Despite the improvements in glass material used in smartphone displays, many, if not all, leading smartphone manufactures such as Apple and other smartphone manufacturers are evaluating a coating method that further increases the durability of screens at a cost of just pennies per display by coating them with diamonds.
Gorilla Glass
Corning introduced Gorilla Glass Victus on July 22, 2020, and it’s the seventh generation of Gorilla Glass. It replaces Gorilla Glass 6, which was introduced in 2018. In lab tests, Gorilla Glass Victus achieved drop performance up to 2 meters when dropped onto hard, rough surfaces. Competitive aluminosilicate glasses from other manufacturers typically fail when dropped from less than 0.8 meters, according to Corning. Gorilla Glass Victus also surpasses last year’s Corning Gorilla Glass 6 with up to a 2x improvement in scratch resistance. Additionally, the scratch resistance of Gorilla Glass Victus is up to 4x better than competitive aluminosilicate glasses.
Scratching the phone makes it much more vulnerable to breaks. according to a study in November 2018 by Allstate subsidiary SquareTrade. Cracked screens were the most common form of damage, accounting for 29% of damaged smartphones, followed by scratched screens (27%) and nonworking batteries (22%).
Dropping a phone on the ground was the culprit in 74% of these cases. American smartphone owners broke more than 50 million screens in 2017 — nearly two every second — and spent $3.4 billion to replace them. On average though, those repairs cost from $170, and for the iPhone Xs Max, that figure goes up to a staggering $329.
A total of $14 billion repairing and replacing iPhones since their debut in 2007. The survey also showed that iPhone users were six times more likely to damage their phones than lose them or have them stolen.
Two-thirds of consumers said they wouldn’t repair a damaged phone if it still worked, while 59% said they would upgrade their device rather than fix an old one.
Diamond Like Coatings
Diamond-like coatings (DLC) are used in numerous applications because of unique properties such as low friction, high hardness, and high corrosion resistance.
In addition, DLC coatings possess both high thermal conductivity and electrical resistivity. The combination of these properties is useful for applications in microelectronics, medical devices, and automotive components.
DLC coatings can be used as protective coatings on displays, sensors and flexible semiconductors, where they greatly increase durability and can extend the total life of the final product. In this article I want address the demand for DLC for displays, in light of interest by Apple and other smartphone manufacturers to keep the display glass from damage.
Background
Diamond-like carbon first appeared in the Journal of Applied Physics in 1971 entitled “Ion-Beam Deposition of Thin Films of Diamondlike Carbon.” A year later, my team at Bell Labs in Murray Hill, NJ used a penning ion beam source to bombard a graphite block to deposit DLC on a substrate. The ion beam was comprised of argon ions.
The technology took a giant leap forward when my friend, Christian Weismantel, a scientist at Karl Mark Stadt, substituted carbon-containing methane for argon as the excitation gas in 1978.
Then in 1984, Air Products and Chemicals Inc. developed technologies for producing synthetic diamonds. In 1990, “Diamonex” became an independent company after being spun off from APD.
Diamonex won a $10 contract over Morgan Crucible Co. to supply parts for the B-1 bomber, a British company. To get even, Morgan purchased Diamonex in 2001. My neighbor, David Hoover, a founder of the company, became CEO. My son plays poker with his son.
Deposition Methods
The methods for producing DLC films are broadly divided into two types: Physical Vapor Deposition (PVD) and Chemical Vapor Deposition (CVD). The PVD method uses a solid (graphite) as the carbon source and the CVD method uses a gas (a hydrocarbon such as methane). The PVD method is further divided into the arc, sputter, and laser vapor deposition methods.
The CVD method includes radio-frequency (RF), direct- current (DC) discharge, Penning ionization gauge (PIG), and self-discharge methods.
Deposition Equipment Market and Analysis
There are two suppliers of deposition equipment in this space: Intevac, which uses a sputtering technology, and privately held Denton Vacuum (Moorestown, NJ), which has developed several equipment configurations including sputtering and plasma-enhanced chemical vapor deposition (PE-CVD) that can be integrate with an ion source for ion assisted deposition or pre-clean. An analysis of these products and capabilities will be discussed in this article.
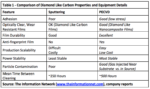
Table 1 presents an analysis of DLC films and equipment according to The Information Network’s report entitled “OLED and LCD Markets: Technology, Directions and Market Analysis.”
Table 1 compares the DLC properties and equipment for the three equipment manufacturers discussed above. There are two considerations:
- The film composition and raw materials
- The type and manufacturer of equipment
The Intevac films are diamond like carbon while the Denton Vacuum film is a diamond like nanocomposite materials. The latter may give rise to better film properties such as excellent film durability, anti-fingerprint capability, and low-cost scalability.
On the equipment side, we need to go to the origin of the technology. Intevac modified its Lean 200 Platform they used for sputtering DLC on HDD platers, limiting tool so they have to coat individual phone screens to just two displays.
Denton Vacuum’s DLC systems are not modified, but expandable for various substrate sizes, such as Gen 3.5 or Gen 6 display motherglass:
- The Voyager is a plasma-enhanced chemical vapor deposition (PE-CVD) system with a focus on diamond-like carbon (DLC) that can coat planar (ex. silicon wafers), and three-dimensional parts (ex. optical lenses). In addition, there is an optional proprietary chamber configuration to enable co-sputtering of metals during DLC deposition for metal doped DLC (Me-DLC) films. For the greatest process flexibility, a patented Denton ion source can be integrated for ion assisted deposition or pre-clean.
- The Phoenix in-line system offers high throughput for large volume production, and supports both planar and 3D component processing. This thin film deposition system can accommodate RF, AC, DC and pulsed DC sputtering as well as PE-CVD processes, and substrates or pallets up to GEN 3.5 glass size (600mm X 720mm).
Table 2 shows unit shipments and forecasts for smartphones, which are the target markets for DLC. Shipments are expected to grow from1,508 million units in 2017 to 1,721 million in 2023. There are several important facts of this table, according to The Information Network’s report entitled “Hot ICs: A Market Analysis of Artificial Intelligence, 5G, CMOS Image Sensors, and Memory Chips.”
5G smartphones will be growing at about 50% per year once Apple enters the market sometime in late 2020.
OLED displays are replacing LCD displays. The crossover in shipments is expected to o.ccur in 2020, with about 850 million units of each type will be sold
Flexible OLED displays are replacing rigid displays. The crossover should occur in 2020 when about 350 million units of each type will be sold. Charts 1 and 2 illustrate the transition from rigid to flexible displays and the small growth of foldable smartphones.
Foldable phones will exhibit slow penetration through 2023 due to high prices and durability issues.
Chart 1
Chart 2
Table 3 shows that both rigid and flexible OLED displays use Gorilla Glass (or an aluminosilicate substitute), as well as comparing construction properties of both.
DLC Equipment Market
In Intevac’s September 1, 2020 Investor presentation, the company estimated that with $200M in sales over 5 years, a 10% to 15% penetration can be achieved (slide 16). That is based on the performance of Intevac detailed in Table 1 based on a mean time between cleaning of 250 hours, Most importantly, it is based on throughput of the system – the ability to coat two displays at one time.
My analysis using data from Denton Vacuum is shown in Table 4. It is based on a model of achieving 21% penetration in year 1 growing to 57% in 2024. This model is for displays using Gen 6 Glass (1500mm x 1850mm), coating 250 5.8” displays/motherboard at one time, and a throughput of 1 motherglass per minute for the deposition of the DLC. I compare smartphone penetration for the same $200 million equipment spend between 2020 and 2024.
Synopsis
Corning recently introduced its 7thgeneration of Gorilla Glass, a chemically strengthened glass designed to be thin, light and damage-resistant. Despite improvements with each generation, glass is still susceptible to scratches, which weakens it and makes it vulnerable to breakage. In 2017, 50 million smartphone displays were broken resulting in replacement costs of $3.4 billion. Since Samsung and Apple use Gorilla Glass in their smartphones, it’s obvious a high percentage of these 50 million displays were protected with Gorilla Glass, probably Gen 6.
Three deposition companies have developed systems to coat glass, Gorilla Glass or other aluminosilicate glasses with diamond like coatings with unique properties such as low friction, high hardness, and high corrosion resistance. Intevac, a public company, has modified its HDD deposition system to coat display glass with DLC. Denton Vacuum, which has been in the equipment business for 50 years, has developed two systems for DLC, offers them at competitive prices than competitors, and achieves better film characteristics, especially durability.
Intevac’s DLC system can reach 15% penetration of smartphones over a five year period with a spend of $200 million. The Denton Vacuum DLC system can achieve a 57% display penetration in the same period for the same $200 million spend.