
I generally like to start my blogs with an application-centric viewpoint; what end-application is going to become faster, lower power or whatever because of this innovation? But sometimes an announcement defies such an easy classification because it is broadly useful. That’s the case for a recent release from Quadric, based on an architecture which seems to carve out a new approach to acceleration. This is able to serve a wide range of applications, from signal processing to GenAI with depth in performance, up to 864 TOPs per their announcement.

The core technology
Quadric’s roots are in AI acceleration, so let’s start there. By now we are all familiar with the basic needs for AI processing: a scalar engine to handle regular calculations, a vector engine to handle things like dot-products, and a tensor engine to handle linear algebra. And that’s how most accelerators work – 3 dedicated engines coupled in various creative ways. The Quadric Chimera approach is a little different. The core processing element is built around a common pipeline for all instruction types. Only at the compute step does it branch to an ALU for scalar operations or a vector/matrix unit for vector/tensor operations.
Both signal processing and AI demand heavy parallelism to meet acceptable throughput rates, handled through wide-word processing, lots of MACs and multi-core implementations. The same is true for the latest Quadric architecture, but again in a slightly different way. Their new cores are built around systolic arrays of processing elements, each supporting the same common pipeline, each with its own scalar ALU, bank of MACs and local register memory.
This structure, rather than a separate accelerator for each operator class, has two implications for product developers. First it simplifies software development, still highly parallel to be sure, but abstracting out a level of complexity in multi-engine accelerator architectures where operations must be steered to the appropriate engines.
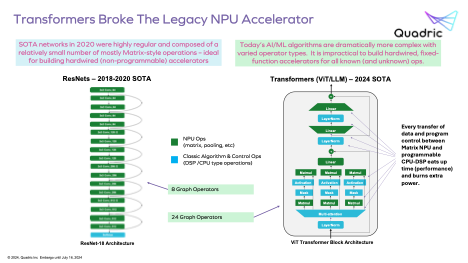
Second, the nature of parallelism in transformer-based AI models (LLMs or ViT for example) is much more complex than for earlier generation ResNet-class accelerators which process through a sequence of layers. In contrast, transformer graphs flip back and forth between matrix, vector and scalar operations. In disaggregated hardware architectures traffic flows similarly must alternate between engines with inevitable performance overhead. In the Quadric approach, any engine can handle a stream of scalar, vector and tensor operations locally. Of course there will be overhead in traffic between PE cores, but this applies to all parallel systems.
Steve Roddy (VP Marketing for Quadric) tells me that in a virtual benchmark against a mainstream competitor, Quadric’s QC-Ultra IP delivered 2X more inferences/second/TOPs for a lower off-chip DDR bandwidth and at less than half the cycles/second of the competing solution. Quadric are now offering 3 platforms for the mainstream NPU market segment: QC Nano at 1-7 TOPs, QC Perform at 4-28 TOPs, and QC Ultra at 16-128 TOPs. That high end is already good enough to meet AI PC needs. Automotive users want more, especially for SAE-3 to SAE-5 applications. For this segment Quadric is targeting their QC-Multicore solution at up to 864 TOPs.
All these platforms are supported by the proven Chimera SDK. Steve had an interesting point here also. AI accelerator ventures will commonly mention their “model zoos”. These are standard AI models adapted through tuning to run on their architectures. Like function libraries in the conventional processor space. As for those libraries, model zoo libraries must be optimized to take full advantage of their architectures. By implication a new model requires the same level of tuning, a concern for new customers who must depend on the AI developer to handle that porting for them, each time they add or refine a model.
In contrast, Steve says Quadric already hosts hundreds of models on their site which simply compile without changes onto their platforms (you can still tune quantization to meet your specific needs). It’s not a model zoo, but simply a demonstration that their SDK is already mature enough to directly map a wide class of models without modification. And he notes that if your model needs an operator outside the ONNX set they already support, you can simply define that operator in C++, just as you would for say an NVIDIA accelerator.
Applications and growth
Quadric is a young company, shipping their first IP just over a year ago. Since then, they can already boast a handful of wins, especially in automotive. Customer names of course are secret, but DENSO is an investor of record. Other customer wins are in domains that reinforce the general-purpose value of the platform, in traditional camera functions, perhaps also in femtocell basebands (for MIMO processing). These two cases may or may not need AI support, but they do heavily lean on the DSP value of the platform.
This DSP capability is itself pretty interesting. Each PE can handle a mix of scalar and vector operations – up to 32b integer or 16b float – and these can be paralleled across up to 1024 PEs in a QC Ultra. So you can serve your immediate signal processing needs with high-end DSP word widths and add transformer-grade functionality to your engine later.
Sounds like a new breed of accelerator engine to me. You can learn more HERE.
Also Read:
2024 Outlook with Steve Roddy of Quadric
Fast Path to Baby Llama BringUp at the Edge
Vision Transformers Challenge Accelerator Architectures
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.