
Among several topics dominating news streams these days, giant datacenters are a leading theme. They point to an AI-centric future while raising real concerns about sustainability and scalability. Certainly land, power and water demand are very present concerns for most of us, witness growing pushback against building new datacenters. At the same time analysts and investors are clear that the datacenter center boom is not sustainable and are trying to guess when and how this growth collapses. It’s worth going a bit deeper than the daily tea leaf readings to better understand what is happening and how it can more realistically evolve. My thanks to the team at Quadric (Steve Roddy, CMO and Daniel Firu, CPO/Co-Founder, who presented this concept at a recent Silicon Catalyst conference) for these insights.
The tokens rollercoaster
In the spirit of driving adoption, and because nobody yet knows how to measure productivity through AI other than by tokens consumed, the AI heavyweights (Anthropic, OpenAI and Gemini) first offered unlimited token usage. This worked spectacularly: usage ramped very fast, spawning the Token Maxxing phenomenon. Hyperscalers committed hundreds of billions of dollars to building giant datacenters. Then of course analysts speculated that they were building ahead of demand and concern grew that a crash was right around the corner.
Well not quite. Turns out that datacenters are already fully utilized and demand still exceeds supply. Anthropic and others have started pushing license holders into new pricing models, increasing costs to throttle demand. Meanwhile they have signed a deal for capacity on Elon Musk’s Colossus at a claimed $1.25B/month, which would match or exceed SpaceX’s Starlink revenues. (According to SpaceX’s SEC Form S-1 filing the company reported consolidated revenue of $18.7 billion for 2025. Anthropic’s rental of Colossus is reported at $16B annually). Token demand is still ahead of supply and our token maxxing days are over. Enterprises are already looking for clarity in ROI and more grounded ways to measure AI productivity.
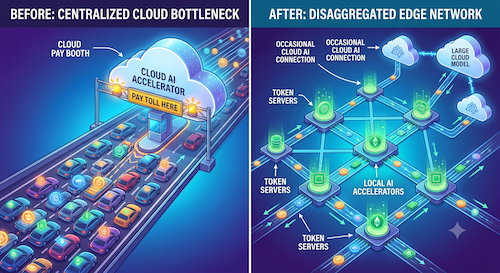
Equally they want to limit dependency on cloud-hosted AI. As license deals are rewritten, casual office AI users may not see a big impact but engineering users who have been building major productivity advances around AI in their workflows cannot afford to hit a token ceiling mid-morning. They need to run on more flexible “token servers”, on-prem domain-specific AI capacity which can connect to cloud-level token servers only as needed for general-purpose reasoning/RAG/etc.
Disaggregating token serving capacity
Take Anthropic Claude as an example. Great capabilities, wildly popular and it runs in the cloud. It could also run in a local (on-prem) cloud, but the full model is overkill for domain specific purposes. You really want a full-Claude/mini-Claude approach, the mini version a locally hosted slimmed down model with added domain-specific training, tapping a cloud service when required. Hardware engineers are already building similar systems. The in-house version will be a high-demand service. Many engineers, each launching their own orchestrator, each in turn launching multiple sub-agents. Public cloud services make this work with Kubernetes managing the whole show, running multiple containerized agents.
Replicating public cloud Claude activity would strain enterprise in-house compute budgets, demanding more servers, more networking, more storage. Much better if the enterprise could add more affordable token servers as specialized hardware running their domain-specific mini-Claudes, with flexibility to add more as demand increases.
Affordable implies low cost – under $1000 and modular for wide adoption. We have already seen Qualcomm, Microsoft and others promoting AI PCs. NVIDIA now has their own AI PC offering (introduced June 1st) with anticipated price tags for fully featured RTX Spark-powered PCs as high as $5000. Some engineering teams are now configuring Mac Minis to get even closer to the token server idea (Quadric is already doing this in their shop). The motivation is simple. Local AI platforms from the big guys are seeding this direction, while healthy competition from new system ventures will further expand options.
Great opportunity for an exploding business in pre-packaged token servers. Quadric think so. Slow down building politically fraught giga-datacenters with high token rates and bring the bulk of your AI workload back in-house using dedicated open-source models, or “mini-Claudes” adapted to your needs. Quadric is pushing this message: a token server appliance could cost as little as a commodity laptop does today, with effective tokens/second output at far more affordable levels. Such a server’s silicon platform is mostly NPU horsepower with a small CPU cluster to run tasks that can be managed locally (even on your own desktop). Quadric is already working with clients, building on Quadric NPU IP, to fashion such appliances.
You can learn more HERE.
Also Read:
Podcast EP336: How Quadric is Enabling Dramatic Improvements in Edge AI with Veer Kheterpal
Quadric’s Recent Momentum & Funding Success
2026 Outlook with Steve Roddy of Quadric
Share this post via:



Comments
2 Replies to “Disaggregating AI Compute to Break the Tokens Barrier”
You must register or log in to view/post comments.