
Artificial Intelligence (AI) has witnessed explosive growth in applications across various industries, ranging from autonomous vehicles and natural language processing to computer vision and robotics. The AI embedded semiconductor market is projected to reach $800 billion by year 2030. Compare this with just $48 billion back in 2020. [Source: May 2022 IBS Report]. Computer vision driven applications drive a significant part of this incredible growth projection. Real-time AI examples in this space include drones, automotive applications, mobile cameras and digital still cameras.
The advent of AlexNet more than a decade ago was a major advancement in the realm of object detection compared to erstwhile methods. Since then, convolution neural network (CNN) models have been the dominant method of implementing object detection using digital signal processors (DSP). While the CNN model has evolved to be able to deliver a 90% accuracy level, it requires a lot of memory. More memory means higher power consumption. In addition, advances in memory performance have not kept pace with advances in compute performance, impacting efficient data movement.
Over the last few years, transformer models which were originally developed for natural language processing have been adapted for object detection purposes with 90% accuracy. But they are more demanding on compute capacity compared to CNNs. So, a combination of CNNs and transformers is a better solution for leveraging the best of both worlds, which in turn is pushing the demand for increasingly complex AI models and the need for real-time processing using specialized hardware accelerators.
As the network models are evolving, the number of cameras per application, image size and resolution are also increasing dramatically. While accuracy is a critical requirement, performance, power, area, flexibility and implementation costs are key decision factors too. These factors are driving the decisions on AI accelerator architectures and Neural Processing Units (NPUs) and DSPs are emerging as key components, each offering unique strengths to the world of AI.
Use DSP or NPU or Both for Implementing AI Accelerators
DSPs do provide more flexibility than NPUs. Using a vector DSP, AI can be implemented in software. DSPs can perform traditional signal processing as well as lower performance AI processing with no additional area penalty. And a vector DSP can be used to support functions that cannot be processed on an NPU.
On the other hand, NPUs can be implemented to accelerate all common AI network models such as CNN, RNN, transformers, and recommenders. For multiply-accumulate (MAC) dominated AI workloads, NPUs are more efficient in terms of power and area. In other words, for mid to high-performance AI needs, an NPU-approach is better than a DSP approach.
The bottom line is that except for low-end AI requirements, an NPU approach is the way to go. But as AI network models are rapidly evolving, for future proofing one’s application, a DSP-NPU combination approach is the prudent solution.
AI Accelerator Solutions from Synopsys
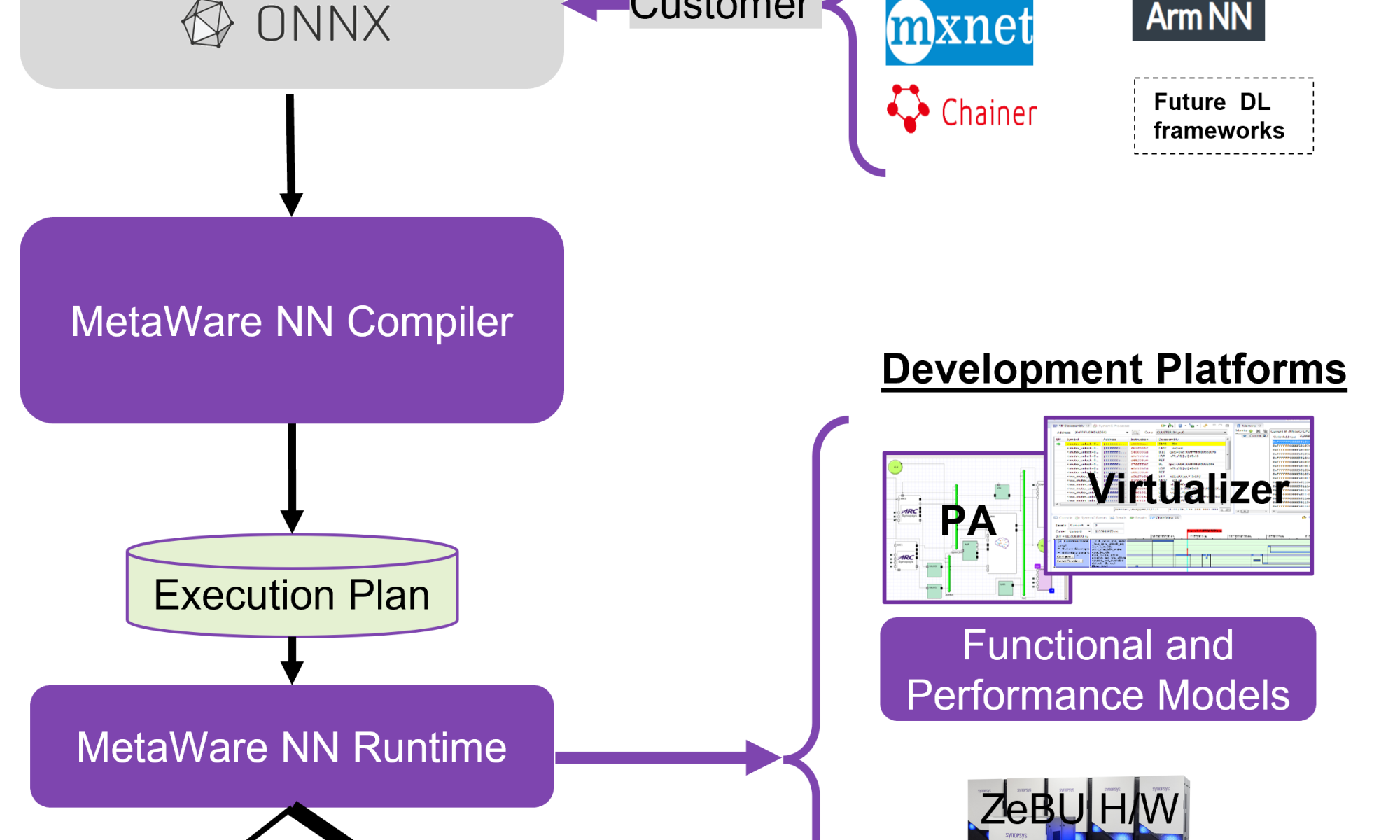
Synopsys’ broad processor portfolio includes both its ARC® VPX vector DSP family of cores as well as its ARC NPX neural network family of cores. The development platform comes with the ARC MetaWare MX development tools. The VPX cores are programmable using C or C++ while the NPX cores’ hardware is automatically generated by feeding the customer’s trained neural network into Synopsys development tools. The platform supports widely used frameworks for customers to train their neural network. The MetaWare NN SDK is the compiler for the trained NN. The development tools also offer the ability to perform virtual simulation for testing purposes.

ARC NPX6 is Synopsys’ sixth generation general purpose NPU that will support any CNN, RNN or transformer. Customers who bring their own AI engine can easily pair it with a VPX core. Customers could also design their own neural network using Synopsys’ ASIP Designer tool.
As applications’ demand for TOPS performance grows, the challenge of memory bandwidth grows with it. Some hardware and software features need to be added to minimize this bandwidth challenge. To address this scaling requirement, Synopsys uses L2 memory to help minimize data traffic over an external bus.
An ARC NPX6-based solution can be implemented to deliver up to 3,500 TOPS as needed by scaling all the way to 24 core NPU with 96K MACs and instantiating up to eight NPUs.


Summary
Combining vector DSP technology and neural processing technology can create a synergistic solution that includes future-proofing and can revolutionize AI acceleration. Synopsys offers a broad portfolio of IP in addition to the VPX and NPX family of IP cores. They also offer other tools such as platform architect tool that will help explore, analyze and visualize the data of the AI applications. High quality IP and a comprehensive, easy-to-use tool platform are needed for achieving fast time to market.
For more details, visit the product page.
Also Read:
VC Formal Enabled QED Proofs on a RISC-V Core
WEBINAR: Leap Ahead of the Competition with AI-Driven EDA Technology
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.