If we look back in the last century, performance and area were two main criteria for semiconductor chip design. All design tools and flows were concentrated towards optimizing those two aspects. As a result, density of chips started increasing and power became a critical factor. Now, Power, Performance and Area (PPA) are looked together as the prime criteria for SoCs. Since the beginning of this century the semiconductor industry (including technology, design and software) worked tremendously to optimize PPA for semiconductor chips; the latest technologies being FinFET and FD-SOI.
Today, we have started seeing temperature as a key criterion for consideration in the semiconductor design. Like PPA, temperature acts as a basic criterion at the device and chip levels. We are seeing state-of-the-art tools in the market for thermal analysis of chips and packages. Temperature is a key criterion for hand-held mobile, automotive, and storage devices and therefore for SoCs in that space.
While PPA and temperature (PPAT) definitely need to be looked at as the base criteria, my emphasis in this article is to look at the SoCs in a new context today where there are other major factors which can dominate over these basic criteria; in fact some of the other major factors effectively drive the PPAT for SoCs. There is already lot of work done for PPA and is on the table to be exploited and used in the larger context of SoCs. So, let’s look at the major factors which drive modern SoC design.
Target Segment: The days when one particular processor like IntelPentium used to address most of the computing market needs around the world are no more. Today, we have multiple segments within one market. For example, within computing or processing space, we have desktops, laptops, tablets, smartphones, and so on. Each of these addresses a particular segment in the computing space and can have varying needs. A desktop processor can be less power efficient than a tablet or smartphone processor. Similarly, an SoC for automotive application can be less area efficient than an SoC for smartphone. Again, even for a particular segment it’s not one market across the geography, the markets are further segmented across the geographical regions. A live example is about smartphone markets in USA, China, India, and so on; they are different. Hence, an SoCs should to be planned according to its target segments for what is needed in that segment, and more importantly for how long that design can survive in that market. Otherwise, you may provide the best PPA, but it can still fail in a particular market. Again, power and performance have to balance against each other; today there is no more leeway to gain on both fronts without cost and other implications.
Cost: Today, cost no longer rules the market. The market drives the cost. At the same time, wafer cost at lower nodes is increasing to an extent that the cost per transistor may not reduce substantially with further technology scaling. So, the SoCs need to be architected with appropriate functionality according to the market need and the cost which it can absorb. It’s extremely important to plan the BOM (Bill of Material) upfront according to the cost and profitability. An SoC with similar functionality can have variants with different fabrics and PPAs for different markets according to their cost structures. A recent example is about Qualcommlaunching its mid-range lines of 4G baseband processors, Snapdragon 618, 620, 415 and 425, specifically to compete in China market where MediaTekis aggressively gaining in 4G LTE chipset market with its low priced chipsets. Also, Intel is eyeing emerging markets with its low-end SoFIA processors. The upcoming IoT market will further establish ‘cost’ as a major factor for SoCs, because ‘low-cost and high-volume’ will be the key characteristic of various segments in the IoT market.
A more important observation related to cost, as I see it from business angle, is that the companies (or divisions in large companies) need to be swift in aligning their product line, R&D, procurement, and manufacturing processes according to the market segment they serve; otherwise they can never meet the cost structure of the market. It is okay for Intel to initially indulge in the so called “contra-revenue model” to gain mobile market share, but gradually, rather rapidly, it has to align the mobile product line according to the cost structure of that market.
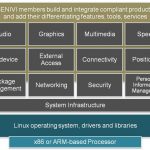
Functionality: After firming up the top level business strategies for target segment and cost, the actual stage comes where an SoC is architected according to the requirement and driven to implementation. The functionality must come as the top consideration in implementation because that will justify the cost and target segment as explained above. One has to consider, what kind of CPU and with how many cores should be employed, is a GPU required, how much on-chip and expandable memory should be sufficient, memory controllers, interfaces, communication components, and many more. Today, there can be hundreds of functional components on an SoC and there is a lot to choose from for each component. This mandates to decide on the functionality you are going to support for a particular segment at a particular cost.
IP integration: Once the functionality is defined, not all components can be done by one company. There comes IP for various components supplied by vendors across the world. So, here the actual exercise is to choose the best PPA optimized IP for your SoC and best integration methodology for overall PPA optimization of the SoC. This optimization is at a different level where you have to architect the data traffic and communication between different components in most optimized manner to consume lowest power and have lowest latency with minimum congestion in the network. There is Network-on-Chip (NoC) available which can be utilized to manage traffic and minimize power consumption of the overall SoC. Here is an example of how Texas Instrumentsused ArterisFlexNoC in its SimpleLink Wi-Fi Family of SoCs for internet-on-a-chip solution for IoT market in home automation, safety and security, energy harvesting, industrial M2M and wireless audio streaming. This is well architected with NoC fabric to work at extremely low power. The NoC is utilized to shut down the components which are not required for a particular mode of the chip’s operation.
[Courtesy Texas Instruments: TI CC3100 Hardware Overview]
This is a very simplistic, but smart design. Imagine a design where there can be several digital and analog components and high speed interfaces that connect wires getting into and coming out of the analog IPs at different levels of voltages. The floorplanning of those IPs, IOs and busses are critical along with the software that can model the channels in the floorplan. Also, while selecting an IP, looking at its PPA in isolation is not sufficient. There can be situations where more IPs when combined together can produce innovative results. Let’s keep that aside for a more detailed article later.
System Performance: It you count on a CPU performance, it’s simply the product of IPC (instructions executed per clock) and the clock frequency. With the technology scaling, clock frequency has almost reached its limits; although with significant increase in leakage power at lower technology nodes. Also frequency itself has implications on power. The other avenues to increase CPU performance by increasing IPC include techniques such as ILP (instruction level parallelism). Several other techniques such as SIMD (Single Instruction Multiple Data) have been used to reduce the number of instructions for a task.
That was the case for a single CPU. Today, we need to look at the performance in terms of the whole system’s performance. The CPUs can have multiple cores which provide high performance with optimized power. However, to exploit the multi-core architecture, several aspects have to be considered in the SoC design. These aspects may include the number of cores ideal for an SoC requirement, special cores for graphics, speech recognition, communication protocols, cache subsystem architecture, RAM (Random Access Memory), memory access mechanisms, and so on. So, one has to consider actual definition of performance as “time taken to execute a task” and consider the complete system performance while designing an SoC. Also, considerations have to be made for how different types of software would make use of the multiple cores.
Size: The size of a chip should not be confused with the density of transistors a technology node can provide. It’s the architecture and space utilization on the chip that matters. So, it’s the absolute size of the chip which needs to be considered; can it be architected with required functionality within the parameters of the size for a particular market segment. If a robust architecture can satisfy the size with the required PPA at a higher technology node, then that’s the best scenario. One does not need to use lower node process unless essential. In cases of GPUs where there are parallel workloads, higher density of transistors (and hence lower technology nodes) can definitely improve performance almost linearly; so lower technology should be considered there. From a business perspective, size can be extremely important in wearable segment of mobile and IoT market. So, size of the actual SoC is an important criterion to consider before architecting.
I would like to take a pause here as it is getting lengthy. However, there are other important and interesting criteria to consider for SoCs (e.g. h/w, s/w, embedded and so on). I will talk about those later in part-2 of this article.