

Deep learning, modeled (loosely) on the way living neurons interact, has achieved amazing success in automating recognition tasks, from recognizing images more accurately in some cases than we or even experts can, to recognizing speech and written text. The engineering behind this technology revolution continues to advance at a blistering pace, so much so that there are now bidding wars between the giants (Google, FB, Amazon, Microsoft et al) for AI experts commanding superstar paychecks.
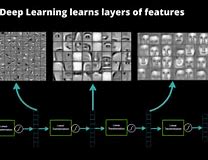
It might seem surprising then that we don’t really have a deep understanding of how deep learning works. I’m not talking about what you might call a mechanical understanding of neural nets; that we have down pretty well and we continue to improve through more hidden layers and techniques like sharpening and pooling. We understand how layers recognize features and how together these ultimately lead to recognition of objects. But we don’t have a good understanding of how recognition evolves in training and why ultimately it works as well as it does.
On reflection, this should not be surprising. Whenever technology advances rapidly, theory lags behind and catches up only as technology advances moderate. Some might wonder why we even need theory. We need it because all sustainable major advances eventually need a solid basis of theory if they are to have predictive power. Without that power, figuring out how to build even better solutions and knowing where the limits lie would all depend on trial and error, quickly becoming prohibitively expensive and undependable. Theoretical predictions still have to be tested (and adjusted) in practice but at least you know where to start.
Naftali Tishby of the Hebrew University of Jerusalem has developed an information theory of deep learning as a contribution to this domain, which seems like a pretty reasonable place to start. He makes the point that classical information theory is concerned only with accurate communication without an understanding of the semantics of what is communicated, whereas deep learning is all about the semantics (is this a dog or not a dog?). So an effective theory for deep learning, while following somewhat similar lines to Shannon’s theory, needs to look at loss of “relevant” information rather than loss of any information.
The theory details get quite technical, but what is more immediately accessible are implications for how deep learning evolves, especially as exposed by this team’s work in studying many training experiments on a variety of networks. They mapped the current state of their information metric by planes in a network and looked at how this evolves by epoch (a complete pass through the training data; multiple passes are typically made until error rate is acceptable). Before the first epoch there is high information in the first (labeled) layer and very little in final layers.
As epochs proceed, information with respect to labelling rises rapidly by layer (fitting), until this reaches a transition. At this transition, the network has minimized error in classifying the training examples seen so far, but the interesting part happens in subsequent training. Here detection accuracy does not improve but the number of bits in their input information metric (by plane) begin to drop. Tishby calls this compression; in effect, layers in the network are starting to drop information which is not relevant to the recognition problem. Put another way, during this phase, the network is learning to generalize, ignoring features in training examples which are not relevant to the object of interest.
The theory promises value not only in understanding this evolution but also being able to quantify the value of hidden layers in accelerating the compression phase, also bounds on accuracy, both of which are important in understanding how far this technique can be pushed and into what domains.
This is obviously not the last word on theory for deep learning (explaining unsupervised learning, for example) but is seems like an interesting start. A number of other researchers of note find this work at minimum intriguing and quite possibly an important breakthrough. Others are not so sure. In any case, it is by efforts like this that deeper understanding progresses, and we can certainly use more of that in this field. You can read more on this topic in this Wired article.
Share this post via:



TSMC CoWoS versus Intel EMIB Semiconductor Packaging