The Nanoprocessor is a mostly-forgotten processor developed by Hewlett-Packard in 19741 as a microcontroller2 for their products. Strangely, this processor couldn’t even add or subtract,3 probably why it was called a nanoprocessor and not a microprocessor. Despite this limitation, the Nanoprocessor powered numerous Hewlett-Packard devices ranging from interface boards and voltmeters to spectrum analyzers and data capture terminals.4 The Nanoprocessor’s key feature was its low cost and high speed: Compared against the contemporary Motorola 6800,7 the Nanoprocessor cost $15 instead of $360 and was an order of magnitude faster for control tasks.
Recently, the six masks used to manufacture the Nanoprocessor were released by Larry Bower, the chip’s designer, revealing details about its design. The composite mask image below shows the internal circuitry of the integrated circuit.5 The blue layer shows the metal on top of the chip, while the green shows the silicon underneath. The black squares around the outside are the 40 pads for connection to the IC’s external pins. I used these masks to reverse-engineer the circuitry of the processor and understand its simple but clever RISC-like design.6
Combined masks from the Nanoprocessor. Click for larger image. “
GLB“, to the left of the data bus, stands for the designers George Latham and Larry Bower. Files courtesy of Antoine Bercovici.
The Nanoprocessor was designed in 1974, the same year that the classic Intel 8080 and Motorola 6800 microprocessors were announced. However, the Nanoprocessor’s silicon fabrication technology was a few years behind, using metal-gate transistors rather than silicon-gate transistors that were developed in the late 1960s. This may seem like an obscure difference, but silicon gate technology was much better in several ways. First, silicon-gate transistors were smaller, faster, and more reliable. Second, silicon-gate chips had a layer of polysilicon wiring in addition to the metal wiring; this made chip layouts about twice as dense.8 Third, metal-gate circuitry required an additional +12 V power supply. The Intel 4004 processor used silicon gates in 1971, so I’m surprised that HP was still using metal gates in 1974.9
A bizarre characteristic of the Nanoprocessor is its variable substrate bias voltage. For performance reasons, many 1970s microprocessors applied a negative voltage to the silicon substrate, with -5V provided through a bias pin.10 The Nanoprocessor has a bias pin, but strangely the bias voltage varied from chip to chip, from -2 volts to -5 volts. During manufacturing, the required voltage was hand-written on the chip (below). Each Nanoprocessor had to be installed with a matching resistor to provide the right voltage. If a Nanoprocessor was replaced on a board, the resistor had to be replaced as well. The variable bias voltage seems like a flaw in the manufacturing process; I can’t imagine Intel making a processor like that.
The HP Nanoprocessor, part number 1820-1691. Note the hand-written voltage “-2.5 V”. The last digit (1) of the part number is also hand-written, indicating the speed of the chip. Photo courtesy of Marc Verdiell.
Like most processors of that era, the Nanoprocessor was an 8-bit processor. However, it didn’t use RAM, but ran code from an external 2-kilobyte ROM. It contained 16 8-bit registers, more than most processors and enough to make up for the lack of RAM in many applications. Based on transistor count, the Nanoprocessor is more complex than the Intel 8008 (1972) and slightly less complex than the 6800 (1974) or 6502 (1975).11 Its architecture uses its transistor count on different purposes from these processors, though. The Nanoprocessor lacks ALU functionality but in exchange, it has a large register set, taking up much of the die area. The Nanoprocessor has 48 instructions, a considerably smaller instruction set than the 6800’s 72 instructions. However, the Nanoprocessor includes convenient bit set, clear, and test operations, which these other processors lacked.12 The Nanoprocessor supports indexed register access, but lacks the complex addressing modes of the other processors.
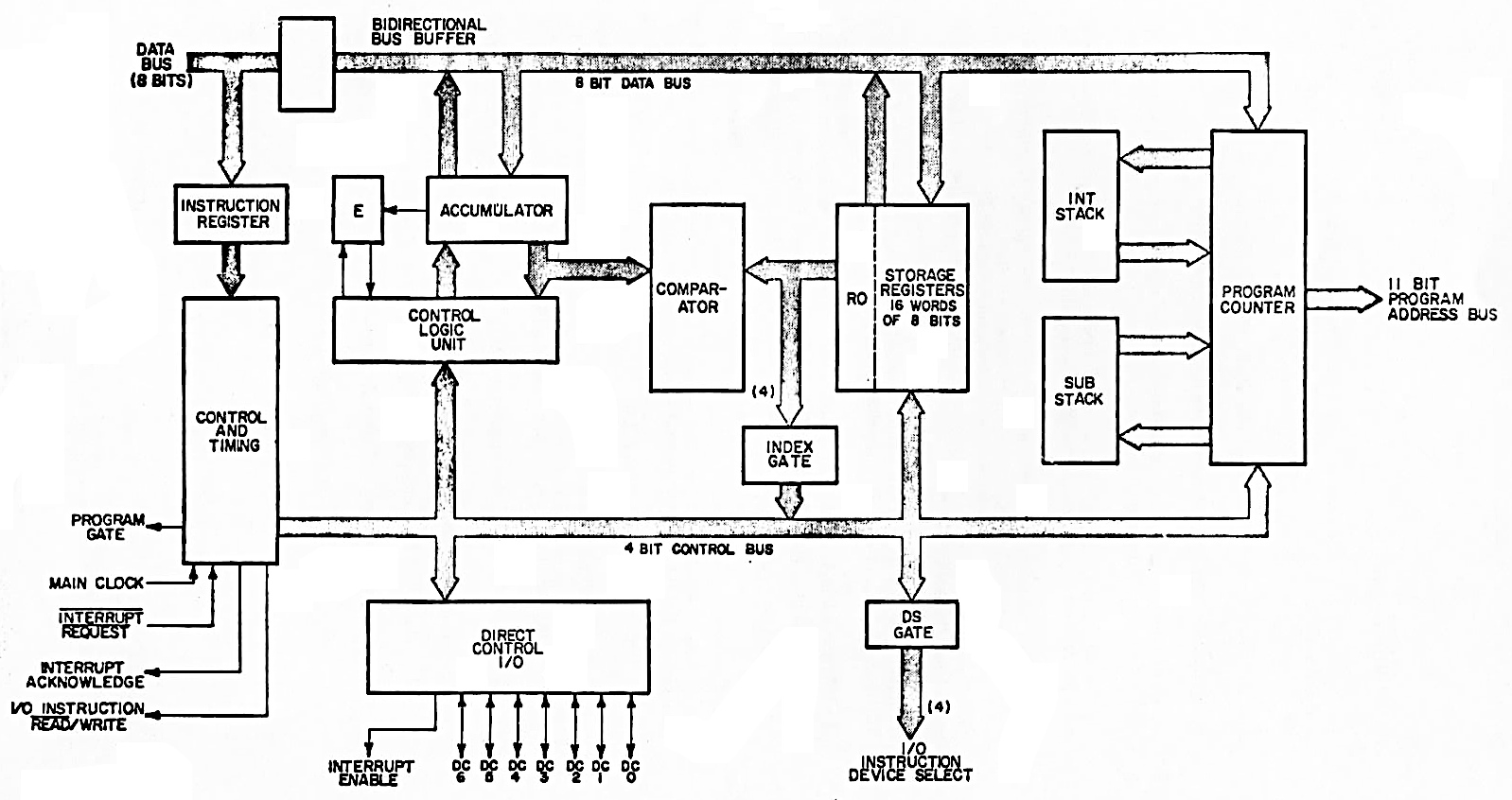
The block diagram below shows the internal structure of the Nanoprocessor. The main I/O feature is the 4-bit “I/O Instruction Device Select” which allows 15 devices to receive I/O operations. In other words, the select pins indicate which I/O device is being read or written over the data lines. External circuitry uses these signals to do whatever is necessary for the particular application, such as storing the data in a latch, sending it to another system, or reading values. More I/O is provided through seven “Direct Control I/O” pins (GPIO pins) that can be used for inputs or outputs. If not connected to external circuitry, these pins operate as convenient bit flags; the Nanocomputer can set a value and then read it back. The Control Logic Unit performs increments, decrements, shifts, and bit operations on the accumulator, lacking the arithmetic and logical operations of a standard Arithmetic/Logic Unit (ALU).
I reverse-engineered the Nanoprocessor’s circuitry from the masks and determined how the functional blocks map onto the die, below. The largest feature is the set of 16 registers in the center-left. To the right is the comparator and then the accumulator, along with its increment, decrement, shift, and complement circuitry. The instruction decoder circuitry takes up much of the space above and to the right of the comparator and accumulator. The bottom part of the chip is dominated by the 11-bit program counter, along with the one-entry interrupt stack and subroutine stack. The control circuitry implements the Nanoprocessor’s almost-trivial instruction timing: one fetch cycle followed by one execute cycle.13 In most microprocessors, the control circuitry takes up a large fraction of the chip, but the Nanoprocessor’s control circuitry is just a small block.
Understanding the masks
The chip was fabricated using six masks, each used for constructing one layer of the processor using photolithography. The photo below shows the masks; each one is a 47.2×39.8 cm Mylar sheet. These sheets are 100× enlargements of the masks used to produce the 4.72×3.98 mm silicon die (for comparison, about 33% smaller than the 6800’s die). Each 3-inch silicon wafer held about 200 integrated circuits, fabricated together on the wafer, and then tested, cut apart, and packaged.
The chip’s masks, courtesy of Antoine Bercovici
To explain the role of the masks, I’ll start with the structure of a metal-gate MOSFET, the transistor used in the Nanoprocessor. At the bottom, two regions of silicon (green) are doped to make them conductive, forming the source and drain of the transistor. A metal strip in between forms the gate, separated from the silicon by a thin layer of insulating oxide. (These layers—Metal, Oxide, Semiconductor—give the MOS transistor its name.) The transistor can be considered a switch controlled by the gate. The metal layer also provides the main wiring of the integrated circuit, although the silicon layer is also used for some wiring.
Structure of a metal-gate MOSFET.
Masks are a key part of the integrated circuit construction process, specifying the position of the components. The diagram below shows how a mask is used to dope regions of the silicon. First, the silicon wafer is oxidized to form an insulating oxide layer on top, and then light-sensitive photoresist is applied. Ultraviolet light polymerizes and hardens the photoresist, except where the mask blocks the light. Next, the soft, unexposed photoresist is dissolved. The wafer is exposed to hydrofluoric acid, which removes the oxide layer where it is not protected by photoresist. This yields holes in the oxide that match the mask pattern. The wafer is then exposed to a high-temperature gas which diffuses into the unprotected silicon regions, modifying the silicon’s conductivity. These processing steps create tiny doped silicon regions matching the masks’s pattern. As will be shown below, the other masks are used for different processing steps, but using the same photoresist-and-mask process.
How a photomask is used to dope regions of silicon.
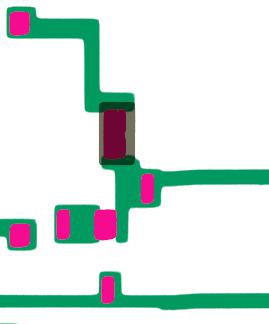
I’ll zoom in on the Nanoprocessor’s die and show how one of its circuits is constructed from the six masks. (This two-transistor circuit is an inverter, flipping the binary value of its input.) The first mask dopes regions of silicon to make them conductive, using the photolithography steps described above. The doped regions (green) will become transistor source/drains or wiring between components.
The first mask creates conductive silicon regions.
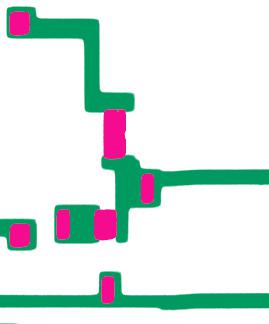
Next, the die is covered with an insulating oxide layer. The second mask (magenta) is used to etch openings in the oxide, exposing the silicon underneath. These openings will be used to create transistor gates as well as connecting metal wiring to the silicon.
The second mask creates openings in the oxide layer.
The third mask (gray) exposes a region to ion implantation, which changes the doping of the silicon, and thus the transistor’s properties. This turns the upper transistor into a special depletion-mode transistor that pulls logic gate outputs high.
The third mask is used to increase the doping of the upper transistor.
Next, the silicon is covered with an additional thin layer of insulating oxide, forming the gate oxide for the transistors. The fourth mask (orange) removes this oxide from regions that will become contacts between the silicon and the metal layer. After this step, most of the die is covered with a thick insulating oxide layer. The oxide layer is very thin over the transistor gates (magenta), and there are contact holes in the oxide from the current mask (orange).
The fourth mask creates holes in the oxide.
The fifth mask (blue) is used to create the metal wiring on top; a uniform metal layer is applied and then the undesired parts are etched off. In locations where the fourth mask created holes in the oxide, the metal layer contacts the silicon and forms a connection. In locations where the third mask created a thin oxide layer, the metal layer forms the transistor gate between two silicon regions. Finally, the entire wafer is covered with a protective glassy layer. The sixth mask (not shown) is used to form holes in this layer over the pads around the edges of each chip. Once the wafer is cut into individual silicon dies (dice?), bond wires are attached to the pads, connecting the die to the external pins.
The fifth mask creates the metal wiring.
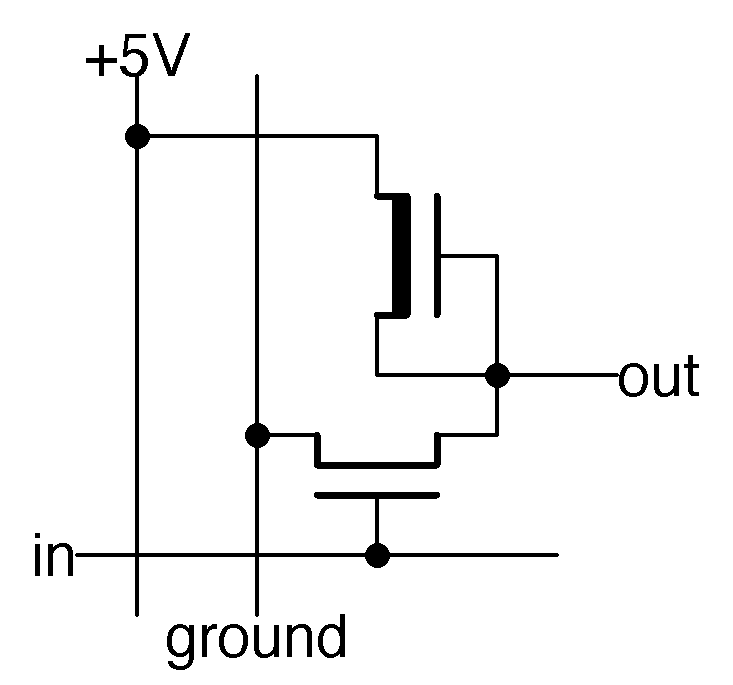
The schematic below shows how the circuitry above forms a two-transistor inverter. The two transistor symbols correspond to the two transistors created by the masks. When there is no input, the upper transistor (connected to +5 volts) pulls the output high. When the input is high, it turns on the lower transistor. This connects the output to ground, pulling the output low. Thus, the circuit inverts the output.
Schematic of an NMOS inverter, corresponding to the masks above.
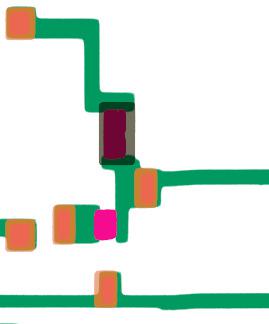
Although the diagrams above show just a single inverter, these masking steps create the entire processor with its 4639 transistors.11 The diagram below shows a larger part of the die with dozens of transistors forming more complex gates and circuitry. One cute thing I noticed on the masks is a tiny heart with HP inside, below the chip’s number.14
Chip art: HP inside a heart, below the part number 9-4332A
Controlling a clock with the Nanoprocessor
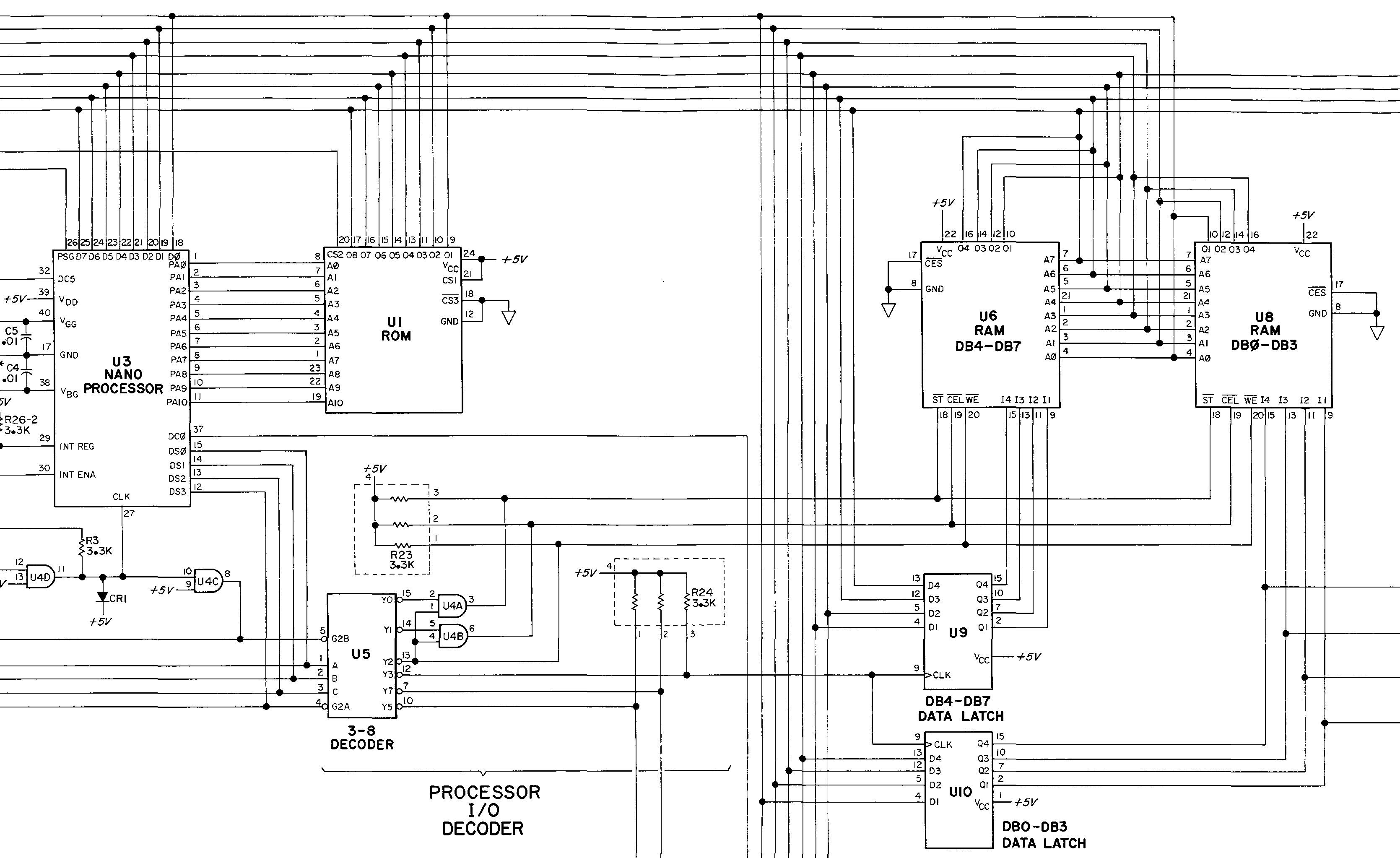
To understand how the Nanoprocessor was used in practice, I reverse-engineered the code from an HP 98035 clock module. This module was plugged into an HP desktop computer15 to provide a real-time clock, as well as millisecond-accurate timings, intervals, and periodic events. The design of the clock module was rather unusual. To preserve the time when the computer was powered-down, the clock module was built around a digital watch chip with a backup battery.17 Inconveniently, the digital watch chip wasn’t designed for computer control: it generated 7-segment signals to drive an LED, and it was set through three buttons. To read the time, the Nanoprocessor had to convert the 7-segment display outputs back into digits. And to set the time, the Nanoprocessor had to simulate the right sequence of button presses to advance through the digits.
Nanoprocessor (white chip) as part of an HP clock module. The 2-kilobyte ROM is to the left of the Nanoprocessor. The two 256-bit×4 RAM chips are to the right. The Texas Instruments clock chip is the large black chip below the green NiCad battery. Photo courtesy of Marc Verdiell.
The host computer controlled the clock module by sending it ASCII strings such as “S 12:07:12:45:00” to set the clock to 12:45:00 on December 7 (or on July 12 if the module was running in European mode). The module’s various interval timers, periodic alarms, and counters were controlled with similar commands such as “Unit 2 Period 12345”. The module supported 24 different commands, and the Nanoprocessor had to parse them. (See the manual for details.)
Here’s some sample code reverse-engineered from the clock board ROM. This code is from the interrupt handler that increases the time and date every second. The code below determines how many days in the current month so it knows when to move to the next month. The columns are the byte value, the corresponding opcode, and my description of the instruction.
|
d0 STR-0 Store the next byte (7) in register 0. |
|
07 |
|
0c SLE Skip two instructions if accumulator <= register 0. |
|
03 DED Decrement the accumulator in decimal mode |
|
5f NOP No operation |
|
d0 STR-0 Store the next byte (0x31) in register 0 |
|
31 |
|
30 SBZ-0 Skip two instruction bytes if accumulator bit 0 is zero |
|
81 JMP-1 Jump to 0x1c9 (end of this code block) |
|
c9 |
|
a1 CBN-1 Clear accumulator bit 1 |
|
d0 STR-0 Store the next byte (0x30) in register 0 |
|
30 |
|
0f SAN Skip two instruction bytes if accumulator not zero |
|
d0 STR-0 Store next byte (0x28) in register 0 |
|
28 |
This code takes a month number (01-12 BCD) in the accumulator and returns (in register 0) the number of days in the month (28, 30, or 31 BCD). Not bad for 16 bytes of code, even if it ignores leap years. How does it work? For months past 7 (July), it subtracts 1. Then, if the month is odd, it has 31 days, while an even month has 30 days. To handle February, the code clears bit 1 of the month. If the month is now 0 (i.e. February), it has 28 days.
This code demonstrates that even though a processor without addition sounds useless, the Nanoprocessor’s bit operations and increment/decrement allow more computation than you’d expect.16 It also shows that Nanoprocessor code is compact and efficient. Many things can be done in a single byte (such as bit test and skip) that would take multiple bytes on other processors.12 The Nanoprocessor’s large register file also avoids much of the tedious shuffling of data back and forth often required in other processors. Although some call the Nanoprocessor more of a state machine controller than a microprocessor, that understates the capabilities and role of the Nanoprocessor.
While the Nanoprocessor doesn’t include an ALU or have instructions for accessing RAM, these could be added as I/O devices. The clock module has 256 bytes of RAM to hold its multiple counter and timer values, accessed through four I/O ports. Other products added ALU chips to support arithmetic operations.18
Conclusions
The Nanoprocessor is an unusual processor. My first impression was that it wasn’t even a “real processor”, lacking basic arithmetic functionality. The chip was built with obsolete metal-gate technology, a few years behind other microprocessors. Most bizarrely, each chip required a different voltage, hand-written on the package, suggesting difficulty with manufacturing consistency. However, the Nanoprocessor provided high performance in its microcontroller role, much faster than other processors at the time. Hewlett-Packard used the Nanoprocessor in many products in the 1970s and 1980s, in roles that were more complex than you’d expect. strings and performing calculations.
While the Nanoprocessor has languished in obscurity, without even a mention on Wikipedia, the masks recently revealed by its designer shed light on this unusual corner of processor history. Thanks to Antoine Bercovici for scanning and remastering the masks, Larry Bower for the donation, and John Culver at The CPU Shack for sharing the donation. Thanks to Marc Verdiell for dumping the clock board ROM.
I plan to write about the internal circuitry of the Nanoprocessor so follow me on Twitter at @kenshirriff for updates on Part II. I also have an RSS feed.
Notes and references









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}