
You verified your product design against every scenario your team could imagine. Simulated, emulated, with constrained random to push coverage as high as possible. Maybe you even added virtualized testing against realistic external traffic. You tape out, wait with fingers crossed for first silicon to come back. Plug it into the test board and everything looks good – until an intermittent bug sneaks in. After much head scratching, you isolate a problem to read/write re-ordering misbehavior around the memory controller. Now you have to try to reproduce the problem in pre-silicon verification. Hunting for a bug you missed. But formal for post-silicon bug hunting? That’s not as strange as you might think.
Out of control
You know where this is going. There’s an interconnected set of state machines mediating interaction between the interface control unit, the buffer unit and the memory controller. In some overlooked and seemingly improbable interaction, old data can be read before a location has been updated. Not often. In the lab you only see a failure intermittently, somewhere between every 2 to 8 hours. Not surprising that you didn’t catch it in pre-silicon verification. I’ve seen similar issues crop up around cache coherence managers and modem controllers.
This is where formal methods can shine, finding obscure failures in complex state machine interactions. But in this application, you’re not setting out to prove there are no possible failures – that’s pre-silicon verification. Here you want to hunt for a bug you know must exist. That takes a different approach, one that won’t present any great challenge to formal experts but can be a frustrating search for a needle in a haystack for most of us. Through much experience Siemens EDA have developed a systematic approach they call a Spiral Refinement Methodology that should help you find that needle, without losing your mind.
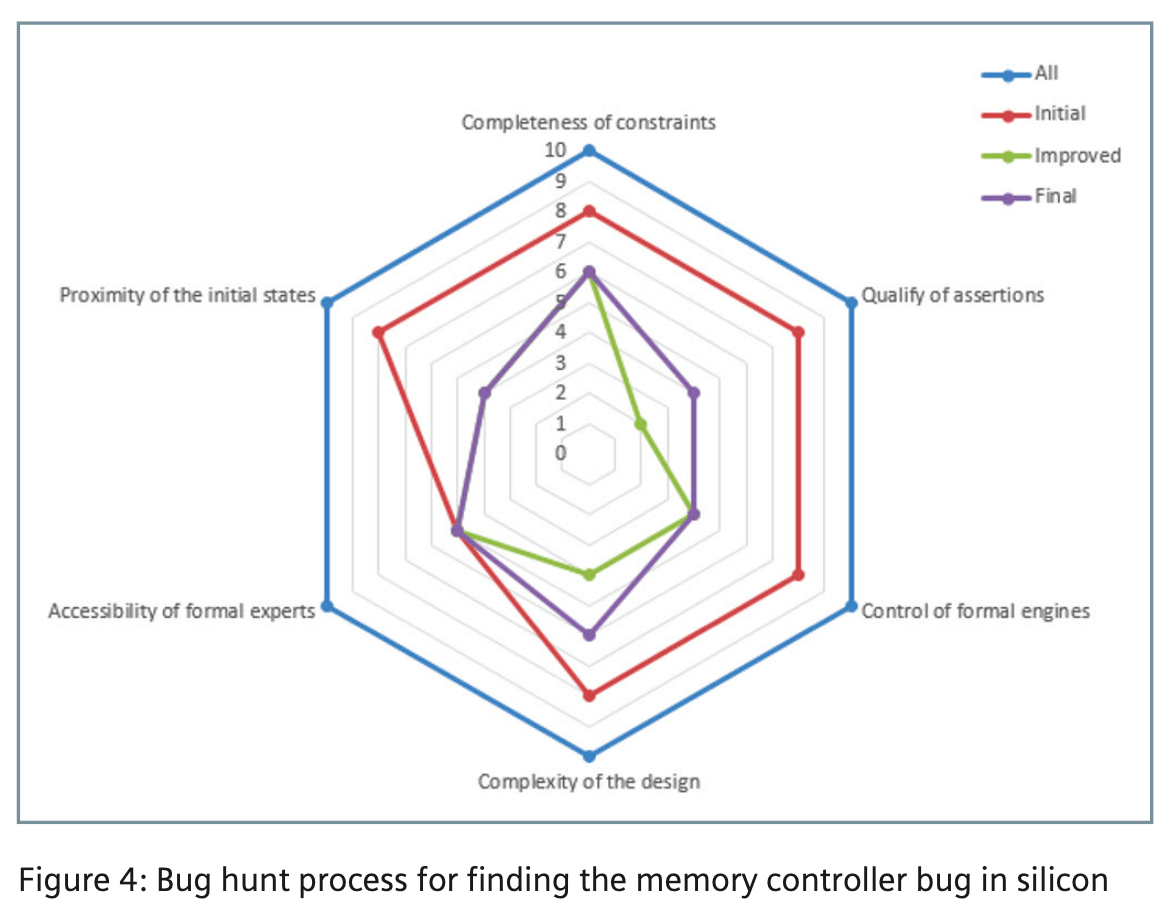
Spiraling through a radar chart
They graph this refinement in a radar chart (the image in this blog is an example). The search progresses through multiple objectives at several levels. They start by reducing complexity to make formal analysis possible. Since the debug approach is formal, you first need to localize where, functionally, in the design the failure is happening. This insight typically emerges through bug triage in the lab. Then you can eliminate big chunks of the design that should not be important. And perhaps (carefully) add constraints. You will need access to formal experts, internal or external, to guide you away from pitfalls. Particularly as you start to abstract or divide up the problem to further manage complexity.
Assertions and initial state
Another key objective is to refine assertions towards the failing condition. One technique they mention here is “formal goal-posting”. This is a method to progress towards a condition through a sequence of proofs which allow you to step out through the state-space in digestible chunks, rather than trying to do the whole thing in one impossible leap. Along similar lines, they stress the importance of finding a suitable initial state to start proving cycles. For bugs that may not crop up for several hours, you’ll need to start close in the time, not just in space (function). Simulation can get you there, to set up that initial state.
Then they refine each of these objectives. Further abstractions, further tuning assertions, finding more suitable initial states. Zeroing in on a sequence or set of sequences that can lead to that failure detected in the lab. They describe application to three example failures, including this one. In each case localizing the problem through a very systematic search.
Very nice paper. You can read it HERE.
Also Read:
Library Characterization: A Siemens Cloud Solution using AWS
Smarter Product Lifecycle Management for Semiconductors
Observation Scan Solves ISO 26262 In-System Test Issues
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.