

Following up on their webinar on functional safety in FPGA-based designs, Synopsys have now published a white paper expanding on some of those topics. For those who didn’t get a chance to see the webinar this blog follows the white paper flow and is similar but not identical to my webinar blog, particularly around differences between different FPGA architectures. The topic is design for functional safety, particularly as applied to FPGA design and how these techniques can be implemented using Synopsys’ Synplify Premier. In fact, in this very detailed review I saw little that isn’t of equal relevance in ASIC design, though typically implemented using different tools and methodologies.

The paper kicks off with a bite-sized summary of the IEC 61508 standard for safety in industrial electrical and electronic systems and the ever-popular ISO 26262 standard for safety in automotive electronic systems. Both are useful to have on hand when someone asks you what you know about these standards, expecting a quick answer but wanting something more than just “safety”, preferably involving mention of SIL and ASIL levels.
The authors go on to note that what safety techniques you might choose to apply will depend to some extent on the FPGA architecture (SRAM, anti-fuse and flash-based). I don’t remember this coming up in the webinar, so there’s new information here. This is particularly applicable to redundancy approaches to safety.
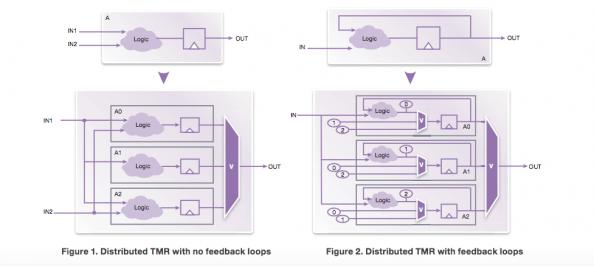
They discuss how triple modular redundancy (TMR) can be best applied. In SRAM-based FPGAs, configuration memories (used for routing matrix and LUT functionality) are particularly susceptible to soft errors whereas the failure-in-time (FIT) rate for individual registers is relatively small. Therefore safety-sensitive logic requires triplication with majority-voter logic at outputs. If the logic contains feedback loops, it may require distributed TMR (DTMR) to embed further triplication and voting in those loops, though there is an option for lower overhead with block TMR (here’s one useful reference for the various flavors of TMR).
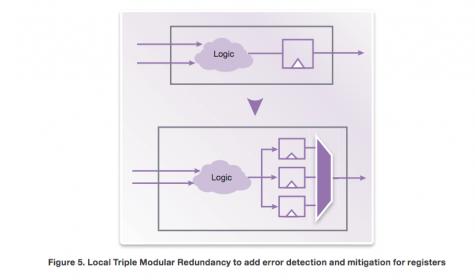
In anti-fuse and flash-based FPGAs, routing is insensitive to soft errors and registers are more of a concern. Here local TMR around registers is a more appropriate solution.

The authors go on to talk about safety techniques for finite-state machines (FSM) – a recap from the webinar. FSMs are particularly prone to soft error problems, since an incorrect bit flip can send the FSM in an unexpected direction, causing all kinds of problems downstream. The white paper describes two recovery mechanisms: “safe” recovery where a detected error takes the state machine back to the reset state and “safe case” where detection takes the FSM back to a default state (In Synplify Premier, this also ensures the default state is not optimized out in synthesis – you would need a similar approach in other tools).
It is also possible to support error correction in FSMs where state encoding is such that the distance between current state and next state is 3 units. In this case single-bit errors can be detected and corrected without needing to restart the FSM or recover from a default state.

For memories, some FPGA devices supports ECC (error-detection and correction) logic for block RAM. This is one-bit correction and can be used where appropriate. Where this does not meet your needs (if you need a higher level of protection) you can again use triplication, with block, distributed or local TMR as appropriate.
The authors also cover a point in the paper that they did not cover much in the webinar. Triplication is obviously expensive and in some cases may be too expensive to consider. In these cases, a better option may be to detect an error using duplicated logic. Like a parity check, this can’t fix but can at least detect an error. It’s then up to you to decide how you want to recover. You might choose to do a hard reset and scrub configuration logic (in an SRAM-based FPGA) or perhaps there is a design/use-case-dependent possibility to do a more localized recovery. In this case you’re obviously trading off time to recover from an error against utilization/device size.
Finally, although not mentioned in the paper, I assume a physical constraint raised in the webinar is still important so I’ll repeat it here. Radiation-induced soft-errors can trigger not just the initial error but also secondary ionization (a neutron bumps an ion out of the lattice, which in turn bumps more ions out of place, potentially causing multiple distributed transients). If you neatly place your TMR device/blocks together in the floorplan, you increase the likelihood that 2 or more of them may trigger on the same event, completely undermining all that careful work. So triplicates should be physically separated in the floorplan. How far depends on free-ion path lengths in secondary ionization.
Naturally many of these methods can be implemented in FPGA designs using Synplify Premier; The white paper gets into a little more detail in each case on what is supported. You can get the white paper HERE.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.