While FinFET yield controversy is going on, I see a lot being done to improve that yield by various means. One prime trend today, it must be, it’s worthwhile, is to pull up various signoffs as early as possible during the design cycle. And DFM signoff is a must with respect to yield of fabrication. This reminds me about my patents filed about 6 years ago while I was at Cadence, they dealt with bringing lithography awareness in the design much earlier at the custom floorplanning and layout stage; it might have been too early a methodology to pick up at that time. But now with 14nm and 16nm process nodes and FinFET technology it has become a necessity, that’s my pleasure to feel proud about it 🙂
This day, I am impressed after seeing one of the Samsungpresentations at DACthis year where KK Lin of Samsung tells about Samsung’s readiness with 14LPE and 14LPP technologies and how they have streamlined their process, flow and overall solution to make a design DFM hotspot free for better yield. Samsung is ready with PDKs, libraries, IPs, and design kits for these technologies. After prototyping, the mass production is scheduled by the end of this year. The presentation conveys about their leading 14nm technology which has smallest gate pitch (CPP), innovative constructs for connecting gates in most compact manner and smallest area memory (SRAM) solution. Let’s see their effective and innovating approach for DFM signoff.
In their new DFM solution, Samsung offers DFM kits which can be inserted into design flows, thus enabling designers to seamlessly signoff the design for DFM.
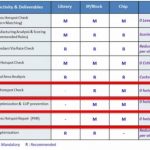
Samsung 14nm DFM requirements are as listed in the above table; some are mandatory and some are recommended for better design differentiation at library, IP and chip level. The Process Hotspot Repair (PHR) and CMP Hotspot Check are mandatory requirements without any tolerance for hotspot.
Samsung uses pattern matching for DFM checking which can represent very complex patterns pretty fast compared to model simulation method; using traditional DRC also can be very complicated with lengthy code writing for this purpose and is not recommended. The pattern matching method provides a viable safety net to capture and repair all known issues from silicon.
The PHR flow is based on CadenceDFM pattern analysis tool, Litho Physical Analyzer (LPA) and integrated with Encounter EDI environment, qualified for 14nm process. The pattern library is created from process hotspot patterns found on wafers. After P&R of design, the patterns are detected using LPA and fixed in the same environment until signoff. Very fast detection and high fixing rate (>95%) has been observed using this flow without any timing impact on the design, thus improving the yield. The minimum set of remaining hotspots is fed-forward to process team for monitoring.
As designers need to see how friendly their design is to fab with respect to CMP, and would need to feed-forward the results to fab, this flow involving calibration for CMP model and prediction of CMP hotspots in the design has been developed by Samsung in collaboration with Cadence. In CMP model validation, it has been observed that actual measurements and simulation results are very closely correlated (~90%) for different step heights, thus increasing the confidence for capturing hotspots.
Very recently, Samsung and Cadence collaborated together to develop a block based analysis flow for designers to run CMP analysis during design implementation and remove CMP hotspots in-design. CMP correction later can be very difficult, time consuming and costly affair. The halo mimics a virtual neighboring environment which is obtained by silicon data analysis, distribution of silicon in terms of density and line width. Reasonable halo conditions are decided for block level simulation. Samsung provides this solution in its CMP model offering.
So, broadly what is done for CMP hotspot detection? Extraction of critical geometry information from design db, analysis of various attributes such as interlayer dielectric (ILD) height & thickness, surface height and Cu thickness, their comparison with the threshold values and identification of hotspots on the chip.
Samsung provides complete package for DFM solution including the kit, model, block level flow and also fixing guidelines based on silicon distribution that includes suggestions such as narrowing, removing, widening or adding dummy patterns among others.
This was a nice learning to know about a differentiated solution for DFM signoff that is Samsung foundry certified with the flow enabled by state-of-the-art tools from Cadence. View the on-line presentation here for more details. Click the link against “Foundry DFM Requirements with Cadence In-Design, Signoff DFM”.
Do we get the desired yield with 14nm FinFET? I think we need to wait until 2015, it’s not too far!