity. Some of the ideas are familiar, but his detailed discussion reveals Ceva’s unique combination of architectural elements.
The webinar strikes a good balance between a market overview and a technical discussion of future-proof AI architecture. It is a refreshing approach, taking a step back to see a broader picture and detailed reasoning about design choices. There’s also a Q&A segment captured during the live webinar session. Follow the link to register and view the on-demand webinar.
Ceva Webinar: What it really takes to build a future-proof AI architecture?
Also Read:
Podcast EP291: The Journey From One Micron to Edge AI at One Nanometer with Ceva’s Moshe Sheier
Turnkey Multi-Protocol Wireless for Everyone
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.