
We are all pretty familiar with augmented reality, where real world images are overlaid with computer generated images, graphics and even audio. Of course, our first exposure to augmented reality might have been images of heads up displays in fighter jets or perhaps in the movie The Terminator. Augmented reality is moving rapidly towards mobile devices, handhelds and also automotive applications. Developing augmented reality systems on these new platforms requires crucial decisions about the image processing implementation.
For system level and embedded processing vision, we have several choices, which include GPUs, FPGAs, vision DSPs, or vision DSPs combined with neural networks. The considerations include cost, energy efficiency and performance.
At Embedded World 2019 Synopsys presented a paper on implementing augmented reality in low-power systems. The presenter was Gordon Cooper, product marketing manager for processor IP at Synopsys. One focus of his presentation was simultaneous localization and mapping(SLAM), which is the technique used to determine the actual 3-D location of objects relative to the camera. To do this in real-time a 3-D model of the environment must be produced and the location of the camera must be determined. Often a two-camera technique is used which relies on stereoscopic vision to determine distances. However, many new systems only have a single camera, so techniques are needed to determine distance using monocular SLAM.
Using a single camera requires more complicated algorithms. Depth cannot be directly inferred from a single image because it can be difficult to determine absolute scale. So, Synopsys asks the question as to whether neural networks can be used to improve depth maps for monocular SLAM. They found that this has been studied and can be an attractive approach, as shown in the paper titled Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture, by David Eigen, Rob Fergus, 2015. This paper shows that with just a two-dimensional RGB image it was possible to output a depth map as well as determine the surface normals.
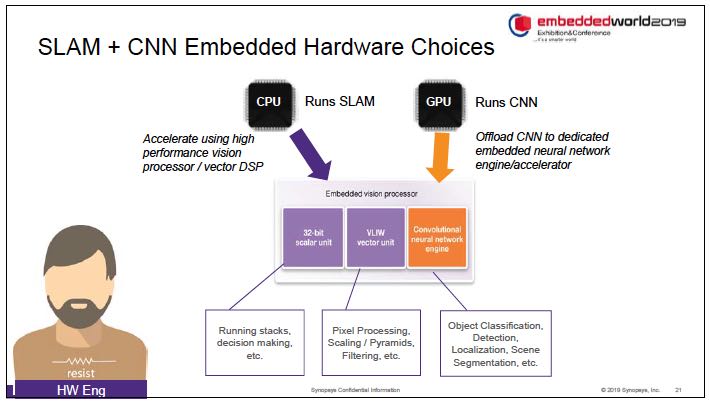
For real time processing, frame rates of above 25 frames per second are necessary. This means that just 30 to 40ms of total processing time is available to avoid significant latency. Coming back to the question of implementation, it is clear that GPUs can be useful for running neural networks, but they may consume too much power for automotive applications. CPUs may be able to perform SLAM but again there’s the question of performance, power and area. Synopsys’ solution is to combine these functions into a single embedded processor which contains a 32 bit scalar unit, a vector unit and a neural network engine.
Software is the other important element of the complete solution. The software must perform feature extraction and feature matching between frames to determine camera motion. Additionally, there must be support for a variety of different neural network types. Synopsys offers its OpenVX framework which includes C/C++, OpenCL C, OpenCV, OpenVX libraries, and CNN mapping tools. With this their customers can develop user applications that address their specific requirements.
Synopsys also supports a number of optimizations including feature map compression in hardware, which offers runtime compression and decompression, use of simplified Huffman encoding, and CNN DMA with a hardware compression mode. In addition, there is coefficient pruning, where coefficients with zero value are skipped/counted, leading to dramatic reductions in the number of required operations.
Synopsys believes that properly implemented vision processors that include neural networks can help improve SLAM accuracy in determining depth perception and scaling. At the same time these vision processors can help improve performance and lower power consumption, which will be needed in many of its applications. Although we do not necessarily see augmented reality used on a day to day basis yet, it will probably be one of those things that gathers momentum and will soon become something that we rely on for numerous daily activities, such as driving, learning new skills or appreciating the world around us. More information on Synopsys vision processing solutions for SLAM and CNN can be found on their website.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.