

No, not the news network though I confess I am curious to see how many initial hits that title attracts. Then I clarify that I’m talking about convolutional neural nets, and my would-be social media fame evaporates. Oh well – for those few of you still with me, CNNs in all their many forms are the technology behind image, voice and other types of recognition. Taking an image as an example, a pixel array of that image is passed through a series of layers of neuron-like computations – convolution, activation, pooling (the details vary), potentially many layers – to produce an output. Initially the system is trained using labeled images (this is a robot, in this case) through an iterative process across many examples, this unlikely structure adjusts to being able to recognize in any image the thing for which it was trained.
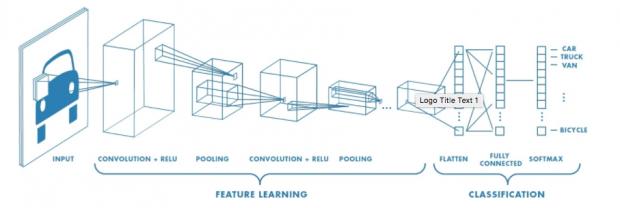
CNNs are so amazingly effective that they have become true media stars, at least under the general heading of AI, able to recognize dogs, tumors, pedestrians in front of cars and many more high-value (and not so high-value) tricks. They’re even better than us mere humans. Which makes you wonder if CNNs are pretty much the last word in recognition, give or take a little polishing. Happily no, at least for those of us always craving the next big thing. CNNs are great, but they have their flaws.
In fact trained CNNs can be surprisingly brittle. Hacking images for misidentification has become a sport. This seems to be remarkably easy, sometimes requiring changes to only a few pixels. After a spectacularly inept and un-gamed blunder, Google acknowledged that “We still don’t know in a very concrete way what these machine learning models are learning,”.
It’s fun to speculate on the mystery of how these systems are already becoming so deep and capable that we can no longer understand how they work, but that lack of understanding is a problem when they don’t work correctly. Even within the bounds of what they can do, while CNNs are good at translational invariance (doesn’t matter if the cat is on the left or the right of the image), they’re not so good at aspect / rotational invariance (cat turned to the left or the right or standing on its head), unless in the training you include many more labeled examples covering these variants. Which doesn’t sound very intelligent; we mere humans don’t need to see objects from every possible aspect to be able to generalize.
Geoffrey Hinton (U Toronto and Google and a towering figure in neural nets) has been concerned for a long time about weaknesses in the CNN approach and thinks a different method is needed, still using neural nets but in a quite different way. He argues that the way we render computer graphics is a clue. We start with a hierarchical representation of the data, small pieces which are placed and oriented relative to other nearby pieces, forming together larger pieces, which are placed and oriented relative to other large pieces, and so on. He believes that our brains effectively do the inverse of this. We recognize small pieces along with their placement and orientation relative to other small pieces, recursively up through the hierarchy. He calls these sub-components capsules.
You might argue that this is just what CNNs do, recognizing edges, which are then composed into larger features, again recursively through the network. But there are a few important differences as I understand this. CNNs use pooling to simplify regions of an image, sending forward only the strongest signal per pool. Hinton thinks this is a major weakness; the strongest signal from a pool may not be the most relevant signal (at any given layer) if you’re not yet sure what you are going to recognize. Moreover, pooling weakens spatial and aspect relationships between parts of the image.
Additionally, CNNs have only a 2D understanding of images. Capsules build rotation + translation pose matrices for what they are seeing (remember again 3D graphics rendering). This becomes important in recognition in subsequent capsules. Recognition depends on relative poses between capsules; some will correlate with certain trained objects, others will have no correlation. Capsule-based networks consequently need little training on aspects/poses.
Another difference between the CNN approach and the capsule approach is how information is propagated forward. In a CNN, connections between layers are effectively hard-wired. Each element (neuron) in a layer can only communicate with a limited set of elements in the next layer, since being able to connect to all would be massively costly (in much smaller final layers, full connectivity is allowed). In capsule-based networks routing is dynamic, a capsule will send its output to whichever capsule most strongly ‘agrees’ with it; in effect capsules build a voting consensus on what they are seeing, which it appears gives CapNets a huge advantage in accuracy. They can learn on training sets of hundreds of examples rather than tens of thousands of examples.
At least that’s the theory. CapNets are already beating CNNs in recognizing hand-written digits but I haven’t seen coverage of application to more complex image recognition (yeah, not exactly stressing the 3D strength yet). And CapNets are currently quite slow. But they do run on the same hardware, in the same frameworks in which CNNs are trained (see some of the links below). No need to worry that your investment in special hardware or learning TensorFlow will be obsolete any time soon. But you might want to start brushing up on this domain for when they do start moving into production.
Here is a nice summary of the evolution of CNNs and what capsule networks bring to the part. This is taken from this YouTube video. Also another not quite complete explanation.
Share this post via:



Enhancing Multi-Domain System Simulation with FMI Co-Simulation