
NVIDIA designs some of the most complex chips for GPU and AI applications these days, with SoCs exceeding 21 billion transistors. They certainly know how to push the limits of all EDA tools, and they have a strong motivation to automate more manual tasks in order to quicken their time to market. I missed their Designer/IP Track Poster Session at DAC titled, Machine Learning based Timing Arc Prediction for AMS Design, but the good news is that I did attend a webinar from Empyrean that covered the same topic. Anjui Shey from Empyrean was the webinar presenter and he talked about Qualib-AI, an EDA tool with AI-powered timing arc prediction for AMS IP blocks.
First off, let’s look at some of the AMS IP modeling challenges:
- Complex IP creates higher design risks
- Difficulty modeling AMS IP
- A missed timing arc can lead to chip failure
- Toggling within an IP changes thermal condition and timing
- Process variation creates a large number of PVT corners
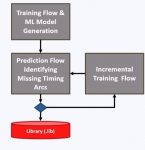
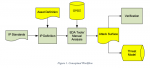
Empyrean updated their Qualib library analysis and validation tool to use ML, creating the Qualib-AI tool as shown below:
A timing arc is where you define a timing dependence between any two pins of an IP block. CAD groups are tasked with adding timing arc information for each IP block, and for AMS designs this has been a time consuming manual effort that is error prone.
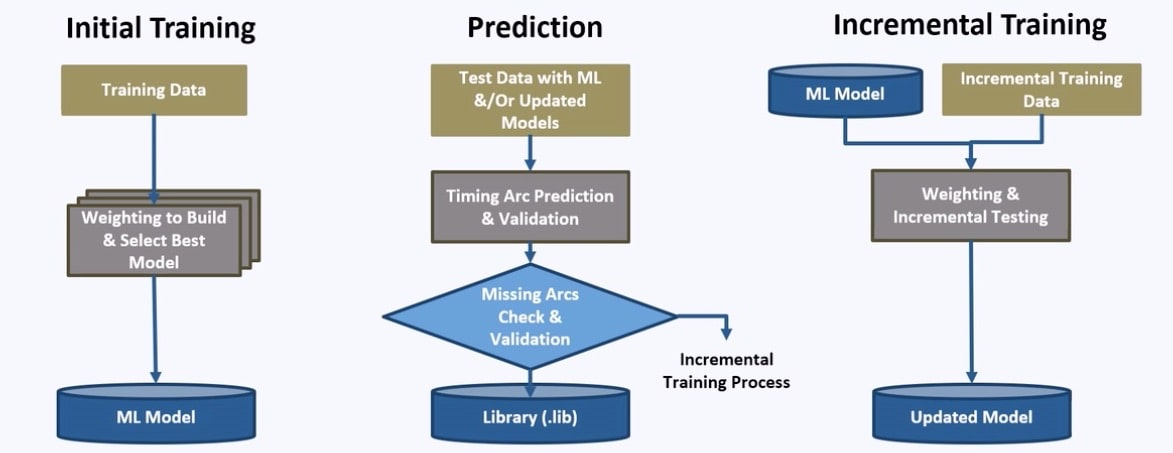
There are three flows used in this methodology for timing arc prediction: Initial Training, Prediction, Incremental Training.
The training data comes from previous AMS cell libraries. Benefits to using ML for predicting timing arcs include:
- Higher coverage of predicted timing arcs
- Better accuracy for timing type predictions
- Fewer false positives and negatives, saving time
NVIDIA ran initial training on 411 IP blocks and then used prediction on a set of 30 new IP blocks as shown below, automatically finding 6,774 arcs and identifying 15,124,093 non-arcs:
The CPU runtimes for initial and increment training plus prediction were pretty fast at about one hour, a much shorter amount of time had the engineers done manual timing arcs:
With an incremental training flow there were three improvements in predicting the timing arcs:
- Number of false positives decreased 9x, number of false negatives decreased 40X
- Reached 99.6% coverage to predict timing arc with timing type
- Reached 98.96% accuracy to predict the timing type
After incremental training there were fewer than 100 false positives for the engineers to review, which is a manageable amount compared to previous efforts.
Summary
Engineers creating AMS IP blocks can now automate how timing arcs are created, saving them time and reducing the risk of a silicon re-spin. Libraries of AMS blocks can be run through this flow to uncover missing arcs, thus improving the quality of the library. The number of false positives has been decreased greatly, and run times for this approach are acceptable.
Watch the archived webinar video here.
Related Blogs




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}