If you ask to IP vendors selling functions, PHY or Controller, supporting Interface based protocols which part is the master piece, the controller IP only vendors will answer: certainly my digital block, look how complex it has to be to support the transport and logical part of the protocol! Just think about the PCI Express gen-3 specification, counting over 1000 pages… Obviously, the PHY IP vendor will claim to procure the essential piece: if the PHY does not work 100% according with the specification, nothing works! Now, would you ask me to answer this question, I will reply… by a question: do you know anything about the rare earth element case?
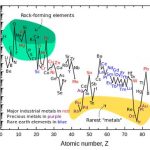
Rare earth metals are a set of seventeen chemical elements in the periodic table, specifically the fifteen lanthanides plus scandium and yttrium, which are used, even in very tiny amount, in almost every electronic systems, and most certainly in advanced systems, from iPhone to catalytic converters, from energy efficient lighting to weapons systems, and many more. To make a long story short, for short term consideration (I mean stock market dictated view, where the long term is the end of the fiscal year), rare earth extraction and sales are at 95% concentrated into a single country, when every high tech industry need to access it.
Hopefully, nothing similar has happened with the PHY, except that it’s an essential piece of modern semiconductor industry, and like CPU or DSP IP core, and that you find it in most of the ASIC and ASSP, providing the chip has to communicate through a protocol (PCIe, MIPI, USB, SATA, HDMI, etc.) or address an external DRAM at data rate over 1 Gb/s. By the way, I have answered your question: to me, the PHY IP is the master piece of the protocol based function. Developing high speed digital controller certainly require talented design architect, able to read and really understand the protocol specification, then to manage a digital design team implementing the function, and interfacing with a Verification team in charge of running the VIP to check for protocol compliance. But at the end, if the design team was mediocre, the IP will probably still work at spec, even if the latency could be too long, or the area or the power larger than what was optimally possible to reach.
Because PHY design is still heavily based on mixed-signal design techniques, developing first time right function is a much more challenging task requiring highly experienced designers. Would you follow a mediocre design approach, this will lead to failing result: there are simply too many reasons why a design could fail. So, creating a PHY design team requires to find highly specialized design engineers, the type of engineers starting to do a decent job after five or ten years of practice, and being good after fifteen or twenty years’ experience! This is the reason why, even if you look all around the world, you will only find a handful (maybe two if you take into account the chip makers) of PHY design capable teams. That’s why I am happy to welcome Silab Tech, one of these talented PHY IP vendors!
The PHY IP market, during the last couple of years, has consolidated:
- Synopsys has acquired in 2012 MoSys PHY IP division (former Prism Circuit bought by MoSys in 2009),
- Gennum (parent company of Snowbush, well known PHY IP vendor) was acquired by Semtech at the end of 2011 and the company decided to keep Snowbush PHY for their internal use, or to address very niche market.
- VSemiconductor was developing Very High Speed PHY (up to 28 Gbps) for Intel foundry, finally Intel decided that it was even easier to buy the company, at the end of 2012.
- Very recently, Cadence bought Cosmic Circuits, another mixed-signal IP vendor also selling MIPI and USB 3.0 PHY.
Consolidation is the mark for mature market, but the PHY part of the Interface IP market still has a strong growth potential: the overall (PHY and Controller) IP market has weighted $300M in 2012, but it should pass $500M in 2016. Moreover, if the Interface IP market revenue sharing was 50/50 in 2008 between PHY and Controller in value, the PHY IP share has been above 60% in 2012 and the trend will go on this way! Welcoming a new PHY IP vendor is certainly good news for chip makers, a diversified offer allowing better flexibility, offering more design options when selecting optimum technology node for a specific circuit.
As I mentioned earlier in this paper, to start a successful PHY and analog IP vendor, you need to rely on a strong, talented and experienced design team. As we can see on the above chart, Silab Tech founders have acquired most of their experience when working for TI. TI is known to be an excellent company to develop engineering competency, it is also a company where technical knowledge is valued at the same level than managerial. When, in many companies, the only way to progress is to become a manager, a good technical engineer can get the same level of reward than a good manager when working for TI. That’s the reason why Silab Tech’s management team exhibit various domain of expertize like PLL, DPLL, High Speed serial interface or ESD…
By the way, these are precisely the area of expertize you need to develop high speed PHY IP, like this you can see in the picture labeled “PHY: 2 lanes example”, extracted from a Silab Tech test chip recently taped out. To create an efficient PHY IP design team, the managers need to rely on a strong experience, but this is also true for the design engineers, and this is the case with Silab Tech, where most of the engineers have long analog design background, similar to the management team. No doubt that Silab Tech name will become very popular for the chip makers involved in large SoC design, like was Snowbush in the early 2010’s. But the difference with Silab Tech is that they are in the IP business to stay, develop the company and serve their customers.
By Eric Esteve from IPnest