

Very rarely does the FPGA designer, especially with respect to RADAR, think of the FPGA as a floating point processor. Just to be sure I asked my 6 year old and she agreed. But you know what, the Xilinx FPGAs float. Go try it, order some up and fill up the tub.
Anyways I purpose a duel to the avid VHDL coder. I want you to design me a Sine(x) function in VHDL, you provide X and the output will be the angle in radians. It must have the answer within 32, 150MHz clocks and have single precision floating point. It also needs to be pipelined, thus after the 32 clocks, the data will continually be produced provided there is an input every clock cycle which will keep the pipe full.
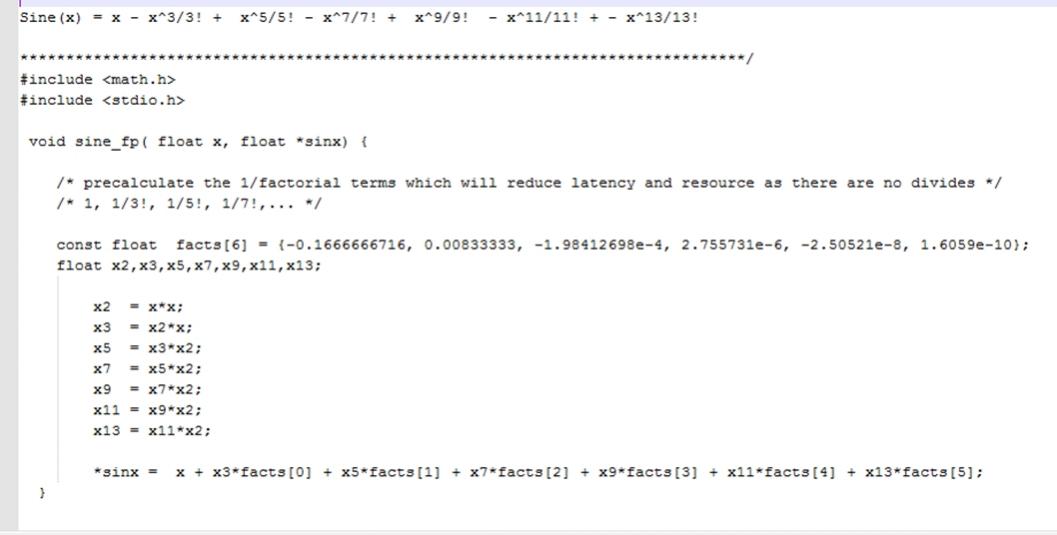
So how long would that take you? Well I did this very experiment and used Xilinx’s Vivado HLS and was done in about 10 minutes and that includes my son’s diaper change. I used the Taylor Series expansion out to the 13[SUP]th[/SUP] term. I removed all the factorial divides by using LUT’s to store the 1/3!, 1/5! … terms. What we are left with is the very simple code below:

What’s even grander is I did not have to run like a 100 RTL simulations to verify my design. Why? Because since the input to HLS is C/C++, you are running an executable that completes in a second to verify your math. Think about it, why do you run an RTL simulation for a module you design? You need to verify the math, the latency and boundary conditions. It is in iterative process. So is the HLS tool but you move much faster as the time between code tweaks is much faster in the C/C++ domain than RTL simulation domain. Here is how we did with respect to performance and device usage:
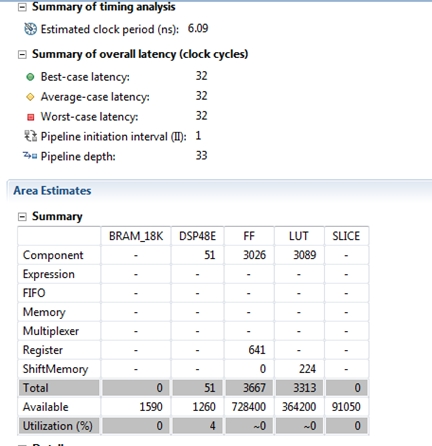
In HLS you’re mainly trading off FPGA device area, clock speed and latency. You no longer have to wait for MAP to complete to see device usage and Fmax. Think of that next time you are sizing FPGAs for your next proposal. The C/C++ you write can be added to a library and reused again and again. Now some of you may be asking, why don’t I just use a SIN(X) function in math.h? Well that works too, and that would only take 10 seconds to design using Xilinx’s Vivado HLS, but the latency will be 48 clocks. We needed to hand code the C function because I needed a pipelined, 32 clock solution. Go download a free trial at Xilinx to play with Vivado HLS today! You won’t regret it…

lang: en_US





Captain America: Can Elon Musk Save America’s Chip Manufacturing Industry?