You are currently viewing SemiWiki as a guest which gives you limited access to the site. To view blog comments and experience other SemiWiki features you must be a registered member. Registration is fast, simple, and absolutely free so please,
join our community today!
Artificial intelligence (AI) and machine learning (ML) are hot topics. Beyond the impact these technologies are having on the world around us, they are also having impact on the semiconductor and EDA ecosystem. I posted a blog last week that discussed how Cadence views AI/ML, both from a tool and ecosystem perspective. The is one… Read More
Artificial intelligence (AI) is everywhere. The rise of the machines is upon us in case you haven’t noticed. Machine learning (ML) and its associated inference abilities promise to revolutionize everything from driving your car to making breakfast. We hear a lot about the macro, end-product impact of this technology, but there… Read More
Block floating point (BFP) has been around for a while but is just now starting to be seen as a very useful technique for performing machine learning operations. It’s worth pointing out up front that bfloat is not the same thing. BFP combines the efficiency of fixed point operations and also offers the dynamic range of full floating… Read More
Back in May I wrote an article on the new Speedster7t from Achronix. This chip brings together Network on Chip (NoC) interconnect, high speed Ethernet and memory connections, and processing elements optimized for AI/ML. Speedster7t is a very exciting new FPGA that can be used effectively to accelerate a wide range of processing… Read More
My first DAC was in 1987 so I’ve seen our industry expand greatly over the years, and I expect that #57DAC on July 19-23, 2020 in SFO to be another exciting event to attend for semiconductor professionals from around the globe. What makes DAC so compelling for me to visit are the people, exhibitors, panel discussions, technical… Read More
I previously blogged on the GLOBALFOUNDRIES (GF) Technology Conference (GTC) held in Santa Clara, CA. The main takeaway that I shared in that blog was that GF’s announced “pivot” to a specialty foundry announced over a year ago, including its decision not to pursue 7nm and smaller nodes, appears to be working and GF is gaining momentum.… Read More
For decades development work on Artificial Intelligence (AI) and Machine Learning (ML) was done on traditional CPUs and memory configurations. Now that we are in the “hockey stick” upturn in deployment of AI and ML, the search is on for the most efficient types of processing architectures. The result is a wave of development for… Read More
On August 27, 2018, GLOBALFOUNDRIES (GF) announced that they were no longer going to compete in the race to the next smaller semiconductor node, at that time, the 7nm node. While surprising to some, on further analysis this move made sense. TSMC had announced its plan to invest around $25B in the 5nm technology node. GF revenue is … Read More
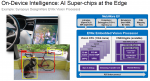
This is the third and final blog I have written about the recent AI Hardware Summit held at the Computer History Museum in Mountain View, CA. Day 1 of the conference was more about solutions in the data center, whereas Day 2 was primarily around solutions at the Edge. This presentation from Day 2 was given by Dr. Thomas Anderson, Head,… Read More