At SEMICON last month, Rohit Pal of GlobalFoundries gave a presentation on their methodology for reducing process variation. It was titled Cpk Based Variation Reduction: 14nm FinFET Technology.
Capability indices such as Cpk is a commonly used technique to assess the variation maturity of a technology. It looks at a given parameter’s variability and compares it to 6 sigma. The higher the number the better, 1.33 should have the process yielding close to 100% (for that parameter) and 2 is the full 6 sigma. Using Cpk makes it easy to track metrics to assess variation improvement for a technology. They can also be used as a gating item for technology milestone achievement. However, it is not truly an absolute value, it is a function of the specification limits.
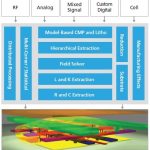
One of the big challenges is modern processes is that variation at one stage of the process can depend critically on variation at an earlier stage in the process, so the steps cannot be considered individually. Plus, with a fab cycle measured in months, and masks costs measured in millions, doing experiments on real silicon are prohibitive. At a high level, the approach GlobalFoundries used is to use structural simulation using Coventor’s SEMulator3D virtual fabrication platform. By analyzing the output it is possible to assess the knock-on effects of process changes, meaning effects later in the process. Analyzing the output it is possible to see which early factors have a major effect on variation later in the process, and thus where to focus the effort for improvement. On the other hand, factors which make little difference later can be left alone.
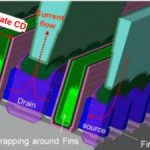
Structural simulation in SEMulator3D works by taking a specification of all the process parameters along with the layout data. SEMulator3D then builds up the result of building that layout on the process with those particular parameters. This structural output can then be used to derive electrical and other data. The picture at the top of this blog entry shows some example output, the bright green being the gates for the FinFets and the purple are the fins themselves. SEMulator3D has modules that understand the implications of almost everything that might be used in a process such as directional deposition, anisotropic etch, chemical mechanical polishing (CMP), implant and so on. Just as in actual fabrication, the virtual fabrication lays the various steps down one after another and builds up the outcome. But in the form of a 3-dimensional model of the outcome rather than an actual chip, of course. In a lot less time. For no mask or fab charges.
The example that Rohit went into in detail was FinFET gate height. Insufficient gate-height was identified as a yield problem. But gate-height is influenced by many steps (fin definition, dummy poly definition, junction, poly open, work function patterning, tungsten fill, tungsten etching, CMP and probably more). For example, the picture below shows an adjustment made to eSiGe Space RIE (reactive ion etching). After simulating more steps, you can easily see visually a big difference in the eSiGe epitaxy.
For the gate height improvement, a 9 factor two level DOE was executed and based on the simulation they could determine that Fin reveal, poly CMP, poly open CMP and tungsten CMP were statistically significant. So the specification limits were redefined and the variation spread amongst the contributing steps.
For example, one step is poly open CMP. The original process had poor yield and an unnaceptably Cpk of 0.36. By adding additional steps to the process using a two level deposition before the first CMP and then doing a second Cmp got the Cpk up to 1.1.
The conclusion is that the Cpk approach along with structural simulations (Coventor’s SEMulator3D) and physical to physical, electrical and yield correlations were used to define specification limits for physial measurements. Gate height variations for 14nm FinFET technology was successfully improved using this methodology.
The slides for Rohit’s presentation are here.