

Some time ago I wrote a DeepChip viewpoint on DVCON 2014 in which I praised a  Mentor paper “Of Camels and Committees”. The authors argued that while the UVM standards committee had a done a great job in the early releases, the 1.2 release was overloaded with nice-to-have features with questionable value for a standard, particularly since this came at a cost of 12,000 new lines of presumably less than battle-hardened code. They argued that standards should stick to the minimum refinements required to enable users and competitors to progress efficiently, and no more. It’s difficult to argue with that position. Even if you are an open-source fan, a standards committee is the wrong place to evolve a code-base of this size. Either changes move too slowly to provide real-time fixes for live use, or move too quickly to support a stable standard.
Mentor paper “Of Camels and Committees”. The authors argued that while the UVM standards committee had a done a great job in the early releases, the 1.2 release was overloaded with nice-to-have features with questionable value for a standard, particularly since this came at a cost of 12,000 new lines of presumably less than battle-hardened code. They argued that standards should stick to the minimum refinements required to enable users and competitors to progress efficiently, and no more. It’s difficult to argue with that position. Even if you are an open-source fan, a standards committee is the wrong place to evolve a code-base of this size. Either changes move too slowly to provide real-time fixes for live use, or move too quickly to support a stable standard.
Rich Edelman and Bhushan Safi of Mentor are pushing the case further, this time arguing for simplifications in the UVM register model; this subset of the standard consumes 22,000 lines of code and a quarter of the User Guide. A natural rebuttal would be that the code size merely reflects the importance of register verification. Software developers have to trust that the hardware can be controlled and observed as described in the register documentation. While it’s true that this area of verification is very important, it’s less obvious that its importance necessarily implies a need for such a large body of code and features in a standard.
Registers can be complex beasts. There are the simple cases – just address, read, write and reset – but all sorts of complications can be added: read-only, write once, clear-on-read, different reset values, different fields within a register which differ in these characteristics, shadow registers, and many more variants. Trying to abstract all of this in a complete but still easy-to-use way is a Herculean (maybe impossible) task. Another rebuttal might be to ask how else it could be done. An object-oriented (OO) approach is surely the natural way to abstract and hide complexity? But as I remember, standards should prescribe interfaces, not implementation, which is normally left to market innovation / competition. Something seems amiss.
Standards philosophy aside, what’s really important is how this is working out in deployment. Mentor experience with a significant percentage of users is that the latest rev of the Register package has missed the easy-to-use objective by a fairly wide margin, at least among its target user-base. Rich tells me a majority of their users don’t understand the class structure or behavior; they do OK with the basic registers but with more complex cases they struggle (and generally fail) to find a way to model them correctly. The outcome is that they use the package to do the basic address and read/write tests, but write their own tests for more complex behavior, circumventing the intended use of UVM registers and field classes, which makes their testbenches run big and slow. And that makes them unhappy, especially if an emulator is idling for long periods, waiting for the testbench to catch up. On the other end of the scale, some verification teams enthusiastically adopt the OO style but lack the required skills and are spending a lot more of their verification cycles debugging the testbench than the design.
Rich and Bhushan make a case for a simpler approach (the genie may be out of the bottle now, but they can at least make their case). They argue for a simpler register model based on structs rather than (in their view) overkilling the need with classes. Sure classes are more flexible and extensible and inheritable and all that good stuff, but unless you are comfortable in OO approaches and skilled in UVM register classes (which it seems most verification engineers are not), all that capability becomes a steep learning curve rather than a simplification. The Mentor suggestion is a simpler (and less intimidating) programming model, easily extensible to handle those complex quirky registers. And it’s more time- and space-efficient since a packed struct is almost always going to be smaller than an equivalent class (especially for bitfields).
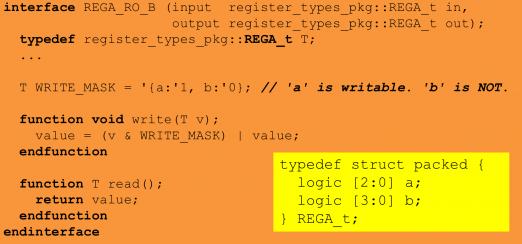
Rich admits their approach is not ideal either. It puts more of the programming burden on the verification team, but that seems to be happening anyway with workarounds in place of existing UVM Register capabilities. Perhaps the ideal approach would be C-based, perhaps it requires a move to some more standardized approach to register management. I’m sure users will know it when they see it; it’s not apparent that they see it in the UVM Register model as it currently stands. Perhaps that’s their problem – they have to adapt or or find a different job. But I’m not sure that’s what they or their managers expected from the standard. Or perhaps, in good standards as in good design, less is usually more.
The Mentor paper on “Getting Beyond UVM Registers” is HERE.
Share this post via:



Comments
0 Replies to “When Good Standards Get Lost – the UVM Register Model”
You must register or log in to view/post comments.