By 2020, the Internet of Things (IoT) is predicted to generate an additional $344B in revenues, as well as to drive $177B in cost reductions. IoT and smart devices are already increasing performance metrics of major US-based factories. They are in the hands of employees, covering routine management issues and boosting their productivity by 40-60% [1].
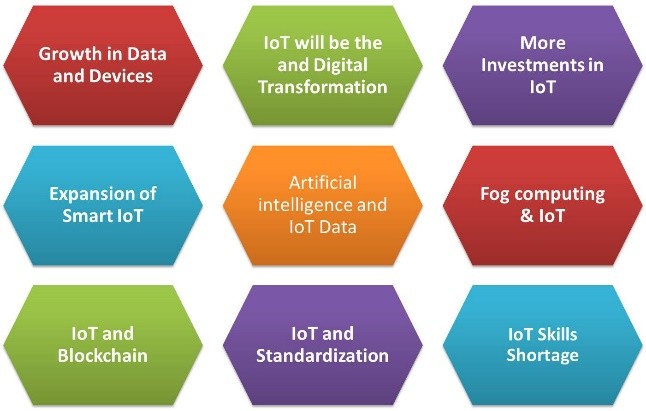
The following list of predictions (Figure 1) explores the state of IoT in 2019 and covering IoT impact on many aspects business and technology including Digital Transformation, Blockchain, AI, and 5G.
Figure 1: IoT Predictions For 2019
IoT Prediction 1: Growth in Data and Devices
By the end of this year there will be are around 3.6 billion devices that are actively connected to the Internet and used for daily tasks according to IT Pro [8]. With the introduction of 5G that will open the door for more devices, and data traffic. You can add to this trend the increase adoption of edge computing which will make it easier for business to process data faster and close to the points of action [5].
IoT Prediction 2: IoT and Digital Transformation
IoT is a key driver of digital transformation in several industries. Sensors, RFID tags, and smart beacons have already started the next industrial revolution. Market analysts predict the number of connected devices in the manufacturing industry will double between 2018 and 2020.
These devices are a total game changer for the many industries, disrupting every part of the production process from development to supply chain management. Manufacturers will be able to prevent delays, improve production performance. Another example; in 2019; 87% of healthcare organizations will have adopted IoT technology. The possibilities are endless for healthcare organizations and the IoT—smart pills, smart home care, personal healthcare management, electronic health records, managing sensitive data, and an overall higher degree of patient care. This type of improvements can be applied to many sectors vertically and horizontally [6][9].
IoT Prediction 3: More Investments in IoT
IoT’s undisputable impact has and will continue to lure more startup venture capitalists towards highly innovative projects in hardware, software and services. Spending on IoT will hit 1.4 trillion dollars by 2021 according to the International Data Corporation (IDC) [7].
IoT is one of the few markets that have the interest of the emerging as well as the traditional venture capitalists. The spread of smart devices and the increase dependency of customers to do many of their daily tasks using them, will add to the excitement of investing in IoT startups. Customers will be waiting for the next big innovation in IoT—such as smart mirrors that will analysis your face and call your doctor if you look sick, smart ATM machine that will incorporate smart security cameras, smart forks that will tell you how to eat and what to eat, and smart beds that will turn off the lights when everyone is sleeping [5][14].
IoT Prediction 4: Expansion of Smart IoT
IoT is all about connectivity and processing, nothing will be a better example than smart cities , but smart cities have been in a bit of a holding pattern recently. Smart sensors around the neighborhood will record everything from walking routes, shared car use, building occupancy, sewage flow, and temperature choice 24/7 with the goal of creating a place that’s comfortable, convenient, safe, and clean for those who live there. Once the model is perfected, it could be the model for other smart neighborhoods and eventually smart cities [2].
Another area of spreading smart IoT is auto industry with self-driving cars become a normal occurrence in the next few years, today tons of vehicles have a connected app that shows up to date diagnostic information about the car. This is done with IoT technology, which is the heart of the connected vehicle. Diagnostic information is not the only IoT advancement that we will see in the next year or so. Connected apps, voice search, and current traffic information are a few other things that will change the way we drive [2].
IoT Prediction 5: Artificial Intelligence and IoT Data
Artificial intelligence is the fundamental ingredient needed to make sense of the vast amount of data collected these days, and increase its value for business. AI will help IoT data analysis in the following areas: data preparation, data discovery, visualization of streaming data, time series accuracy of data, predictive and advance analytics,andreal-time geospatial and location (logistical data). Here are a few examples.
- Data Preparation: Defining pools of data and cleaning them, which will take us to concepts like Dark Data and Data Lakes.
- Data Discovery: Finding useful data in defined pools of data.
- Visualization of Streaming Data: On-the-fly dealing with streaming data by defining, discovering data, and visualizing it in smart ways to make it easy for the decision-making process to take place without delay.
- Time Series Accuracy of Data: Keeping the level of confidence in data collected high with high accuracy and integrity of data
- Predictive and Advance Analytics: Making decisions based on data collected, discovered and analyzed.
- Real-Time Geospatial and Location (Logistical Data): Maintaining the flow of data smoothly and under control [3].
IoT Prediction 6: Fog Computing & IoT
Fog computing is a technology that distributed the load of processing and moved it closer to the edge of the network (sensors in case of IoT). The benefits of using fog computing are very attractive to IoT solution providers. Some of these benefits allow users minimize latency, conserve network bandwidth, operate reliably with quick decisions, collect and secure a wide range of data, and move data to the best place for processing with better analysis and insights of local data. Microsoft just announced a $5 billion investment in IoT, including fog/edge computing [3][4][5].
Hardware manufacturers like Cisco, HPE, Dell and more are building specific infrastructure for the edge deigned to be more physically rugged and secure, and security vendors will start to offer endpoint security solutions to their existing services to prevent data loss, give insights into network health and threat protection, include privileged user control and application whitelisting and control, that will help in the fast adoption and spread of edge/fog computing implementations by businesses [2].
IoT Prediction 7: IoT and Blockchain
The current centralized architecture of IoT is one of the main reasons for the vulnerability of IoT networks. With billions of devices connected and more to be added, IoT is a big target for cyber-attacks, which makes security extremely important.
Blockchain offers new hope for IoT security for several reasons. First, blockchain is public, everyone participating in the network of nodes of the blockchain network can see the blocks and the transactions stored and approves them, although users can still have private keys to control transactions. Second, blockchain is decentralized, so there is no single authority that can approve the transactions eliminating Single Point of Failure (SPOF) weakness. Third and most importantly, it’s secure—the database can only be extended and previous records cannot be changed.
In the coming years manufactures will recognize the benefits of having blockchain technology embedded in all devices and compete for labels like “Blockchain Certified”[3][5].
IoT Prediction 8: IoT and Standardization
Standardization is one of the biggest challenges facing growth of IoT—it’s a battle among industry leaders who would like to dominate the market at an early stage. Digital assistant devices, including HomePod, Alexa, and Google Assistant, are the future hubs for the next phase of smart devices, and companies are trying to establish “their hubs” with consumers, to make it easier for them to keep adding devices with less struggle and no frustrations [3][5].
But what we have now is a case of fragmentation. One possible solution is to have a limited number of vendors dominating the market, allowing customers to select one and stick to it for any additional connected devices, similar to the case of operating systems we have now have with Windows, Mac and Linux for example, where there are no cross-platform standards [3][5].
To understand the difficulty of standardization, we need to deal with all three categories in the standardization process: Platform, Connectivity, and Applications. In the case of platform, we deal with UX/UI and analytic tools, while connectivity deals with customer’s contact points with devices, and last, applications are the home of the applications which control, collect and analyze data. All three categories are inter-related and we need them all, missing one will break that model and stall the standardization process [3][5].
There is no way to solve the problem of fragmentation without a strong push by organizations like IEEE or government regulations to have common standards for IoT devices [3][5].
IoT Prediction 9: IoT Skills Shortage
While investment in the Internet of Things (IoT) is set to reach over $1 trillion by 2020, according to IDC, the need for IoT skills may just hamper this growth. In fact, according to a Canonical report, 68% of businesses still struggle to hire IoT experts [10]. The latest Tech Cities Job Watch report from Experis showed a 35% increase in the demand for technology skills since this time last year, as businesses look to harness the power of IoT [11][13].
The Tech Cities Job Watch report noted that IoT has massively increased the number of connected devices and has exploded the volumes of data businesses have to process and as a result, big data roles are important to delivering success on IoT. The report found that businesses were willing to pay for such skills, with big data professionals commanding by far the highest salaries and day rates of any other technology discipline analyzed [13].
Since connected devices also create many more vulnerabilities to cyber threats for businesses to contend with, security skills are also in demand, the report found. There has been a 24% increase (year-on-year) in the demand for IT Security contractors. Businesses are urgently plugging short term security gaps and using contractors to train up existing employees across the business and are shifting focus to this more flexible contractor model for IT security in response to the demands for IoT [13].
Universities cannot keep up with the demand, so to deal with such shortage, companies have established internal training programs to build their own teams, upgrading the skills of their own engineering teams and training new talents. This trend will continue, representing an opportunity for new engineers and a challenge for companies [3][5].
References
[LIST=1]
https://mobidev.biz/blog/iot-trends-for-business-2018-and-beyond
https://www.forbes.com/sites/danielnewman/2018/07/31/five-iot-predictions-for-2019/#5a73cf186edd
https://www.linkedin.com/pulse/looking-ahead-whats-next-iot-ahmed-banafa/
https://blogs.wsj.com/cio/2018/04/05/it-execs-see-promise-in-iot-reinforcing-microsofts-5b-investment/
https://www.amazon.com/Secure-Smart-Internet-Things-Iot/dp/8770220301/
https://www.i-scoop.eu/internet-of-things-guide/internet-things-healthcare/
https://www.roboticsbusinessreview.com/manufacturing/an-introduction-to-the-internet-of-things/
https://www.itproportal.com/features/next-big-things-in-iot-predictions-for-2020/
https://www.linkedin.com/pulse/iot-ai-blockchain-catalysts-digital-transformation-ahmed-banafa/
https://blog.ubuntu.com/2017/08/09/68-of-businesses-are-struggling-to-hire-talent-for-iot?_ga=2.150705918.931132101.1502305379-1356650044.1502305379
http://techcities.experis.co.uk/?utm_source=exp_insights&utm_medium=website&utm_term=none&utm_content=q42017&utm_campaign=techcities
https://www.forbes.com/sites/forbestechcouncil/2018/08/23/so-you-want-a-job-in-iot-here-are-the-three-skills-every-iot-company-looks-for/#14a1f97c45b7
https://www.idgconnect.com/idgconnect/analysis-review/1003535/talent-shortage-hampering-iot-development
https://www.linkedin.com/pulse/8-trends-iot-2018-ahmed-banafa/
This article appeared first on IEEE-IoT : https://iot.ieee.org/newsletter/november-2018/nine-iot-predictions-for-2019
Ahmed Banafa, Author the Book: Secure and Smart Internet of Things (IoT) Using Blockchain and AI
Read more articles at IoT Trends by Ahmed Banafa