

Electronic design automation (EDA) has come a long way from its beginnings. It has enabled chip engineers from specifying designs directly in layout format during the early days to today’s capture in RTL format. Every advance in EDA has made the task of designing a chip easier and increased the design team productivity, enabling companies to get their products to market quicker. Of course, the product requirements have not been staying static during this time. So, it has been a tug-of-war between EDA advances and design complexity increases.
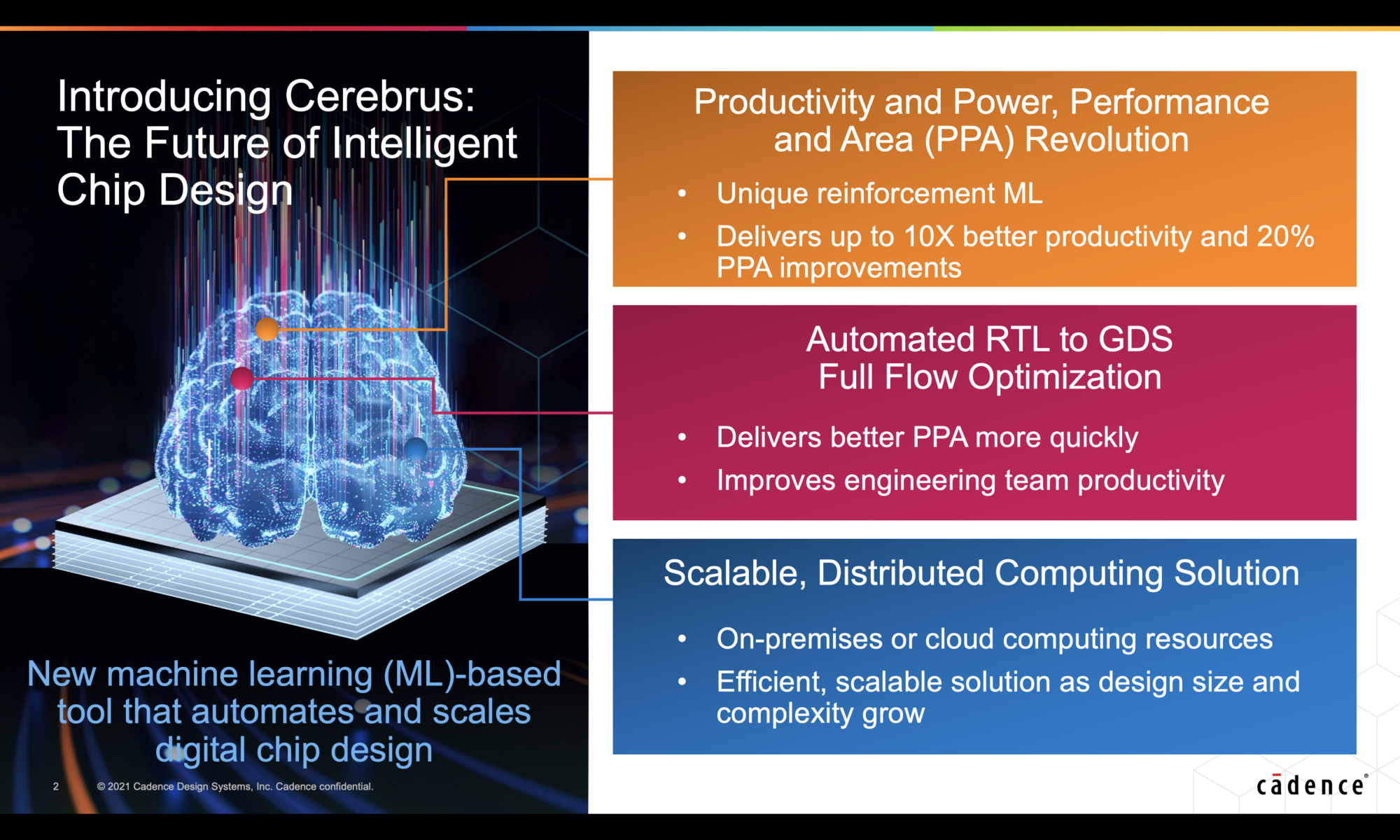
One thing that has remained constant in the chip world is the desire for a tool that will take in design specifications and product constraints and with the push of a button, generate a design that is manufacturable, production ready and meets or beats the stated product constraints. It is a lofty goal indeed. Last week, Cadence announced the Cerebrus Intelligent Chip Explorer. It is a machine learning (ML)-based tool that takes the chip world one step closer in that direction. It delivers enhanced PPA, higher team productivity and shorter time to market benefits for its customers.
During CadenceLIVE Americas conference in June, Cadence mentioned a number of areas where it has been incorporating ML technology, and Cerebrus is the latest result of Cadence’s ML initiative. I expect to hear more product announcements resulting from the ML initiative.
I had an opportunity to discuss the Cerebrus announcement with Kam Kittrell, senior product management group director in the Digital & Signoff Group at Cadence. The following is a synthesis of what I gathered from my conversation.
What is Cerebrus?
It is a new type of EDA tool from Cadence that works with the RTL to GDS signoff flow. It takes power, performance and area targets for a design or a block within a design. The user can provide a start and end point of the flow or tell the tool to do the full flow. The tool works within the context of the standard production flow that includes multiple tools and IP blocks and also accommodates personal configuration preferences of the respective CAD team running this tool. It is an automated RTL-to-GDS full flow optimization tool.
Although EDA stands for automation, until this point in time, learnings from past designs were not automatically fed into newer design flows. Cerebrus not only uses ML to explore better designs but also saves learnings for leveraging into new designs.

Why is Cerebrus Needed?
One could be thinking, EDA tools that I am familiar with are pretty good. The tools already do a great job. Once I get a design to a basic working status, squeezing the last ounce of performance or power savings or area savings is the task of expert engineers. While that is how things have been done historically, we know that optimization efforts consume lot of engineers, time and compute resources. Cerebrus on the other hand can run 50 to 100 different experiments very quickly. In essence, by leveraging ML techniques, it can search a much larger space in far less time than is possible via manual means and arrive at the optimal path for reaching the goal.
Refer to figure below. It shows benchmark results from a 5nm mobile CPU design.

After taking this design to a working status using a basic flow, many engineers worked over several months to achieve a flow that delivered the PPA goal for the design. In parallel, Cerebrus took off from the basic starting point and kicked off the investigation to find the optimal path. The objective of this benchmarking exercise was to increase productivity without compromising on PPA goals. Cerebrus achieved the goal in much less time using the same amount of compute resources and using just one engineer and ended up improving the PPA as well, automatically.
How does Cerebrus Work?
Automation is all about achieving efficiencies. EDA increases people productivity in achieving design goals. Through ML techniques, Cerebrus helps increase EDA flow efficiencies and enables tools to quickly converge on better placement and route and timing closure. ML types of applications usually require lots of training before a model can be developed and used. And the training phase requires lot of compute resources.
But Cerebrus does not need a large training set before it can start working. And it does not need a large compute farm either. With no training on a particular process node, it can find an optimal path quickly. The resulting model can be reused on the same design for further refinements. The model can also be transported to a different design with similar operating conditions and same process node as the earlier design. The reinforcing nature of Cerebrus’ learning model increases effectiveness with each use. Result is significant PPA improvements, resource optimizations (people and hardware) and schedule compressions.
Scalable, Distributed Computing Solution
Cerebrus just takes one engineer to manage the automated RTL-to-GDS flow optimization runs for many blocks concurrently, allowing full design teams to be more productive.
Cerebrus supports all leading cloud platforms. With a manual approach to PPA refinement, typically on-demand compute resources are locked in for a long period of time, whereas with Cerebrus’ ML-based automated approach, on-demand compute capacity is kept for a much shorter period of time to arrive at the optimal path. In this sense, it provides more efficient on-site and cloud compute resource management than the traditional human-driven design exploration.
When is Cerebrus Available?
It is in general availability (GA) now.
Some Interesting Use Cases for Cerebrus
In addition to the standard use case where PPA optimization or productivity improvement is the objective for using Cerebrus, there may be situations that trigger different use cases.
- Customers sometimes think of a derivative product when working on the primary product and decide to arrive at a product that is in-between because they think they cannot do both chips. Alternately, they may decide to build a superset of a chip and turn off portions of the chip to deliver a derivative product. Neither of these paths are ideal. Cerebrus can help customers do both chips in parallel with fewer engineers (smaller team) than what would otherwise be needed and achieve both chips that are optimized for their purposes.
- Refer to figure below which shows the results from an exercise for optimizing floorplan and implementation plan concurrently.

Summary
The revolutionary ML-based Cerebrus enables customers to meet increasingly stringent PPA, productivity and time-to-market demands of their respective market segments. Cerebrus also makes it easier and quicker to develop optimized chip derivatives. The press announcement can be found here and more details can be accessed in the product section of Cadence website. You may want to discuss with Cadence and explore incorporating Cerebrus into your chip design flow.
Also Read
Instrumenting Post-Silicon Validation. Innovation in Verification
EDA Flows for 3D Die Integration
Neural Nets and CR Testing. Innovation in Verification
Share this post via:



Musk’s Orbital Compute Vision: TERAFAB and the End of the Terrestrial Data Center