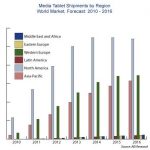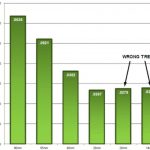
Thisblog with a chart showing that the cost of given functionality on a chip is no longer going to fall is, I think, one of the most-read I’ve ever written on Semiwiki. It is actually derived from data nVidia presented about TSMC, so at some level perhaps it is two alpha males circling each other preparing for a fight. Or, in this case, wafer price negotiations.
However, I also attended the litho morning at Semicon West last week, along with a lot more people than there were chairs (I was smart enough to get there early). I learned a huge amount. But nobody really disputed the fact that double and triple patterning make wafers a lot more expensive than when we only need to use single patterning (28nm and above). The alternatives were 3 new technologies (or perhaps a combination). Extreme ultra-violet lithography, direct write e-beam and directed self assembly. EUV, DWEB or DSA. Pick your acronym.
I wrote about all of them in more detail. Here are links. Collect the whole set.
- Overview of future lithography
- Direct write e-beam
- Extreme ultra-violet (EUV)
- EUV masks
- Lack of a pellicle on EUV masks
- Directed self-assembly
I talked to Gary Smith who had been at an ITRS meeting. He says ITRS are not worried and that they think 450mm (18″) wafers will solve all the cost issues. I haven’t seen any information about the expected cost differences between 300mm and 450mm but for sure it is not negligible. Twice as many die for how much more per wafer? A lot of 450nm equipment needs to be created and purchased too, although presumably in most cases you only need half as much of it for the same number of die.
Gary also had lunch with the ITRS litho people and they still see EUV as the future. After listening to these presentations I’m not so sure. The issue everyone is focused on (see what I did there?) is the lack of a powerful light source for EUV. But the mask blank defect issue and the lack of a pellicle defect issue also look like killer problems.
Maybe I shouldn’t worry. After all, all these people know way more than I do about lithography. I’m a programmer by background, after all.
But I was at the common platform technology forum in March and Lars Liebmann of IBM said: “I worked on X-ray lithography for years and EUV is not as far along as X-ray lithography was when we finally discovered it wasn’t going to work.”
Now that’s scary.
The reason this is so important is that Moore’s law is not really about the number of transistors on a chip, it is about the cost of electronic functionality dropping. If the graph above turns out to be true, it means a million gates will never get any cheaper. That means an iPad is as cheap as it will ever be. An iPhone is never going to just cost $20. We will never have cell-phones that are so cheap that like calculators we can give them away. Yes, we may have new sexy electronic devices. But the cost of the product at introduction is the cost that it will always be. It won’t come down in price if we just wait, as we’ve become used to. Electronics will become like detergent, the same price year after year.