
It goes without saying that VIPs really play a Very Important Part in SoC verification today. It has created a significant semiconductor market segment in the fabless world of SoC and IP design & verification. In order to meet the aggressive time-to-market for IPs and SoCs, it’s imperative that readymade VIPs which are proven with latest specifications must be used to accelerate the complex task of verifying SoCs. And that can happen when there are easy methods available for integrating VIPs into the SoC testbenches and testing them.
It was a pleasant surprise to see this videofrom Cadencewhich demonstrates the integration of PCI Express VIP in UVM Environment with such clarity in just about five minutes. I didn’t think it was so easy to learn. Since Cadence acquired Denali, it has always been ahead in keeping up with the latest specs for PCIe VIP, providing the broadest range of PCIe VIPs covering most of the applications including mobile and cloud, very advanced compliance testing and superb debugging environment. No wonder Cadence is continually advancing in this area of business. The maturity of Cadence’s experience in VIP business is reflected by the kind of seamless integration environment it provides.
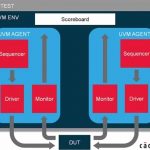
In the UVM environment, multiple agents are put together to stimulate the design, collect coverage and perform self-checking, thus enabling verification of multi-layer components such as PCIe VIP.
The PCIe VIP is integrated into the UVM test environment as UVM agent; multiple agents are encapsulated under the UVM environment. There are active and passive end points to stimulate and monitor the behaviour of the design.
Cadence provides PCIe UVM agent with the installation which can be used straightaway to start verification or it can be customized as per user requirement. The basic verification components such as sequencer, driver and monitor can be extended from the UVM agent. Let’s look at some glimpses of the code which is used to set properties, configure the verification components, and create and instantiate verification components and so on.
On the left side, there is code to set properties for the activeRC component. On the right, there is code for configuring the verification component by extending cdnPcieUvmConfigFunction which is extended from UVM config object. It contains all the functions and attributes of verification. The VIP checks the consistency of all these functions and attributes before starting the verification. The configuration can also be done with graphical interface which allows setting all functions and attributes and checking their consistency.
Above is the code for instantiating and creating verification components. On the left, there is code for instantiating a verification component and virtual sequencer. On the right, the verification component and the virtual sequencer has been created. And a connection between the virtual sequencer and the sequencer of the UVM agent is also created.
Above is the simulation result which can provide very detailed analysis for easy debugging.
This morning, while writing this article, there was another pleasant moment to see Eric Steve’s articleon semiwiki which says about the release of PCI Express 4.0 specifications and its complex features which are already included in Cadence PCIe VIP.
It’s a worthwhile 5 minutes video(presented in a very candid manner by Amir Attarhaof Cadence) to look at and learn how a VIP can boost the productivity of a verification engineer, simplify protocol compliance and shorten the design cycle to meet the short window of opportunity. It’s a must watch for design and verification engineers, students raring to get into semiconductor SoC and IP specialization and others in the semiconductor community.
More Articles by Pawan Fangaria…..
lang: en_US

