We all know the concept of “one stop shop”, becoming popular in the Design IP market. The topic we will address today is NOT the “one stop shop”, even if it looks similar, but rather that we could call “consistent design flow”.
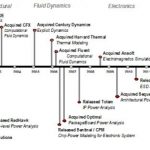
What does that means? Simply that, if your SoC design is integrating a DDRn (LPDDR2, DDR3 or even DDR4, let’s say DDR3 in this case) Memory Controller, you will have to run functional simulations of your SoC behavior, being as close as possible of the real life, then these simulations should integrate accurate model of the DDR3 memory chip. The easiest and safest path is to acquire this model. Denali has been started in the mid 90’s with this primary charter, develop and sale Memory Models. Nobody ignore that Denali has been acquired in 2010 by cadence (for a record $315M, or about 7X the 2009 company revenue!), and that Denali’s port-folio was based on: Verification IP (for Interface IP like PCIe, USB and so on), DDRn Memory Controller IP and… the Memory Models.
Cadence has acquired Denali to reinforce the Verification IP port-folio (and buy VIP market share…) and to add the very successful DDRn Memory Controller IP to the existing IP business, as well as the Memory Model business, where Denali was almost in monopoly position. The above picture clearly shows that I mean by “Consistent Design Flow”: PHY and the Controller (or “Integrated”) IP that could be interfaced with Memory Model, the behavior of the SoC interacting with external DDR3 being validated by using Verification IP, in a specific simulator (that Cadence can also offer, but this is not necessarily part of the “Consistent Flow”).
Within this Consistent Flow, we can find the DDRn Memory Controller “Integrated” IP. In this case, Integrated means that Cadence can provide both the PHY and the Controller IP. The Controller IP is 100% digital design, supporting the industry standard DFI PHY interface, when the PHY can be… either mixed signal Hard IP, either a soft IP. In fact, when Denali was providing DDRn Controller, the company was only proposing internally designed soft PHY, or Hard PHY from partners like Analog Bits or MoSys. Cadence has addressed this weakness after Denali acquisition and SoC design integrators can rely on Integrated solution (100% supported by internally designed pieces).
But designers still have the choice between using Hard PHY (see above picture) or Soft PHY, as legacy customers used to do. What’s the difference between Hard and Soft PHY? Probably a different pricing, but Cadence promotes the Hard PHY as being a TTM accelerator, when the Soft PHY offers higher flexibility as we can see on the picture below. Just a remark: if you prefer the higher flexibility of the Soft PHY, not impacting the chip floor-planning as would do a hard block, you may spend longer to meet the DDRn PHY timing constraints. If you consider that the DDRn frequency will go higher with new generation adoption, you quickly realize that the trend will be to use integrated solution based on Hard PHY in the future…
In fact, Cadence is going even further and offers a “System Integration Kit”, ensuring optimal system integration and eliminating overdesign. The idea is to propose an integrated silicon-package-board co-design environment, with IBIS models for DDRn PHY, reference implementations and diagnostics and analysis tools. Once again, the benefits will be accounted in TTM acceleration, as the solution allow to:
- Enable topology modeling ahead of committing to a final implementation
- Identifies SI issues early in the design process where they can be address at significantly reduced cost
- Eliminates the need to overdesign saving significant amounts of effort and cost
- Allows system design to begin much earlier than traditionally possible
All of the above represent a significant investment for an EDA/IP vendor! The differentiation is offering clear benefits for the customer, especially in term of TTM acceleration, but does the DDRn memory controller IP represent a significant market segment, offering large enough ROI to Cadence?
The answer is: we don’t know! I should say, we don’t know officially Cadence’s revenue or market share in the DDRn memory controller IP segment. IPNEST has made an evaluation of this segment business size, including Denali (then Cadence) for 2005-2011, as we can see on the picture below, but Cadence’s revenue could be lower… but my personal opinion is that it is even higher!
By Eric Esteve from IPNEST – “Interface IP Survey 2005-2011 – Forecast 2012-2016” Table of Content available here
As a bonus, two very relevant comments from a previous post about DDRn memory controller, if you have missed it:
It’s interesting that your list of IP is mostly serial interfaces, DDRn seems to be a hold-out as a parallel bus. Given that the increasing number of cores causes more bus contention (with a shared parallel bus), is there much future in DDRn?
04-14-2011 By Simguru
I am not up to speed on all of the different interface stds. Others please correct me if I’m wrong.
DDR is the fastest mechanism to transfer data to/from memory. Using both the positive and negative edges of a clock therefore decreasing clock speeds by 50% for the same data transfer rate. DDR does require PHYs like the other standards but I do not think this std has long cable lengths such as PCI Express, Xaui, USB, SATA, etc that must be met.
DDR (3 and 4) can transfer up to ~2700-3200 MB/s (not bits) while SATA3 is 600MB/s, HDMI is 10Gb/s or 1.25GB/s which makes sense to meet audio/video standards, USB 2.0 is in 30-60MB/s (actual vs. max), etc.
DDR can have a long future by wider word widths, faster clock rates, etc. I doubt for CPU/Memory interfacing, a serial std will replace it but stranger things could happen. Eric might have some research on this topic.
I will also bet that many handheld device that could be plugged and benefit from DDR for higher transfer rates are not willing to pay royaltes for this functionality (DDR patent). The other standards are cheaper to embed (lower or non-existent royalties).
my 2 cents.
04-15-2011 By BillM