


You may say, “Why should I worry about synchronizer failures when I have never seen one fail in a product?” Perhaps you feel that the dual-rank synchronizer used by many designers makes your design safe. Furthermore, those chips that have occasional unexpected failures never show any forensic evidence of synchronizer failures. Why worry?
There are contemporary cases and have been cases of synchronizer failure over the years. In fact, there have been many more than can be listed because firms designing digital systems are reluctant to call attention to their failures and because the infrequent and evanescent nature of these failures makes them hard to locate and describe. A few cases are listed here. To indicate the time span of these documented cases, let’s look at the first and last.
ARPAnet (1971): The Honeywell DDP 516 was used at a switching node in the original ARPA network, but in early tests it failed randomly and intermittently within hours or days. Persistent efforts to capture the symptoms were unsuccessful. Eventually, Severo Ornstein diagnosed the problem based on his prior experience with metastability. He then remedied it by halving the synchronizer clock rate (effectively doubling the resolution time). Honeywell did not accept this solution so each DDP 516 had to be modified before installation in the original experimental network.

Technion (May 2013): Scientists at the Technion in Israel reported on a case of metastability in a commercial 40nm SoC that failed randomly after fabrication. Normally, there would have been no forensic evidence that metastability was the cause of these failures. However, by use of infrared emission microscopy they identified a spot on the chip that correlated with the failure events in both time and location. The spot contained a synchronizer with a transient hot state that confirmed its role in the failures. Because the system employed coherent clock domains, the synchronizer MTBF was sensitive to the ratio of frequencies used in the two clock domains to be synchronized. The original, unfortunate choice of this ratio led to the failures and a more favorable choice improved the MTBF by two orders of magnitude. For the application at hand, this was an acceptable solution, but it was a highly expensive and time-consuming way to resolve the problem.
Another difficulty in reporting metastability failures is their infrequency. A Poisson process models the failure rate well, as demonstrated by the correlation between simulations and measurements in silicon. Suppose a product has a failure rate such that there is 50% chance that a problem will be detected in tests that that have a 30-day duration. Further, suppose that no failure happened to be detected during that test period. If product life is 10 years and 10,000 times as many products are to be sold as were tested the expected number of failures would be over a million. Many would be benign, but in safety-critical systems some could lead to fatal results. Even if the probability of failure during test is orders of magnitude less than 50%, the multipliers associated with the longer life and greater numbers in service can make the failure risk significant.
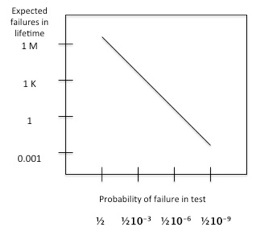 These considerations make it clear that physical tests of products after fabrication are necessary, but insufficient. Only simulations of synchronizer performance, best done before fabrication, can verify the lifetime safety of a multi-synchronous system. This conclusion is of increased importance as synchronizer performance becomes increasingly dependent upon process, voltage and temperature conditions and more highly variable within and among chips.
These considerations make it clear that physical tests of products after fabrication are necessary, but insufficient. Only simulations of synchronizer performance, best done before fabrication, can verify the lifetime safety of a multi-synchronous system. This conclusion is of increased importance as synchronizer performance becomes increasingly dependent upon process, voltage and temperature conditions and more highly variable within and among chips.
lang: en_US





TSMC CoWoS versus Intel EMIB Semiconductor Packaging