“Most interior paint covers with one coat.” Back when there was something called a newspaper, this was an actual blurb in the home improvement pages, section 3, part 8, page 5 of the Chicago Tribune on Sunday, August 13, 1961. Even then, marketers were catering to consumers looking to cut corners and save time, and one-coat coverage was a popular claim among pigment providers. The column filler went on to say yellow and pink have low covering power, and may need a primer. Let’s face it, pretty much nothing covers dark green in a single application.
I suspect most SoC verification teams don’t trust that claim any more than they trust code coverage tools. To counter the lack of confidence, teams usually keep applying coats of testing until they see a functional coverage metric asymptotically approaching 100%. There is no arguing with 100%, right? Nobody gets away with walking into a meeting and saying we’re good, coverage is at 85%. The effort to get to 100% is usually accepted – expected, in fact.
Cutting corners on painting can be somewhat hazardous. One risks the scornful review of a significant other, who visually inspects the work on two dimensions: “you missed a spot”, and how much of a mess was made in the process. Too little paint is bad; leftover paint is a bonus for future maintenance. The actual amount of paint used, and the number of brushes or rollers chewed up, is rarely a consideration if the budget was met and the aesthetic outcome is right.
Cutting corners on verification can be deadly. However, verification differs from house painting in one important way: different tests deliver varying amounts of effectiveness and coverage. A difficult-to-cover dark green spot in an SoC design may require a focused verification routine. Wider swaths of HDL may be covered more easily and quickly.
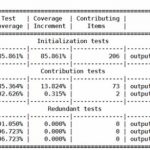
The question for SoC verification becomes how to provide the greatest code coverage in the least amount of time and effort. Some tests may prove better than others, and some tests may prove to be completely redundant adding no value. Most verification tools only report on the final result – coverage. Teams may be trying to fill in coverage and expending significant resources on duplicative or ineffective tests, and never know it.
Aldec has released Riviera-PRO 2015.02 with a major new feature: test ranking. By looking at how tests contribute to coverage, comparisons become easy to spot. Teams can put more energy into higher ranked tests, and less into tests that are redundant or produce poor contributions.
There is also a cost factor to the ranking. Parameters can include how much simulation time is required; where two tests provide equivalent coverage, the faster one should be chosen. A longer test may be worth the CPU cycles if it provides substantially better coverage than alternatives.
Test ranking provides a unique and valuable view of the verification process. Aldec continues to expand Riviera-PRO, combining simulation, debug, and reporting into a single productivity tool for advanced verification.
Related articles: