You are currently viewing SemiWiki as a guest which gives you limited access to the site. To view blog comments and experience other SemiWiki features you must be a registered member. Registration is fast, simple, and absolutely free so please,
join our community today!
Arm has been making noise about running large language models (LLMs) on mobile platforms. At first glance that sounds wildly impractical, other than Arm acting as an intermediary between a phone and a cloud-based LLM. However Arm are partnered with Meta to run Llama 3.2 on-device or in the cloud, apparently seamlessly. Running… Read More
While I usually talk about AI inference on edge devices, for ADAS or the IoT, in this blog I want to talk about inference in the cloud or an on-premises datacenter (I’ll use “cloud” below as a shorthand to cover both possibilities). Inference throughput in the cloud is much higher today than at the edge. Think about support in financial… Read More
Many of the most compelling applications for Artificial Intelligence (AI) and Machine Learning (ML) are found on mobile devices and when looking at the market size in that arena, it is clear that this is an attractive segment. Because of this, we can expect to see many consumer devices having low power requirements at the edge with… Read More
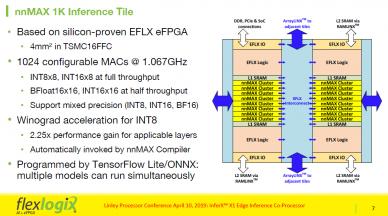
Dr. Cheng Wang, Co-Founder and SVP Engineering at Flex Logix, presented the second talk in the ‘AI at the Edge’ session, at the just concluded Linley Spring Processor Conference, highlighting the InferX X1 Inference Co-Processor’s high throughout, low cost, and low power. He opened by pointing out that existing inference solutions… Read More
One of the great pleasures in what I do is to work with people who are working with people in some of the hottest design areas today. A second-level indirect to be sure but that gives me the luxury of taking a broad view. A recent discussion I had with Kurt Shuler (VP Marketing at Arteris IP) is in this class. As a conscientious marketing… Read More