

During the 2010-decade, the benefits of Moore’s law began to fall apart. Moore’s law stated transistor density doubled every two years, the cost of compute would shrink by a corresponding 50%. The change in Moore’s law is due to increased in design complexity the evolution of transistor structure from planar devices, to Finfets. Finfets need multiple patterning for lithography to achieve devices dimensions to below 20-nm nodes.
At the beginning of this decade, computing needs have exploded, mostly due to proliferation of datacenters and due to the amount of data being generated and processed. In fact, adoption of Artificial Intelligence (AI) and techniques like Machine Learning (ML) are now used to process ever-increasing data and has led to servers significantly increasing their compute capacity.
Servers have added many more CPU cores, have integrated larger GPUs used exclusively for ML, no longer used for graphics, and have embedded custom ASIC AI accelerators or complementary, FPGA based AI processing. Early AI chip designs were implemented using larger monolithic SoCs, some of them reaching the size limit imposed by the reticle, about 700mm2.
At this point, disaggregation into a smaller SoC plus various compute and IO chiplets appears to be the right solution. Several chip makers, like Intel, AMD or Xilinx have select this option for products going into production. In the excellent white paper from The Linley Group, “Chiplets Gain Rapid Adoption: Why Big Chips Are Getting Small”, it was shown that this option leads to better costs compared to monolithic SoCs, due to the yield impact of larger.
The major impact of this trend on IP vendors is mostly on the interconnect functions used to link SoCs and chiplets. At this point (Q3 2021), there are several protocols being used, with the industry trying to build formalized standards for many of them.
Current leading D2D standards includes i) Advanced Interface Bus (AIB, AIB2) initially defined by Intel, and now has offered royalty free usage, ii) High Bandwidth Memory (HBM) where DRAM dies are stacked on each other on top of a silicon interposer and are connected using TSVs, iii) Open Domain-Specific Architecture (ODSA) subgroup, an industry group, has defined two other interfaces, Bunch of Wires (BoW) and OpenHBI.
Heterogeneous chiplet design allows us to target different applications or market segments by modifying or adding just the relevant chiplets while keeping the rest of the system unchanged. New developments could be launched quicker to the market, with significantly lower investment, as redesign will only impact the package substrate used to house the chiplets.
For example, the compute chiplet can be redesigned from TSMC 5nm to TSMC 3nm to integrate larger L1 cache or higher performing CPU cores, while keeping the rest of the system unchanged. At the opposite end of the spectrum, only the chiplet integrating SerDes can be redesigned for faster rates on new process nodes offering more IO bandwidth for better market positioning.
Intel PVC is a perfect example of heterogeneous integration (various functional chiplet, CPU, switch, etc.) that we could call vertical integration, when the same chip maker owns the various chiplet components (except for memory devices).
Chip maker developing SoCs for high-end applications, such as HPC, datacenter, AI or networking are likely to be early adopters for chiplet architectures. Specific functions, like SRAMs for larger L3 cache, or AI accelerators, either Ethernet, PCIe or CXL standards should be the first interface candidate for chiplet designs.
When these early adopters have demonstrated the validity of heterogeneous chiplets leveraging multiple different business models, and obviously the manufacturing feasibility for test and, packaging, it will create an ecosystem will have been create that is critical to support this new technology. At this point, we can expect a wider market adoption, not only for high-performance applications.
We could imagine that heterogeneous products can go further, if a chip maker will launch on the market a system made of various chiplets targeting compute and IO functionality. This approach makes convergence on a D2D protocol mandatory, as an IP vendor offering chiplets with an in-house D2D protocol is not attractive to the industry.
An analogy to this, is the SoC building in the 2000’s, where semiconductor companies transition to integrating various design IPs coming from different sources. The IP vendors of the 2000’s will inevitably become the chiplet vendors of the 2020’s. For certain functions, such as advanced SerDes or complex protocols, like PCIe, Ethernet or CXL, IP vendors have the best know-how to implement it on silicon.
For complex Design IP, even if simulation verification has been run before shipping to customers, vendors have to validate the IP on silicon to guarantee performance. For digital IP, the function can be implemented in FPGA because it’s faster and far less expensive than making a test chip. For mixes-signal IP, like a SerDes based PHY, vendors select the Test Chip (TC) option allowing to silicon enabling them characterize the IP in silicon before shipping to customer.
Even though a chiplet is not simply a TC, because it will be extensively tested and qualified before being used in the field, the amount of incremental work to be done by the vendor to develop a production chiplet is far less. In other words, the IP vendor is the best positioned to quickly release a chiplet built from his own IP and offer the best possible TTM and minimize risk.
The business model for heterogeneous integration is in favor of various chiplets being made by the relevant IP vendor (eg. ARM for ARM-based CPU chiplets, Si-Five for Risc-V based compute chiplets and Alphawave for high-speed SerDes chiplets) since they are owner of the Design IP.
None of this prevents chip makers to design their own chiplets and source complexe design IPs to protect their unique architectures or implement house-made interconnects. Similar to SoC Design IP in the 2000’s, the buy or make decision for chiplets will be weighted between core competency protection and sourcing of non-differentiating functions.
We have seen that the historical and modern-day Design IP business growth since the 2000’s has been sustained by continuous adoption of external sourcing. Both models will coexist (chiplet designed in-house or by an IP vendor) but history has shown that the buy decision eventually over takes the make.
There is now consensus in the industry that a maniacal focus on achieving Moore’s law is not valid anymore for advanced technology nodes, eg. 7nm and below. Chip integration is still happening, with more transistors being added per sq. mm at every new technology node. However, the cost per transistor is growing higher every new node as well.
Chiplet technology is a key initiative to drive increased integration for the main SoC while using older nodes for other functionality. This hybrid strategy decreases both the cost and the design risk associated with integration of other Design IP directly onto the main SoC.
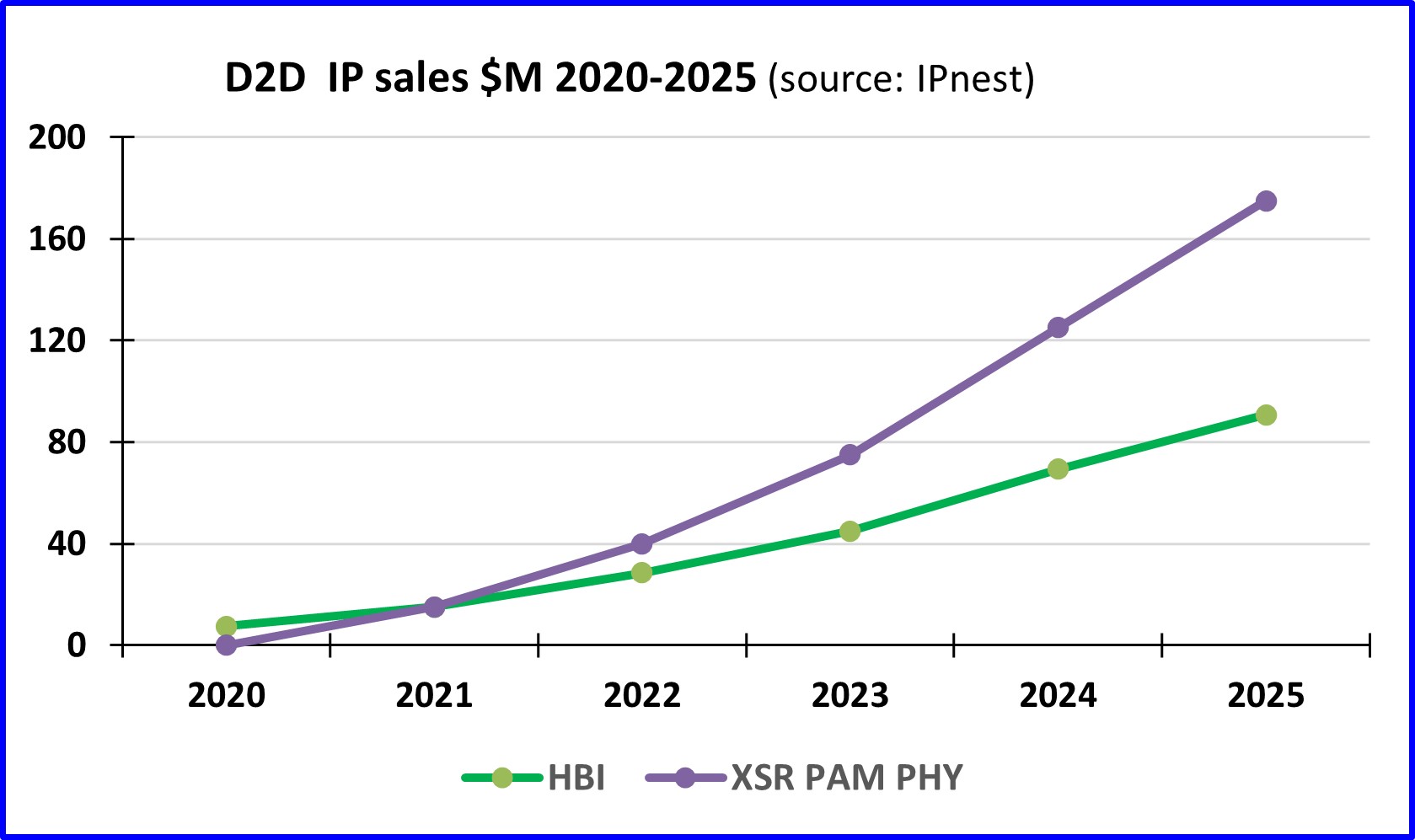
IPnest believes this trend will have two main effects in the interface IP business, one will be the strong growth of D2D IP revenues soon (2021-2025), and the other is the creation of the heterogenous chiplet market to augment the high-end silicon IP market.
This market is expected to consist of complex protocols functions like PCIe, CXL or Ethernet. IP vendors delivering interface IP integrated in I/O SoCs (USB, HDMI, DP, MIPI, etc.) may decide to deliver I/O chiplets instead.
The other IP categories impacted by this revolution will be SRAM memory compiler IP vendors, for L3 cache. By nature, the cache size is expected to vary depending on the processor. Nevertheless, designing L3 cache chiplet can be a way for IP vendor to increase Design IP revenues by offering a new product type.
As well, the NVM IP category can be positively impacted, as NVM IP are no longer integrated in SoCs designed on advanced process nodes. It would be a way for NVM IP vendors to generate new business by offering chiplets.
We think that FPGA and AI accelerator chiplets will be a new source of revenues for ASSP chip makers, but we don’t think they can be strictly ranked as IP vendors.
If Interface IP vendors will be major actors in this silicon revolution, the silicon foundries addressing the most advanced nodes like TSMC and Samsung will also play a key role. We don’t think foundries will design chiplets, but they could make the decision to support IP vendors and push them to design chiplets to be used with SoCs in 3nm, like they do today when supporting advanced IP vendors to market their high-end SerDes as hard IP in 7nm and 5nm.
Intel’s recent transition to 3rd party foundries is expected to also leverage third party IPs, as well as heterogenous chiplet adoption by semiconductor heavyweights. In this case, no doubt that Hyperscalars like Microsoft, Amazon and Google will also adopt chiplet architectures… if they don’t precede Intel in chiplet adoption.
By Eric Esteve (PhD.) Analyst, Owner IPnest
Also Read:
IPnest Forecast Interface IP Category Growth to $2.5B in 2025
Design IP Sales Grew 16.7% in 2020, Best Growth Rate Ever!
How SerDes Became Key IP for Semiconductor Systems
Share this post via:



TSMC CoWoS versus Intel EMIB Semiconductor Packaging