SPICE simulation is the workhorse tool for custom circuit timing validation and electrical analysis. As the complexity of blocks and macros has increased in advanced process nodes — especially with post-layout extraction parasitic elements annotated to the circuit netlist — the model size and simulation throughput of traditional SPICE engines became problematic, even intractable. A class of Fast SPICE products emerged that incorporated modified approaches for device modeling, network solver algorithms, and transient simulation timestep management. These tools provide significantly improved throughput and capacity, and are typically applied to simulation of networks such as large memory arrays.
Nevertheless, circuit simulation requirements have become more diverse and demanding than ever, such as:
- validation of large, mixed-signal IP blocks (big A/little Ddesigns)
- evaluation of models incorporating Verilog-A semantics and S-parameter system elements
- low power validation (with requirements for accurate sub-threshold leakage currents, and including detailed power rail models)
With the advent of multi-core, large memory footprint compute servers, parallel SPICE products have been introduced, to address the capacity/throughput issues and to provide the requisite accuracy of “traditional” SPICE for more demanding applications.
I recently had the opportunity to chat with Bruce McGaughy, CTO of ProPlus Design Solutions, Inc. He provided an enlightening perspective on the latest in the parallel SPICE methodology, as represented by the ProPlus NanoSpice-Giga toolset.
First, a little background…
Traditional SPICE execution flow
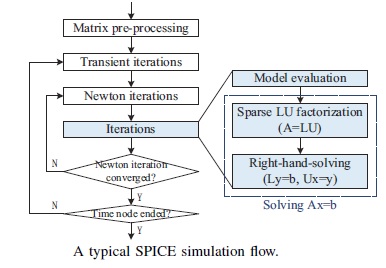
The figure below illustrates the typical SPICE execution flow, for a transient simulation.

(From: Chen X., Wang, Y., and Yang, H., 2012 IEEE 26th International Parallel and Distributed Processing Symposium)
The principal step is the convergence of Kirchhoff’s Current Law (KCL) and Voltage Law (KVL) for the circuit network matrix at each successive (adaptive) timestep, as depicted in the Newton-Raphson iterations loop in the flow diagram. The KCL network solution is derived, and KCL and KVL are verified to a suitable absolute and relative error accuracy tolerance, as defined by ABSTOL and RELTOL settings. In the figure, the inner Iterations part is expanded to show the corresponding substeps:
- model evaluation
- factoring of the (sparse) network matrix A into Upper and Lower matrices
- solving the network branch current measures (vector ‘x’) at each timestep, with applied stimulus vector ‘b’, evaluating node voltages, confirming KCL and KVL
The key differentiation of traditional SPICE to the Fast approach (to be discussed next), is that thefullnetwork matrix is solved (“converged”) at the end of the Newton-Raphson loop, for the selected timestep increment, to the accuracy defined by the error tolerances.
Fast SPICE approach
Fast SPICE products utilize a number of “speed-up” methods, to achieve greater capacity and throughput over traditional SPICE. These methods include:
- pre-characterized, multidimensional table-lookup device models (accelerating the model evaluation step in the figure above)
- aggressive RC reduction of annotated parasitics
- multi-rate, event-driven circuit analysis (and timestep advance) for network partitions
These approaches are ideally-suited for designs such as large memory arrays, with regular hierarchy (enabling aggressive model partitioning), and with limited inter-partition circuit activity.
Bruce noted that there are classes of simulation problems where Fast SPICE is not the ideal approach. Specifically, the event-driven method improves performance by evaluating active partitions, and not the entire network in total — in other words, full network convergence is not required at each timestep. As a result, there is a potential loss of accuracy in critical circuit electrical measures.
Parallel SPICE
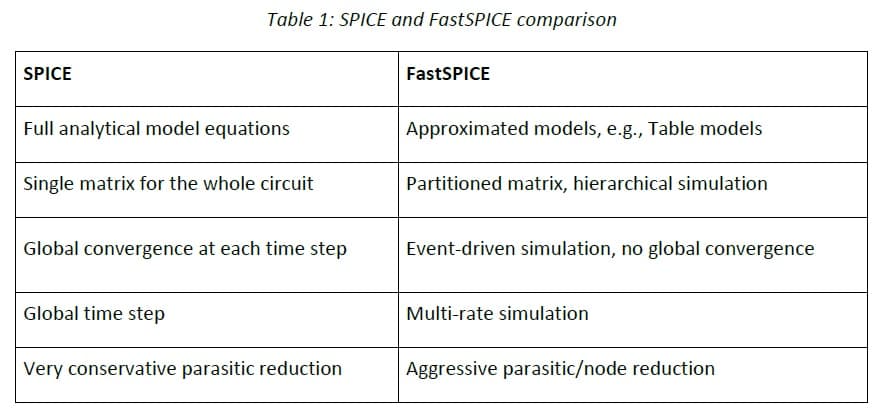
The figure above from ProPlus provides a comparison between parallel SPICE and Fast SPICE approaches.
Their NanoSpice-Giga product is in the class of parallel SPICE methods. The target hardware execution platform is a multiprocessor (e.g., 32 cores), shared memory server, running ~8-16 threads.
The model input and user settings are the same as traditional SPICE, including: Verilog-A, device aging support, etc.
No table lookup models are used. Bruce highlighted,“Given the increasing model nonlinearities, and the diversity of device operating domains, table models are less accurate for circuit electrical analysis.”
Referring again to the SPICE flow diagram above, the model evaluation step is relatively easy to parallelize. The key technical advancement in this class of SPICE products is the parallelization of the LU factoring and full network solver algorithms. There are additional memory utilization optimizations applied in NanoSpice-Giga, as well, to support netlists exceeding 50M devices and 500M parasitics.
NanoSpice-Giga has the added benefit of its relationship to other ProPlus solutions. The flagship product, BSIMProPlus, is used by all major foundries for developing PDK device model parameters, whether the process is bulk, FinFET, FD-SOI, etc.
The NanoSpice engine is integrated in BSIMProPlus (for model fitting), and is highly tuned for execution runtime. As illustrated in the figure below, this same optimized kernel is incorporated into the parallel NanoSpice-Giga product, as well.
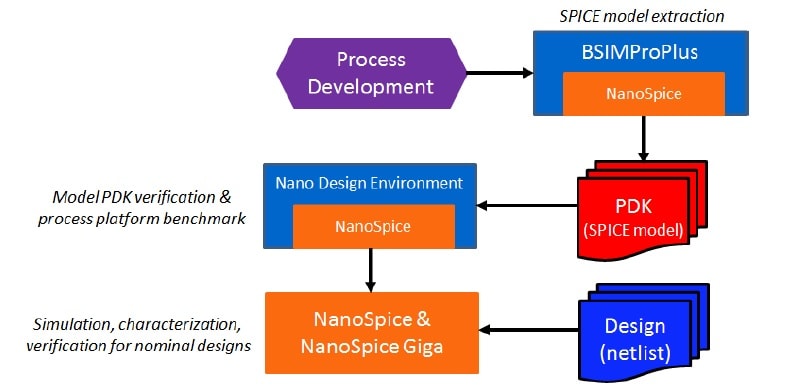
Bruce provided a couple of customer examples, illustrating the application domains where NanoSpice-Giga is being used. Silicon Creations is developing high-speed SerDes IP (in 28nm, 16nm, and 10nm nodes) with this parallel SPICE simulation methodology. eSilicon Corp is characterizing memory arrays and custom IP in advanced nodes using parallel SPICE, as well.
SPICE-based circuit simulation will remain a key component in the circuit designer’s toolbox. Yet, designers need to ensure that the algorithmic approach used — i.e., traditional, fast SPICE, parallel SPICE — is best-suited to the model analysis requirements, with the right tradeoffs on accuracy, throughput, compute resources, license cost, and usability. An increasing set of applications will require parallel SPICE methods, such as NanoSpice-Giga from ProPlus Design Solutions.
For more information on NanoSpice-Giga, please follow this link.
-chipguy
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.